Lecture 1 Intro
- ISA架构:指令集架构
- Microarchitecture:ISA的实现
为了实现最好的效率和表现,我们必须take the expanded view,Co-design across the hierarchy,在既定目标范围内尽可能定制化
一些定理
Amdhal Law
A formula which gives the theoretical speedup in latency of the execution of a task at fixed workload that can be expected of a system whose resources are improved.
- f:Parallelizable fraction of a program,代码的并行部分比例,1-f是串行部分
- N:并行处理器的个数
- speed up = \(\frac{1}{1-f+\frac{f}{N}}\)
最大的加速限制是\({1-f}\)
Parallel portion (f) is usually not perfectly parallel
- Synchronization overhead (e.g., updates to shared data)有overhead,共享数据的更新
- Load imbalance overhead (imperfect parallelization)
- Resource sharing overhead (contention among N processors)
Roofline Model
Theoretical performance bound of your application running on your machine.
- 计算机制:延迟有限到吞吐量有限
- 原来的面向延迟的性能模型不起作用
- 处理器方面的限制
- 在计算和内存方面显示固有的硬件限制(或限制),内存带宽等硬件限制
- 计算内核的角度
- 显示在给定处理器上运行的给定计算内核的优化优先级
Arithmetic Intensity
算力:也称为计算平台的性能上限,指的是一个计算平台倾尽全力每秒钟所能完成的浮点运算数。单位是
FLOPSorFLOP/s带宽 :也即计算平台的带宽上限,指的是一个计算平台倾尽全力每秒所能完成的内存交换量。单位是
Byte/sArithmetic Intensity = Total Flops/Total Memory Bytes
AI越大,越好,希望是读数据一次后尽量多做计算
这个值越高,读每一个bytes需要的算力越多,越可能是compute bound,低的话可能是内存bound
- Large AI :Compute-bound
- Small AI : Memory-bound
- Flops:每秒浮点运算
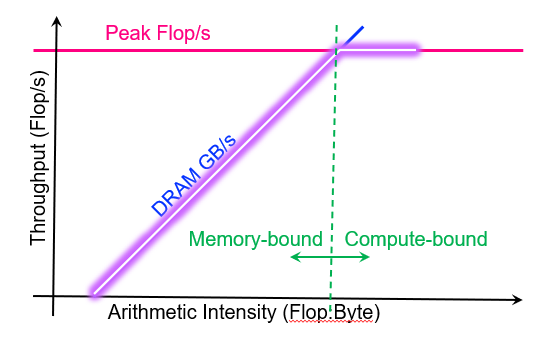
Attainable Flop/s = min( peak Flop/s, AI * peak GB/s )
这个定理告诉我们,应用的表现要在一定的bound里面,才是正常的
Peak Flop会根据计算平台变化.
Example:计算程序的AI
1 | #pragma omp parallel for |
- Type: double(8bytes)
- Memory: 24 Bytes/iteration,数组取2次,存入1次,共3次,每次8bytes
- Compute: 2 flops/iteration,浮点计算有两次
- Arithmetic Intensity: 0.083 flops/byte
1 |
|
- Type: short(2bytes)
- Memory: 16 Bytes/iteration,数组存取共8次
- Compute: 7 flops/iteration,浮点计算7次,整型计算不能计入
- Arithmetic Intensity: 0.4375 flops/byte
**Little‘s Law:L=W(buffer size = throughput*latency)**
A theorem by John Little which states that the long-term average number L of customers in a stationary system is equal to the long-term average effective arrival rate λ multiplied by the average time W that a customer spends in the system. 返回值需要时间。
- 直观的例子:只有一个窗口,Service时间6min,顾客来的速度1person/min,我们需要多少个柜台给顾客
- Answer:6 slots
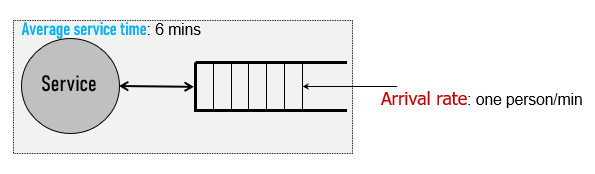
- 那么Latency就是上述中的Service
time,Throughput就是顾客来的速度,Buffersize就是我们需要的柜台数量
Buffer size = Latency * Throughput
Lecture 2 Neuman & ISA & CPU
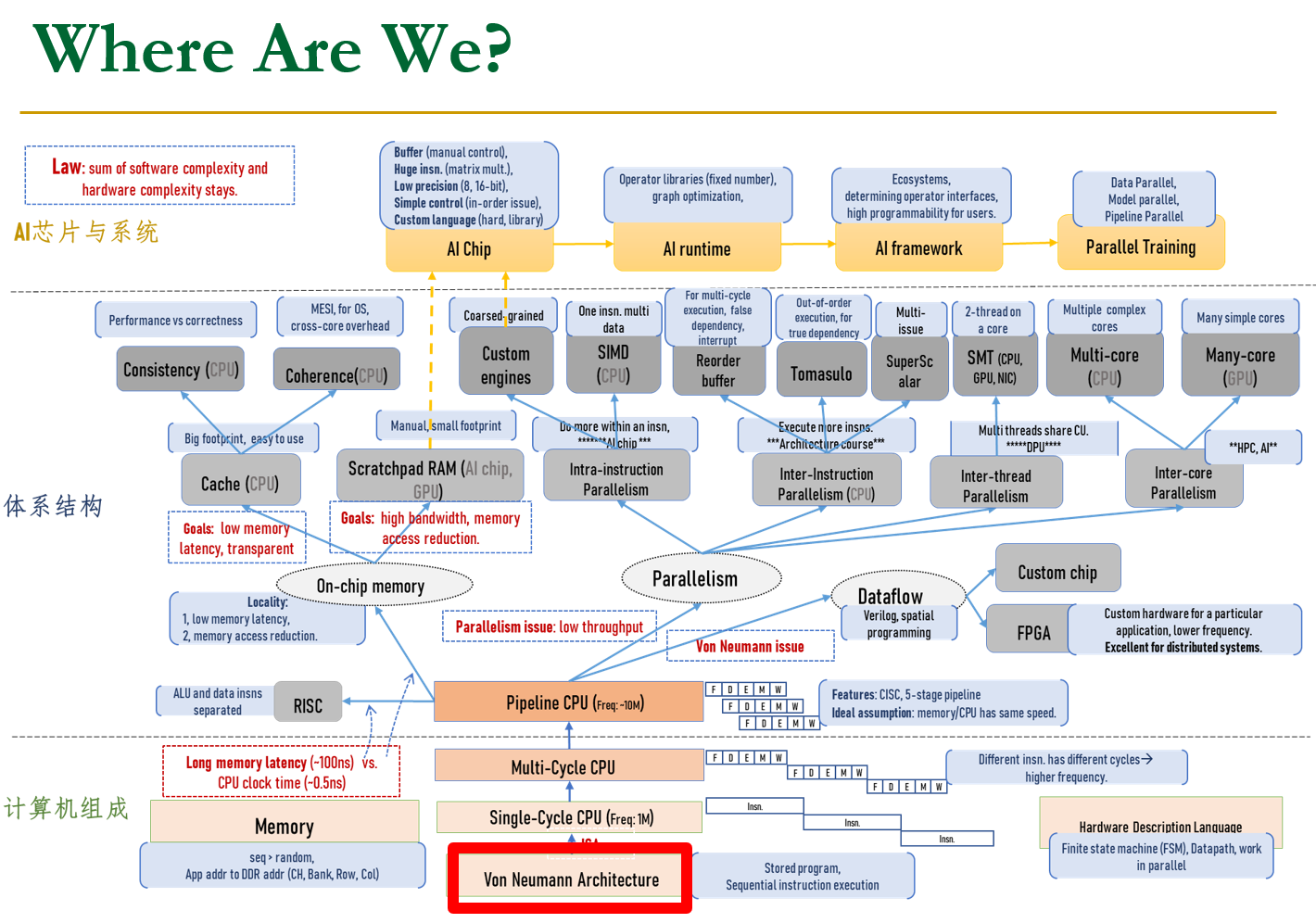
Von Neuman Model
冯诺依曼模型,是一个执行模式,为了建造一个计算机,我们需要一个执行模型这就是冯诺依曼模型。冯诺依曼结构有5个基本的组成部分。
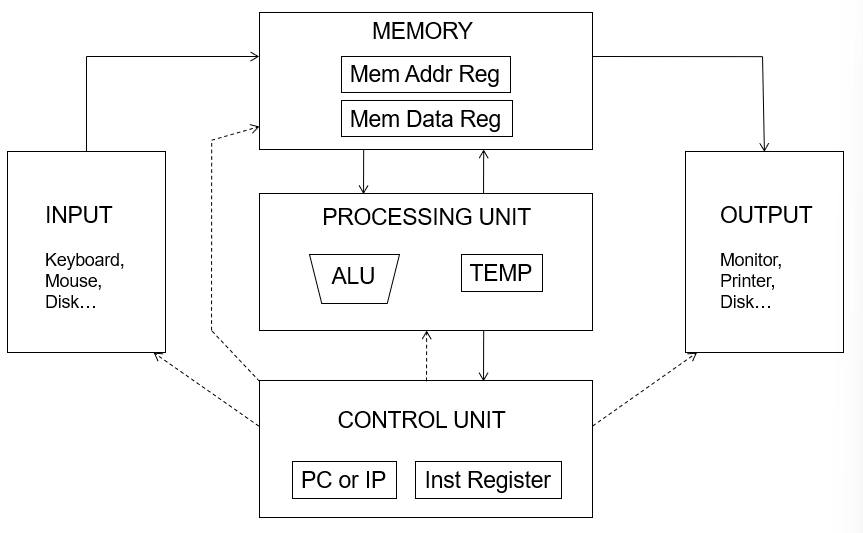
- Memory
- Processing unit
- Input
- Output
- Control unit
Memory
Memory中存储Program和Data
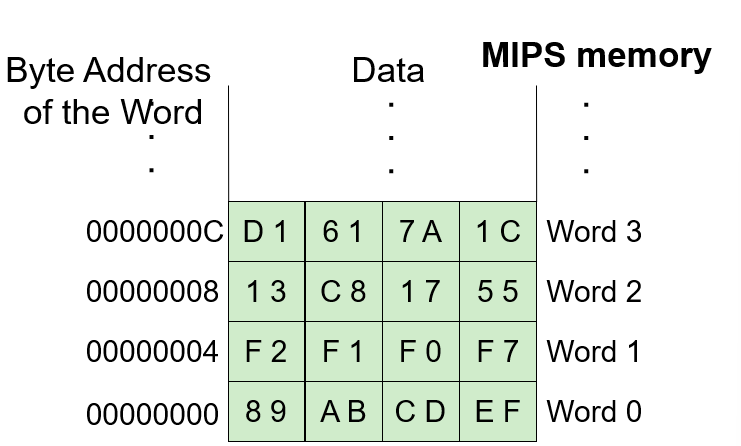
Memory contains bits:bit就是一个位,8个位组成一个byte字节,bit也可以组成word字(8,16,32bits的都有)
Address space地址空间:内存中唯一可识别位置的总数
- 在MIPS中,地址空间为32-bit的
- 在x86-64中,地址空间是48-bit的
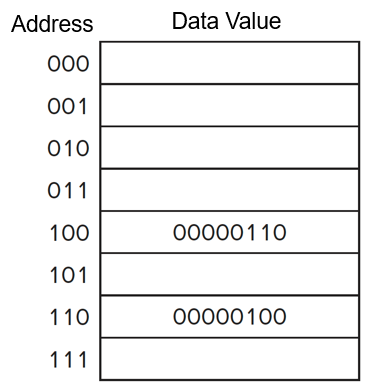
Addressability寻址能力:每个位置(地址)存储多少位
- 现在的cpu都是一个byte一个byte寻址的,即8-bit
addressable/byte-addressable
- 如这里的一个地址上是8个bit,那么这个就是byte-addressable的
- 并且其地址空间
Address space = 2^8
- 也有的是一个word一个word寻址的,但是很少有一个bit一个bit寻址的
Processing Unit(PU)
真正做计算的部分
PU由ALU和Regs组成:ALU执行计算,Regs寄存器组用来短时存储
- ALU:将各种算术和逻辑操作组合到一个单元中
- 一个周期只做一次运算
- 输入A、B以及Func信号,输出结果
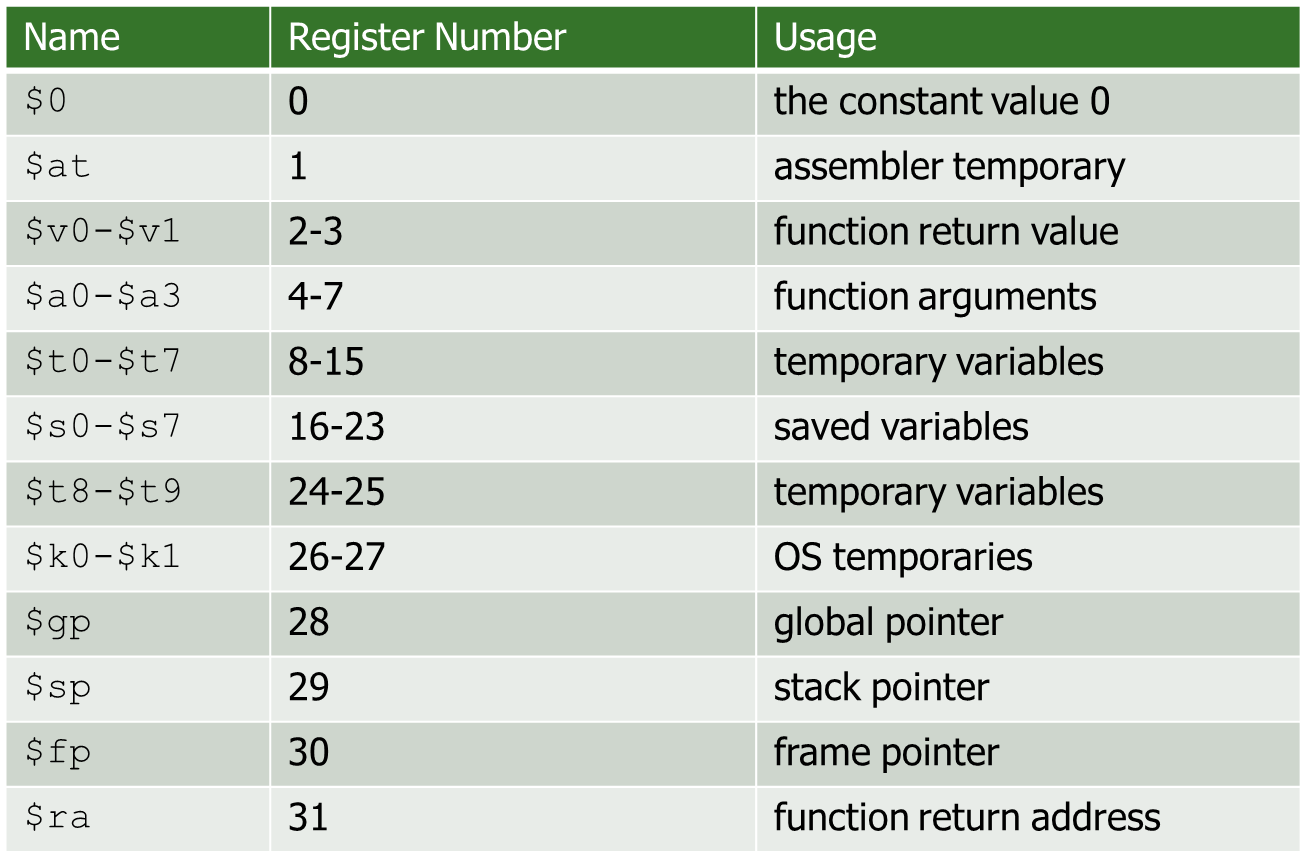
- Regs:引入寄存器的初衷是因为Memory虽然大但是很慢,在CPU中我们需要更快的存储。
- 一般来说一个Reg存放一个word
- MIPS由32个通用寄存器,
寄存器长度 = word length = 32bits - 寄存器的存放值由ABI(Application Binary Interface)规定
Input and Output
输入和输出使信息能够进出计算机。
- Input:Keyboard、Mouse、Scanner、Disks、Network…
- Output:Monitor、Printer、Disks、Network…
Control Unit
直觉:控制单元就像管弦乐队的指挥
- 执行(程序中的每条指令)的逐步过程。
- 通过包含指令的指令寄存器(IR)跟踪正在处理的指令。
- 通过程序计数器(PC)或指令指针(IP)(另一个包含要处理的(下一个)指令地址的寄存器)跟踪下一个要处理的指令。
冯诺依曼结构的最大特点:
- Stored Program
- Sequential instruction processing
Instruction Set Architecture(ISA)
我们能够直接操作的东西,就是一个指令集
直接的理解instruction set:
- Instructions are words in the language of a computer
- ISA是vocabulary
ISA是软件命令和硬件执行之间的接口。ISA是介于Program和Micoarchitecture之间的位置。
ISA规定了三个组成部分
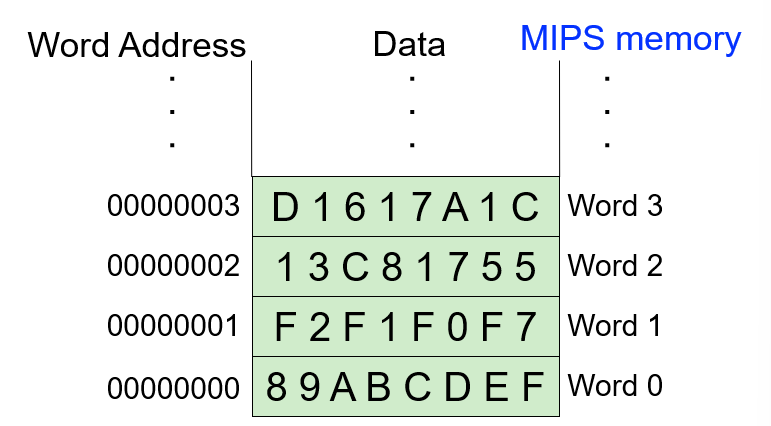
- Memory Organization
Address Space(MIPS:2^32bits)
Addressability(MIPS:8 bits)
Word- or Byte-addressable
- Register set
- MIPS:32个regs
- Instruction set
Opcodes
- Opcode:指定了指令做什么
- Operands:指定了指令的操作对象(操作数)
opcode的类型,以MIPS为例子:
- Operate:如ALU的计算
- Data movement:如Memory的Read和Write
- Control:改变操作序列,如循环、判断跳转等
Data types
早期RISC机器:只有计算整型
AIchip:能够计算tensor张量
Addressing modes
寻址模式是一种指定操作数位置的机制,在MIPS中有5种
- Immediate or literal:操作数Operand位于指令的某些位中
- Register:操作数是一个寄存器
- Three memory addressing modes
- PC-relative:和PC相关的寻址模式
- Pseudo-direct addressing:伪直接寻址
- Base+offset:Base寄存器+offset
不同的寻址模式的优点:
简洁,上层map更容易,应用容易实现,Sparse matrix accesses,支持更好地将高级编程构造映射到硬件,减少指令数量和代码大小。受益多种应用:基于指针的访问(间接)、稀疏矩阵访问、数组索引
不同的寻址模式的缺点:
在硬件层面实现困难,编译器和微架构的工作更复杂
Operate Instructions
- 以MIPS为例Add:
add a,b,c,a是目的操作数,bc是源操作数 - R-type:add、and、xor
- I-type:R-type的immediate版本
- F-type:Float的操作
DataMovement Instructions
- Motivation:需要从Memory中获取操作数,操作数需要进入reg中
- Load:从Memory到Regs
- Store:从Regs到Memory
Control Flow Instructions
- control flow inst允许程序的执行顺序不是顺序的
- Branch、Jump等指令
复杂指令集和简单指令集:
- 复杂指令集是一条指令做很多的工作,如计算FFT、matrix
multiplication,高效性
- 优势:编译器简单、Denser Encoding(smaller code size),更好的内存利用率
- 劣势:Larger chunks of work,难以复用,更复杂的硬件
- 简单指令集是一条指令做很少的工作,如我们以前写的RISCV指令集,灵活性
寄存器数量
寄存器的数量影响了,编码寄存器的位数,寄存在fast storage的数据,reg file的size、access time、power consumption
- 寄存器数量多:
- 使得更好的Register Allocation,更少的saves和restores
- 更大的指令size,即用来编码寄存器的位数要多
- 更大的register file size
Instruction(Processing)Cycle
指令周期是计算机取指令到执行完毕的时间,CPU周期/机器周期是把一条指令的执行过程进行划分程阶段,一个阶段的时间是一个CPU周期,时钟周期是一个阶段里面最小的操作的时间,是最小的单位。
Microarchitecture
下层实现ISA的架构
五级流水线:IF、ID、EXE、MEM、WB
指令周期:指令周期是一条指令被执行的一系列的步骤或阶段,一个指令周期就是把流水线的5个阶段走一遍的时间。
Single-Cycle CPU:单周期CPU
就是一条指令走5个阶段,执行完了再读下一条,这是串行的指令
- CPI:Cycles per instruction is strictly 1
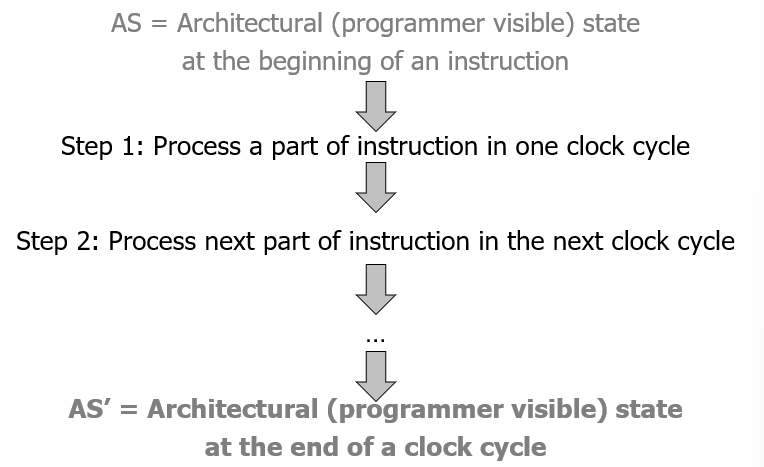
单周期CPU即一个时钟周期完成一条指令
- AS到AS‘在1个cycle中
- AS:Architecture State
每条指令需要一个时钟周期来执行,只使用组合逻辑来实现指令执行。
[C{CD~H5)X@72{@]YV{{IVP.pngX72YVIVP.png)
单周期的执行步骤
- 给出一个指令和 AS(Architectural State)
- ISA抽象地指定新的 AS’ 应该是什么
- 它定义了一个抽象的有限状态机:根据现在的状态由逻辑实现下个状态
- Microarchitecture微架构实现了从AS到AS‘的转换
- 单周期:\(AS\rightarrow AS'\)在一个周期内
DataPath and Control Logic
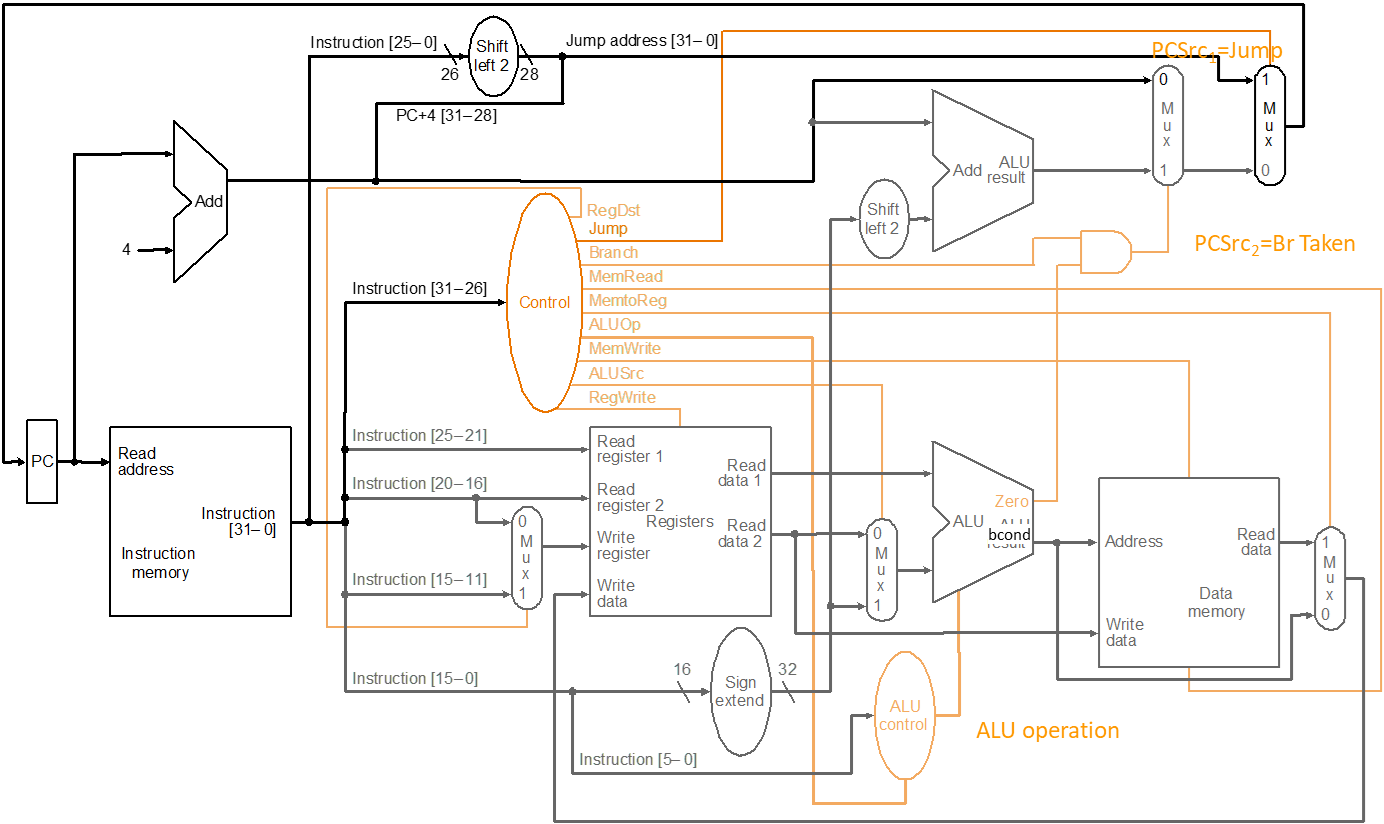
- 单周期的微架构执行一条指令需要一个时钟周期,即
CPI=1 - 每条指令所花费的时间是由执行最慢指令所花费的时间决定的
- 尽管许多指令执行起来不需要那么长时间
- 因为单周期无法跳过一些阶段,因此必须走完所有指令都要走的部分
- 微架构的时钟周期时间是由完成最慢指令所需的时间决定的
- 设计的关键路径由最慢指令的处理时间决定
- 和上面的一样
Multi-Cycle CPU:多周期CPU
- 多周期CPU,让每一条指令只做它需要的阶段,有的是MEM和WB不需要的就不走,其目标是让每条指令只占用它真正需要的周期。一个时钟周期完成一个阶段.但是可以降低时钟周期
- Decrease clock cycle time
- 每条指令需要多少时钟周期就需要多少时钟周期
- AS→AS+MS1→AS+MS2 →……→AS’
- 局限性:
- 并行度太差,每个时刻只有一个阶段的资源在使用,利用率低
- 优点:
- 关键路径设计:能否独立于任何指令的最坏情况处理时间而不断减小关键路径
- Bread and butter(常见情况)设计:可以优化执行重要任务所需的状态数占用大量执行时间的指令
- 平衡设计:不需要提供超出实际需要的能力或资源
- 一条多次需要资源X的指令不需要执行多个X
- 导致更高效的硬件:可以重复使用一条指令需要多次的硬件组件
- Performance Analysis
单条指令执行时间 = CPI * clock cycle time整个程序的执行时间 = 指令数 * 平均API * clock cycle time- 单周期微架构:
CPI = 1- Clock cycle time = long
- 多周期微架构:
CPI = different for each instruction平均CPI → hopefully small
Clock cycle time = short
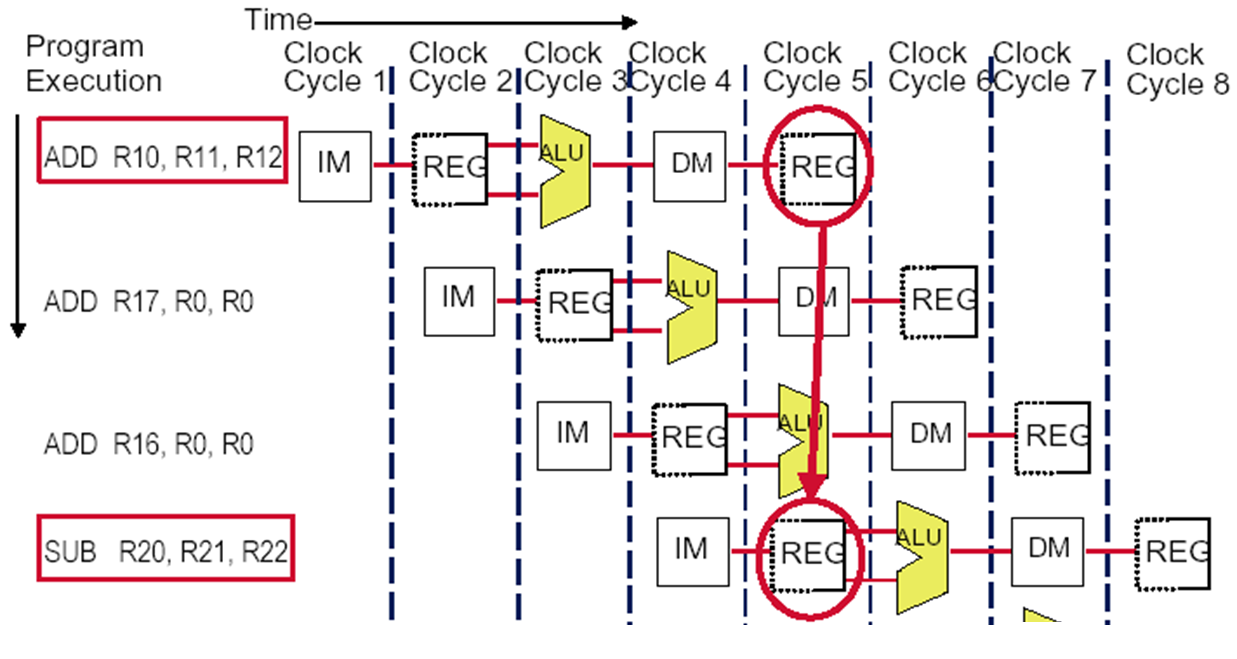
Pipeline CPU:流水线CPU
- Pipeline CPU:更大的吞吐量!一条指令过了IF,下一条指令就可以进来了,要判断hazard的条件。
- 关键思想:当一条指令在其处理阶段使用了某些资源时,在该指令不需要的空闲资源上处理其他指令
- 目标:最大化吞吐率,用最小化的资源
- 核心思想:
- 指令处理周期划分为不同的阶段
- 保证资源都在工作
- 每一个阶段都在执行不同的指令
- 理想中的Pipeline
- identical operations:重复同样的一个操作
- independent operations:指令之间不能有依赖性
- Uniformly partitionable suboperations:分为均匀的suboperation
- Speed up的比例是流水线的级数
- Pipeline处理指令
- 实际中Speed up会小,是因为阶段之间的分布不均匀
- 最完美的情况是每一个阶段都有指令执行
- 但是这些中间部件在ISA中是显示不出来的
- Pipeline的Control信号:
- 选择Ⅰ:只解析一次,并且不断向后传递,对于控制信息不多的情况比较好
- 选择Ⅱ:每个阶段都解析
Lecture 3 Pipeline Hazard & Record Buffer
Pipeline Hazard
Hazard:Hazard是阻止Pipeline中的指令执行其下一个计划Pipeline stage的条件。
Structural Hazard:缺少硬件资源执行,竞争硬件资源
Data Hazard:分三种,对寄存器有依赖
Control Hazard:if、else等条件指令造成的影响
Structural Hazard
- 原因:当两个或多个指令试图在同一个周期中使用相同的硬件资源时发生。
- 后果:产生了一个stall,一条指令不能执行
- 解决方式:可以通过复制硬件资源来克服
- Multiple accesses to the register file:需要两个读口一个写口
- Multiple accesses to the memory
- Fully pipeline the functional unit
- 有关寄存器的Structural Hazard
- 如下图,我们的REG需要2个Read和1个Write来能保证避免Structural Hazard
- 因为ALU需要从REG中读2个值
- 硬件设计需要满足最坏的情况
- 如下图,我们的REG需要2个Read和1个Write来能保证避免Structural Hazard
- 有关内存的Structural Hazard
- 解决方案:将内存分为Instruction和data
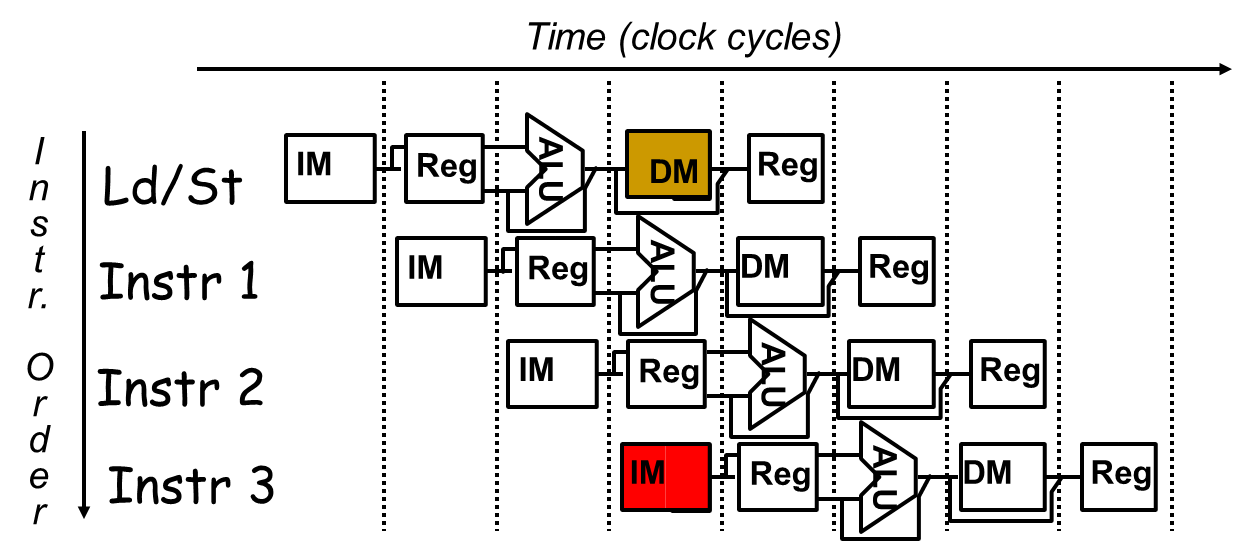
Data Hazard
Data Dependences
- Flow dependence:read after write—true data dependence
- Output dependence:write after write
- Anti dependence:write after read (?)

- 反依赖和输出依赖:它们更容易处理。只在最后一个阶段并按程序顺序写入目标
Flow Dependence/RAW:
- 硬件pipeline stall:侦测并且等待reg的值被处理
- 软件pipeline stall:在软件层面检测并消除依赖,不需要硬件检测依赖
- Data Forward/Bypass:检测和转发/绕过数据到相关指令
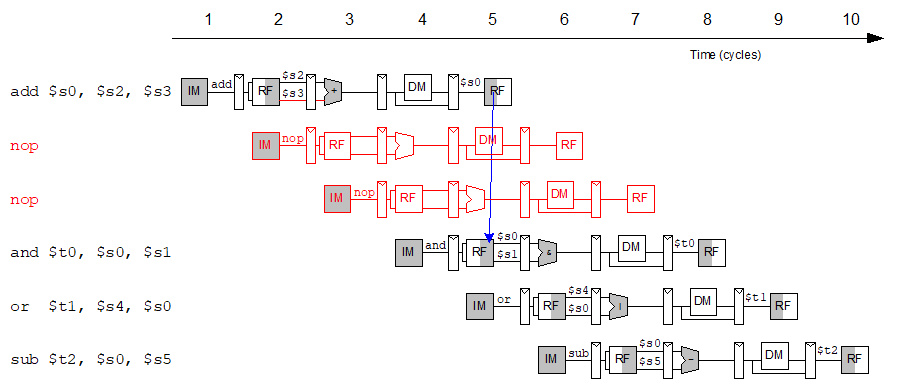
一条指令写一个寄存器($s0),下一条指令读这个寄存器=>读后写(RAW)依赖。
- and、or都会产生错误的值
- sub可以获得正确的值(先写后读的情况下)
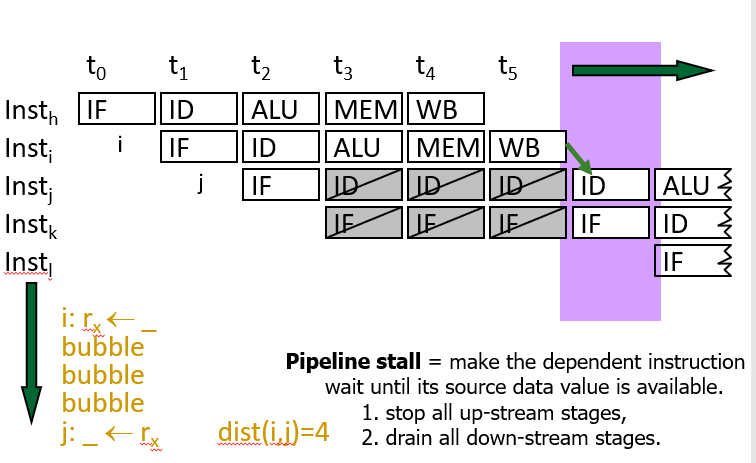
“fix”流依赖的最简单方法是暂停pipeline。
- Pipeline stall,称为pipeline bubble或简称bubble。pipeline
stall会做:
- 先前的指示:继续在pipeline中进行。
- 下面的指令:在pipeline中被一个或多个时钟周期停止,直到等待寄存器准备就绪。
- 新指令:在stall期间未获取。
例子:假设i写了ra,j读了ra
如何在硬件中实现?
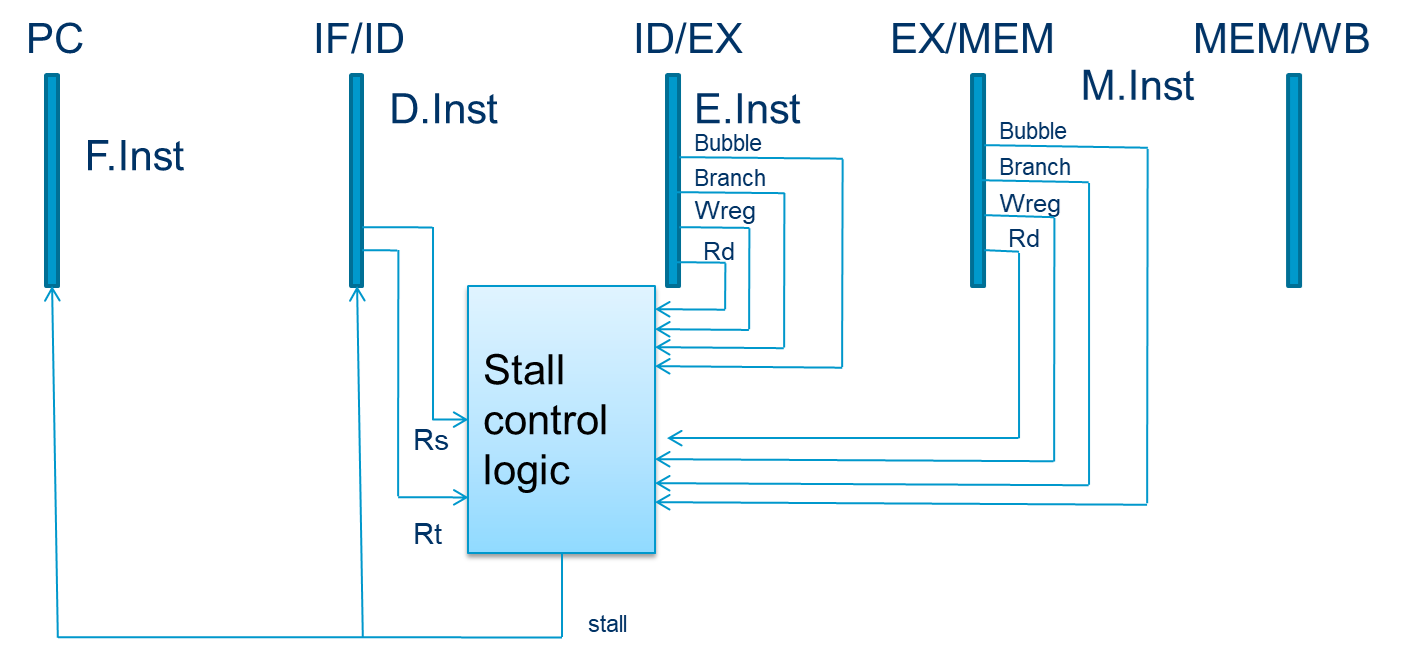
- pipeline stalling:
- 禁用PC和IF/ID锁存,确保有stall时后续的指令会停在原来的阶段
- 将一个bubble推到下一阶段:bubble = 1并禁用控制信号Wreg和Wmem;向前push一个nop到ID/EX。
- Stalls are supported by
- 一个使能EN来控制Fetch和Decode的pipeline registers
- 以及同步重置/清除(CLR)输入到EXE pipeline寄存器或与每个pipeline寄存器相关联的INV位,表示内容无效
软件的解决方法:
侦测冲突,并且使用软件增加足够的nop指令来使得reg准备就绪。或者可以移动指令位置,来避免冲突。
- 在编译器级别重新排序/重新安排指令
- 插入nops的个数不是固定的,要根据上下文来确定
- 使用软件插入,更易于理解,硬件设计更加简单。
软件VS硬件
- 软件是静态调度,编译器必须把指令排序,硬件顺序执行他们
- 在实时的过程中,软件不能知道依赖关系的硬件状态,不知道每一个指令的latency,也不知道if else的逻辑。
- 编译器不知道哪些信息使得静态调度变得困难?在运行时确定的任何东西比如可变长的操作延迟、内存地址、分支方向
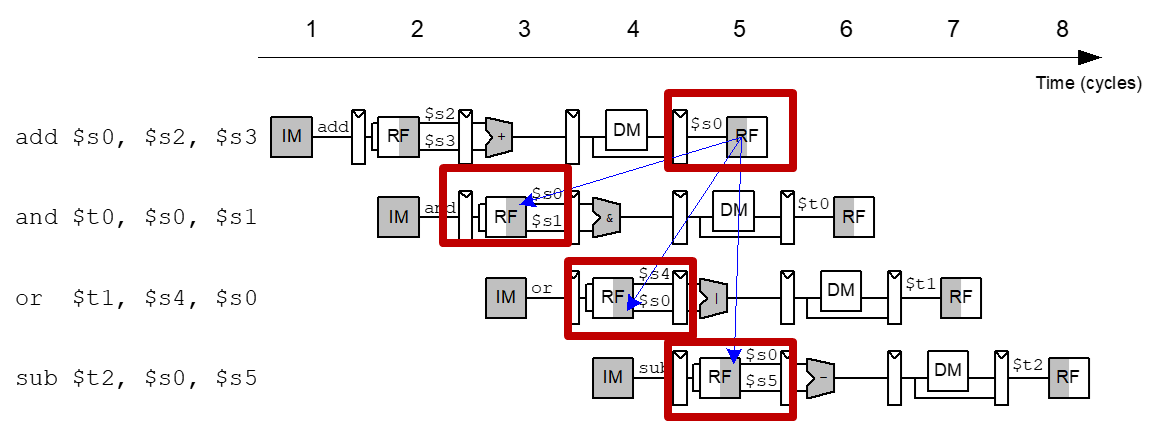
DataForward
一旦结果值可用,就将结果值转发给相关指令
有点像Dataflow的方式
- 数据值提供给相关指令,只要data是available的
- 指令在其所有操作数available时执行
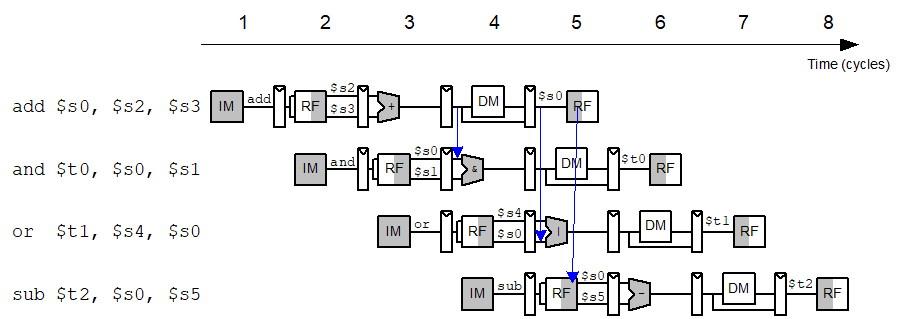
Forward可以有两种情况:
- 将MEM阶段的值返回给EXE
- 将WB阶段的值返回给EXE
我们应该在什么时候从MEM阶段或WB阶段Forward到EXE?
如果该阶段将写入目标寄存器,并且目标寄存器与EXE阶段的源寄存器匹配。
Forward优先级:
- 例子:写s0,写s0,读s0,那么此时的EXE需要的是第二次s0的值,即MEM阶段的值
- 优先MEM,后WB
1
2
3
4
5
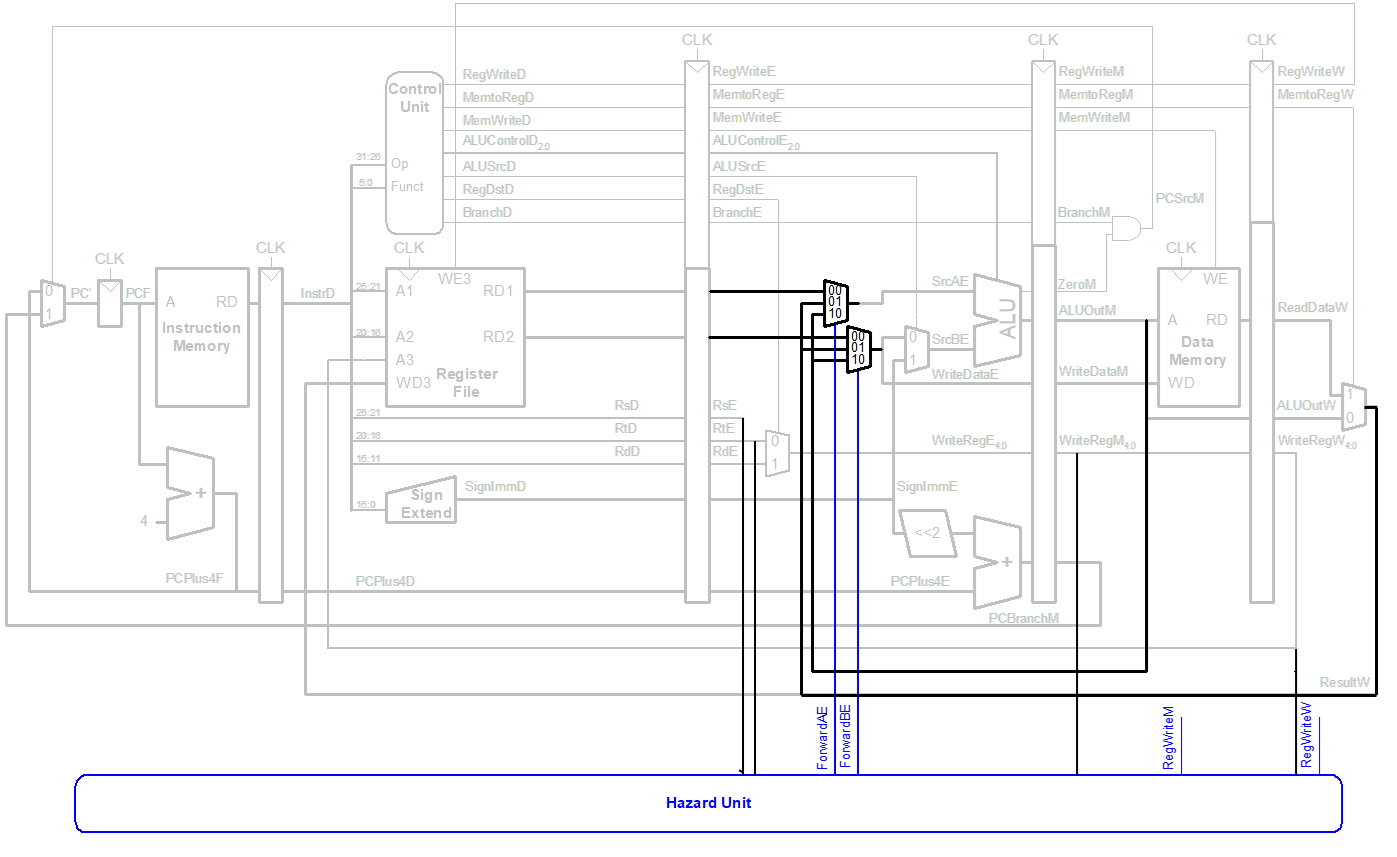
6if ((rsE != 0) AND (rsE == WriteRegM) AND RegWriteM) then
ForwardAE = 10 # forward from Memory stage
else if ((rsE != 0) AND (rsE == WriteRegW) AND RegWriteW) then
ForwardAE = 01 # forward from Writeback stage
else
ForwardAE = 00 # no forwardingForward不是都可以行得通的
- 由于pipeline设计和指令延迟
- lw指令直到Memory阶段结束才完成读取数据,导致了其结果不能转发到下一条指令的Execute阶段
Control Hazard
if else这种分支判断的指令都有control hazard。取决于Instruction Pointer / Program Counter
解决方案:分支预测
Reorder Buffer
Pipeline CPU:Ideal vs Realistic
- Ideal pipeline CPU
- 一个pipeline
- 固定延迟
- 依赖关系在编译器时已知
- 不支持异常/中断
- Realistic pipeline CPU
- 具有不同延迟的多个pipeline
- 不可预测的延迟
- 编译时未知的依赖项
- 支持异常/中断
For Multi-cycle Execution
- 多周期执行的问题:不同指令的执行的时间不同。
- 解决方案:对不同的执行周期的指令,用不同周期的执行单元执行。要有多个不同的功能单元,它们需要不同的循环次数
- 可以让独立的指令在之前的长延迟指令完成执行之前在不同的功能单元上开始执行
- 比如我们有两个pipeline:一个是4stage的,一个11stage的,分别对应了1轮8轮EXE的两种指令,那么执行时就应该是如下图所示的,ADD不需要等DIV执行完再执行(没有冲突时),可以直接使用另一pipeline执行
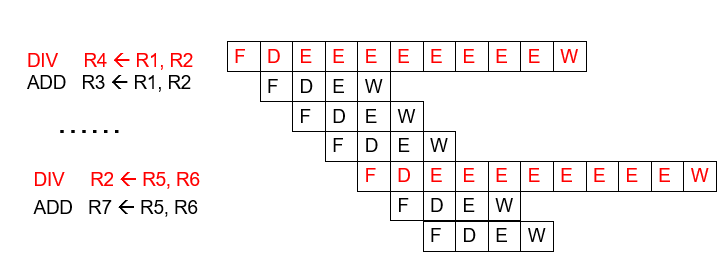
- 但是很明显,上面的执行步骤有很明显的问题:WriteBack的顺序会出现错误,因此这是我们的Reorder Buffer要做的事情!
For Exception and Interrupt
程序执行中的“Unplanned”更改或中断
- Exception:由于程序执行中的内部问题internal problems
- Interrupts:由于需要由处理器处理的外部事件external problems that need to be handled by processor
Exception和interrupts的处理步骤:
- 停止当前的程序
- 保存状态,context switch
- handling the exception/interrupts,可以交付给handler进行
- When to handle?
- Exception:当检测到就要handle
- Interrupts:when convenient(除非interrupt的优先级很高)
- When to handle?
- 如果有返回,返回程序执行,context switch
Precise Exception/Interrupts
当异常/中断准备好处理时,体系结构状态arch state应该是一致的(精确的),我们要记录保存下这个状态。
精确异常:简单地说就是 eptr 的指向就是真正引起异常的指令之所在
- 所有以前的指示都应该完全retire
- 以后的指令不应retire
- retire=commit=完成指令并且更新arch state
当最后一条要retire的指令被检测到exception时:
- Ensure arch state is precise
- 将所有之前在pipeline的instructions进行flush
- 保存此时的PC和register
- 重定向Fetch引擎到适当的异常处理例程
为什么要做Precise Exception?Goal?
- 保持冯·诺依曼模型的语义
- 辅助软件调试
- 允许(轻松)从异常中恢复
- 使traps进入软件(例如,软件实现opcodes)
在单周期和多周期的CPU中如何做的呢?
- single cycle
- 指令边界=周期边界
- multi cycle
- 在控制FSM中添加导致异常或中断处理程序的特殊状态
- 仅在获取下一条指令之前的精确状态切换到处理程序
For False Dependences(WAW&WAR)
False Dependences就是WAW和WAR的情况的统称
保留顺序语义
说会上文,我们说了For Multi-cycle Execution,使用多pipeline的方式会使得WB的顺序错误,我们需要让这个写的顺序正确。我们有一种选择就是让所有的指令都走最长的latency,但是那样子效率不高
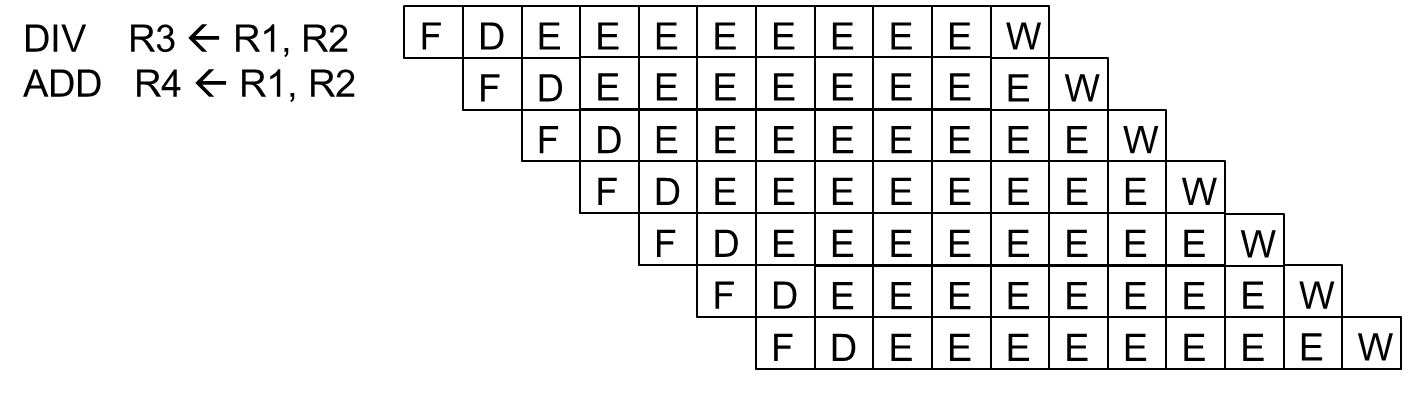
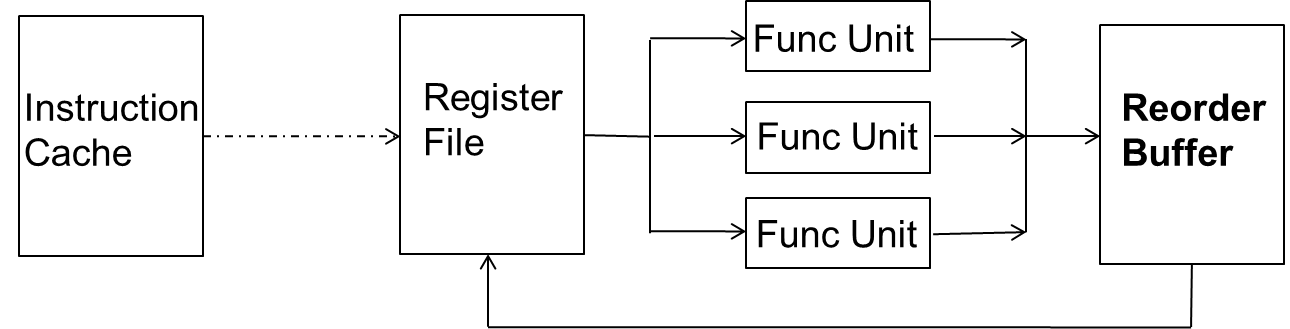
Reorder Buffer(ROB)
核心思想:Complete instructions out-of-order,but reorder them before making result visible to arch state(Commit)
- 指令的Complete和Commit是不同的
- 当指令被Decoded,它会在Reorder Buffer中顺序保留一个自己的entry
- 当指令Complete了(执行单元出来),它会将结果写到Reorder Buffer中对应的entry中
- 当ROB中最早进入的Instruction已经Complete了,并且没有exception,这条entry的对应值写回Register files或者Memory【问:这条entry怎么了?清空?还是整体移动 答:环形的结构清空后一直继续顺序写,清空的不用管】
ROB的entry

- 需要正确给指令重新排序到原始程序一样的顺序
- 如果指示可以retire没有任何问题,根据指令的结果更新arch state
- 精确处理异常/中断,如果异常/中断需要在指令retire之前处理
- 使用有效位来跟踪结果的就绪情况,并确定指令是否已完成执行
那么使用ROB后,我们的写回阶段时间点就有了变化:
- 指令complete时,结果写回首先写到ROB中
- 在commit时,ROB会把结果写回reg file/memory
那么问题来了:如果后续指令需要用到前面指令的值,而这个结果值还在ROB怎么办?
- One Option:stall
- Better:从ROB中读取值
一个寄存器的值能在Reg files中,reorder buffer中,那么我们使用间接访问的方法,来简化ROB的访问
- 首先访问Reg file,若reg file中为invalid,那么寄存器会有对应的ROB的ID,我们去对应的entry获取这个寄存器值即可
- 访问ROB
Reorder Buffer:For False Dependencies
- 输出依赖和反依赖都不是真正的依赖,为什么?
- 同一个寄存器指的是彼此没有任何关系的值
- 它们的存在是因为ISA中缺少寄存器ID(name)
- 寄存器太少了
- RB消除了反依赖和输出依赖,给人一种有大量寄存器的错觉,为什么?
- 因为实际上我们的reg有限,但是ROB的entry很多,相当于reg和entry是同一个东西。只是被Rename了。
- 寄存器ID→ROB entry ID
- 架构寄存器ID→物理寄存器ID
- 重命名后,ROB条目ID用于引用寄存器

- 因为实际上我们的reg有限,但是ROB的entry很多,相当于reg和entry是同一个东西。只是被Rename了。
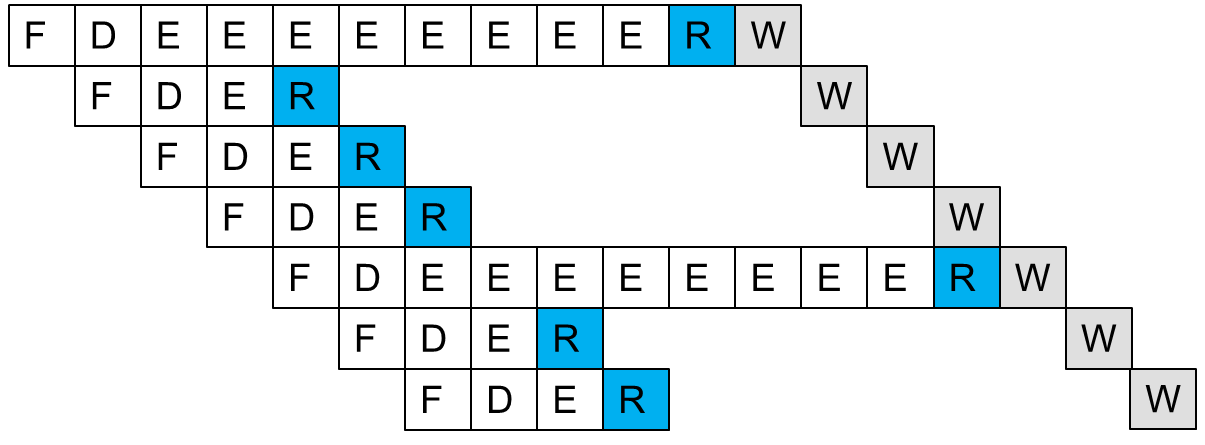
In-Order Pipeline with Reorder Buffer
引入了Reorder Buffer我们的Pipeline就可以如下执行:
- In-order dispatch/execution,out-of-order completion,in-order retirement
- Decode (D):访问regfile/ROB,在ROB中分配条目,检查指令是否可以执行,如果可以,则分派指令
- Execution(E):指令可以乱序完成
- Completion(R):将结果写入重排序缓冲区ROB
- Retire/Commit(W):检查例外情况;如果没有,将结果写入架构寄存器文件或内存。否则,flush pipeline并且开始异常处理
Advantages:
- 概念上简单,支持精确的异常
- 可以消除false dependences
Disadvantages:
- 需要访问Reorder缓冲区以获得结果尚未写入寄存器文件
- 间接→增加延迟和复杂性
Lecture 4 Tomasulo & SIMD
Tomasulo算法
有了这个算法指令可以乱序执行。旨在指令之间的并行。
In-order Dispatch
正常来说,前面的指令stall了,后面的指令也会跟着stall掉
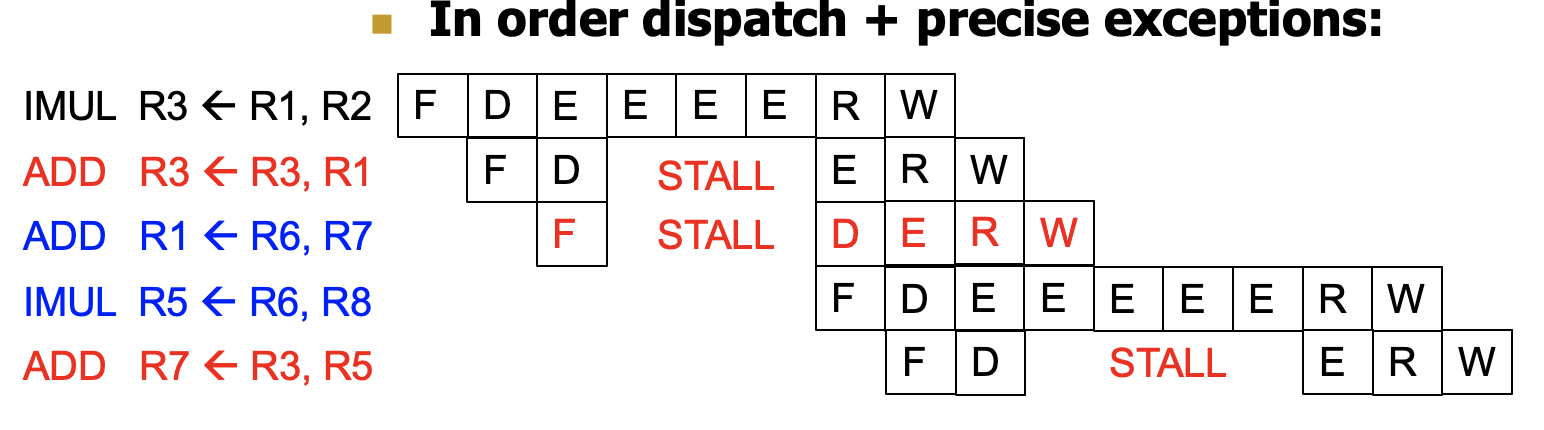
那么Tomasulo算法就是为了让这两条蓝色的指令不受STALL的影响
Solution:out-of-order dispatch
Reservation Station
Key idea:
- 在ID和EXE阶段之间插入了RS,让有冲突的指令不要堵住后面的,让有冲突的指令在RS中等着。
- Rest areas for dependent instructions:Reservation Station
- 本质就是一个指令buffer
Tips:
- 进入RS是要顺序的,出RS进入执行可以是乱序的
- 出ROB写会要顺序的,进入写ROB可以乱序的
- 两头顺序,中间乱序
Function:
- 监控在RS区域内的指令的source的值是否available
- “fires”(dispatch)那些source值(一般最多是rs1和rs2)都已经available的指令
- dispatch出来都是符合data-flow的顺序的
Tomaulo算法实现
Enabling OoO Execution
需要将value的“consumer”和“producer”连接起来
使用Register renaming的方式:用tag将register相互连接,比如目的寄存器的两个源寄存器也被作为了目的寄存器时
Buffer所有的指令,即所有的指令都要进RS,让RS dispatch
使用RS和renaming的技术
指令要跟踪readiness of source
- 当一个tag的值已经从EXE出来了,要broadcast,消除对应的依赖。
- source可以是直接valid的,也可以是不valid的要依赖tag,此时若tag已经complete了,要更新依赖
当所有的source都是valid,我们的指令可以分发执行
Register Rename
Register Rename Table
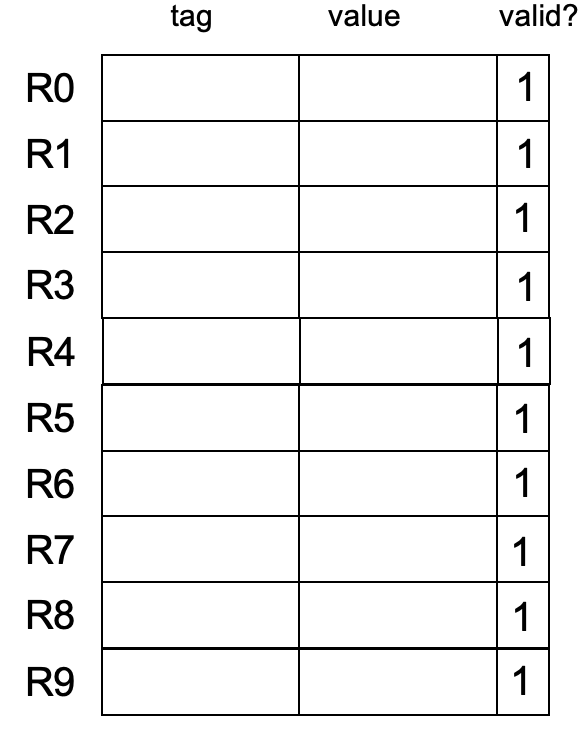
- Valid的话,该寄存器的值是value;否则为tag里面对应的值
Reservation Station
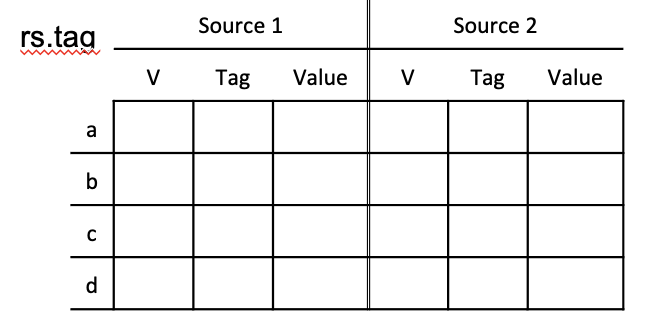
- 实际上还有一个标记是否是否为空的标记,来执行清除和写入判断
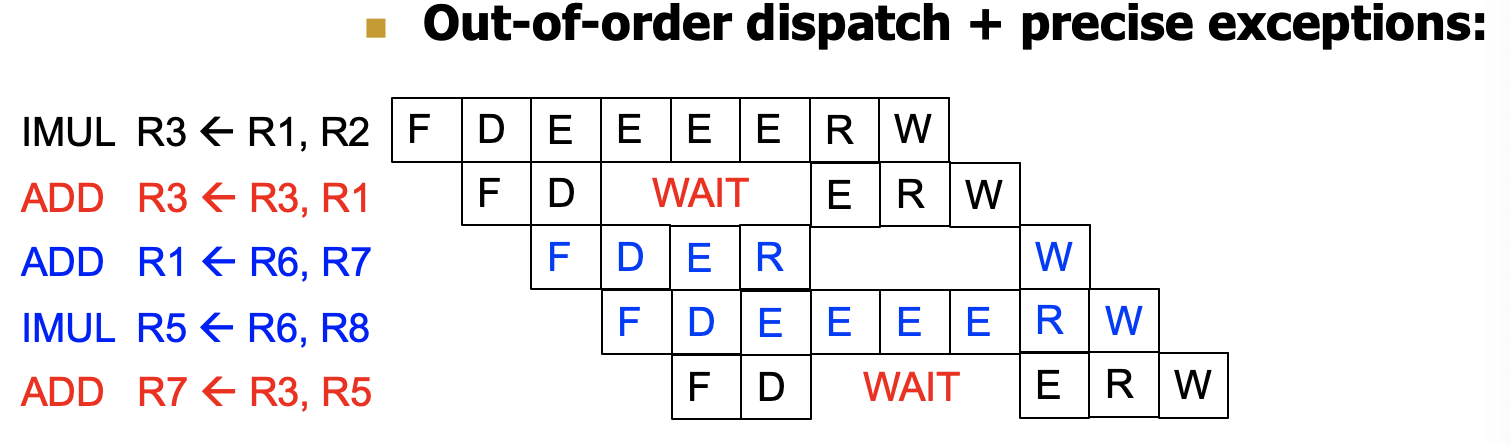
执行步骤
RS在ID阶段check,check完后会自动选择一个两个都是Valid的指令执行,若有多个可执行的执行则会自动选择一个执行,因为执行单元对应只有一个。那么实际上执行完后就会WB,WB之后是要清除RS中内容的,否则会一直竞争。
下面的例子没有考虑竞争和清除!!!
初始状态
Cycle 1
- 第一条指令Fetch
Cycle 2
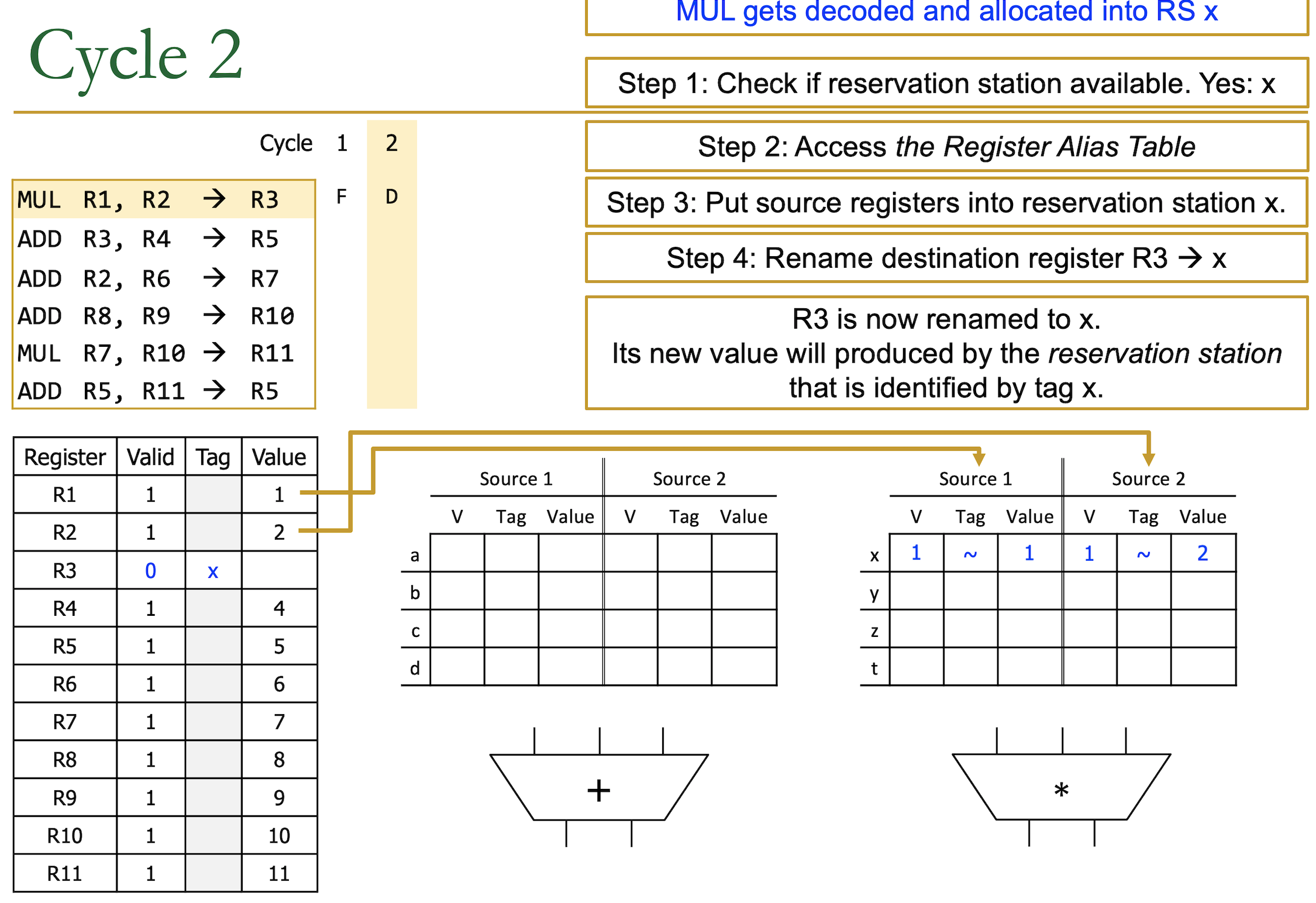
- 乘法指令没有依赖一直跑到ID,但是ID阶段要去RS
- step1:检查RS是否有空间:x
- step2:访问reg table
- R1是Valid的,Value为1
- R2是Valid的,Value为2
- step3:将R1和R2的值写入RS
- step4:重命名R3为x,告诉我们寄存器文件里的R3不是最新的,而是RS中的x
- 乘法指令没有依赖一直跑到ID,但是ID阶段要去RS
Cycle 3
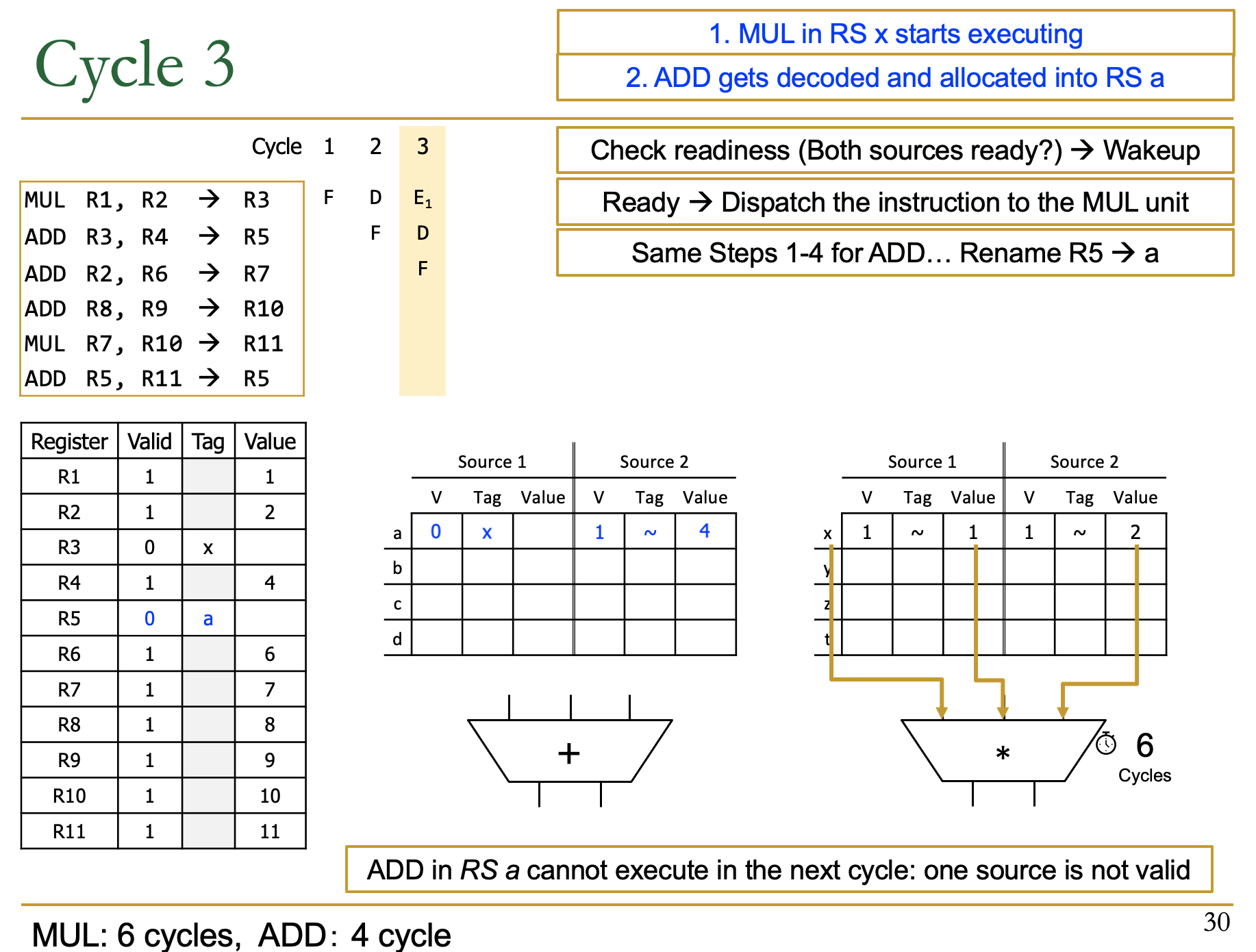
- 第二条指令进入了ID阶段
- step1:因为是Add指令,因此去Add的RS中找空间:a
- step2:Add里有两个操作数,R3和R4
- R3是Valid=0的,Tag=x
- R4是Valid=1的,Value = 4
- 由于R3的Valid是0,因此要等Mul的结果R3
- step3:写入Add的RS中
- step4:R5的tag是a,valid是0,寄存器中的R5不是最新值了
- 第二条指令进入了ID阶段
Cycle 4
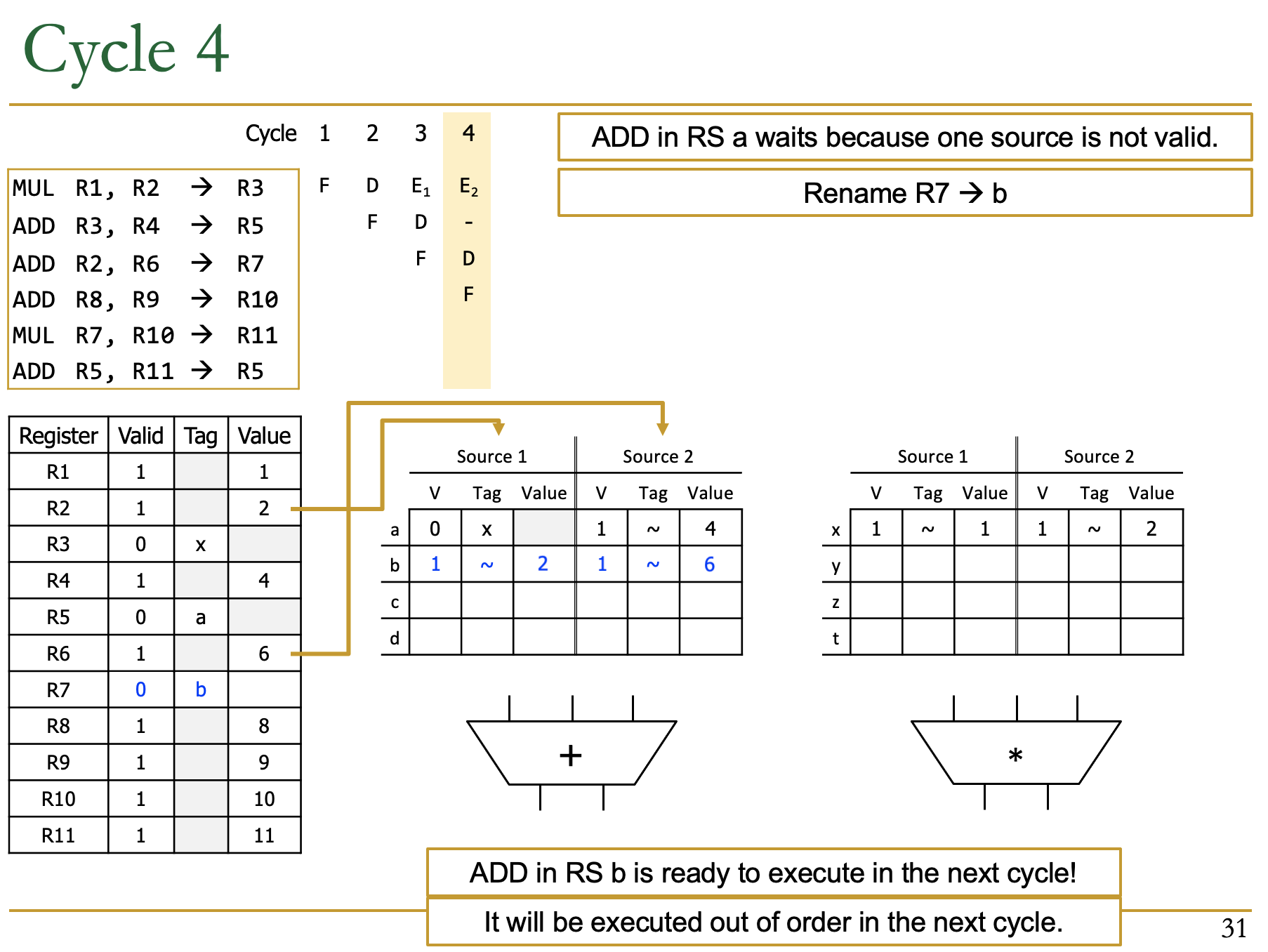
- 第一条指令执行,第二条指令被堵住了,第三条指令进入了ID
- 第三条是Add,检查RS的空余,有b
- R2和R6都是Valid的,把目标寄存器R7重命名为b
- 写入b的两个source(R2和R6),都是valid
- 意味着这条指令可以继续执行
Cycle 5
Cycle 6
Cycle 7
- 第六条指令进入ID阶段,是加法RS,空余d
- R5此时已经是a了,但是我们还是要重命名为d
- RS中d对应的两个source reg是老的R5对应的a和R11对应的y
Cycle 8
- 此时的第一条指令已经Complete了(EXE执行完)
- RS的输出为tag=x和value=2
- 检查谁和x有依赖,全部替换为valid和value
- 这里在Reg Table里有依赖
- Add RS中的a有依赖
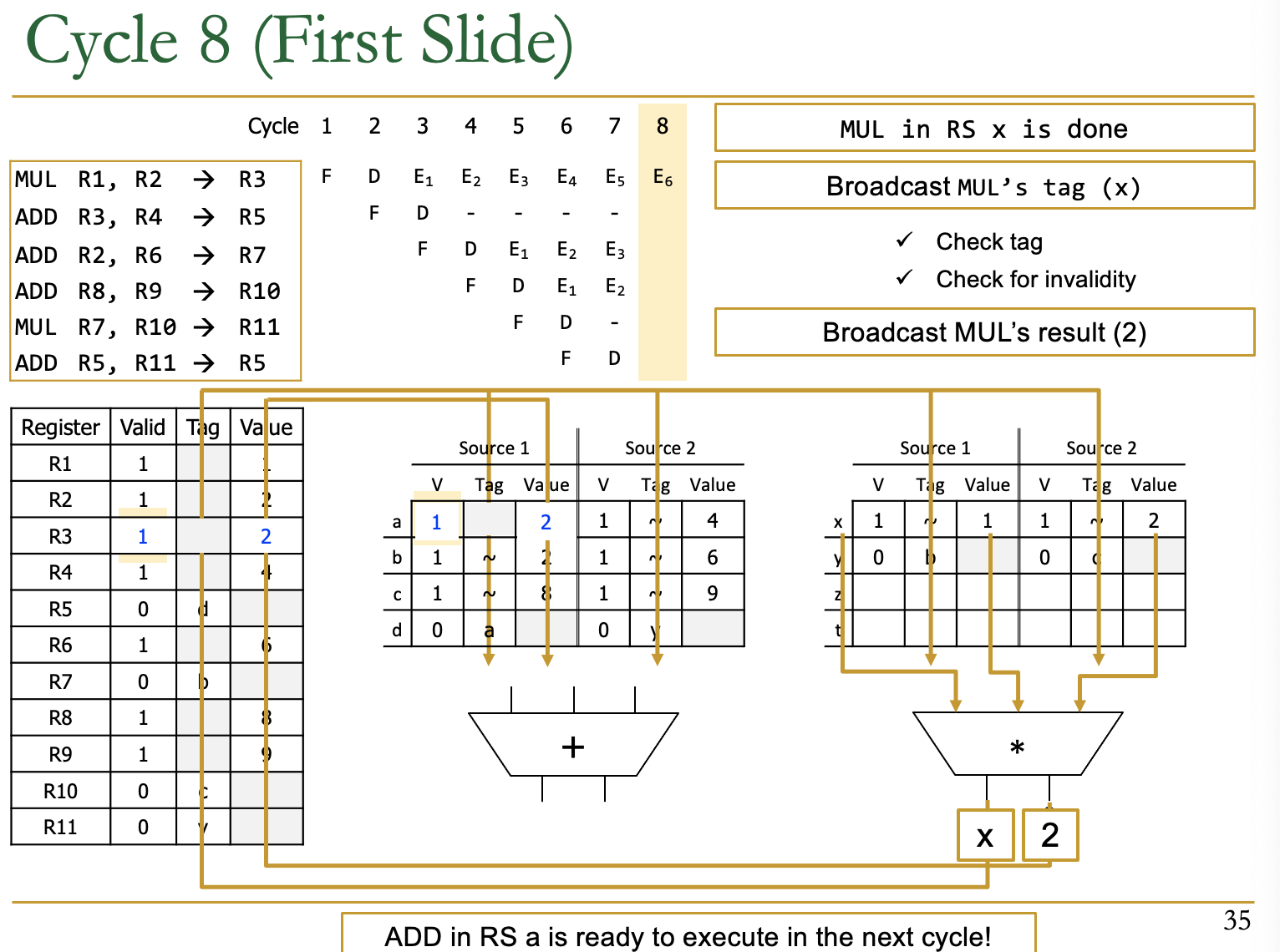
- 问:如何判断是否执行,这里的第二条指令两个source已经valid了
- 此时的第三条指令也Complete了
- 输出为tag=b和value=8
- 检查b的依赖进行替换
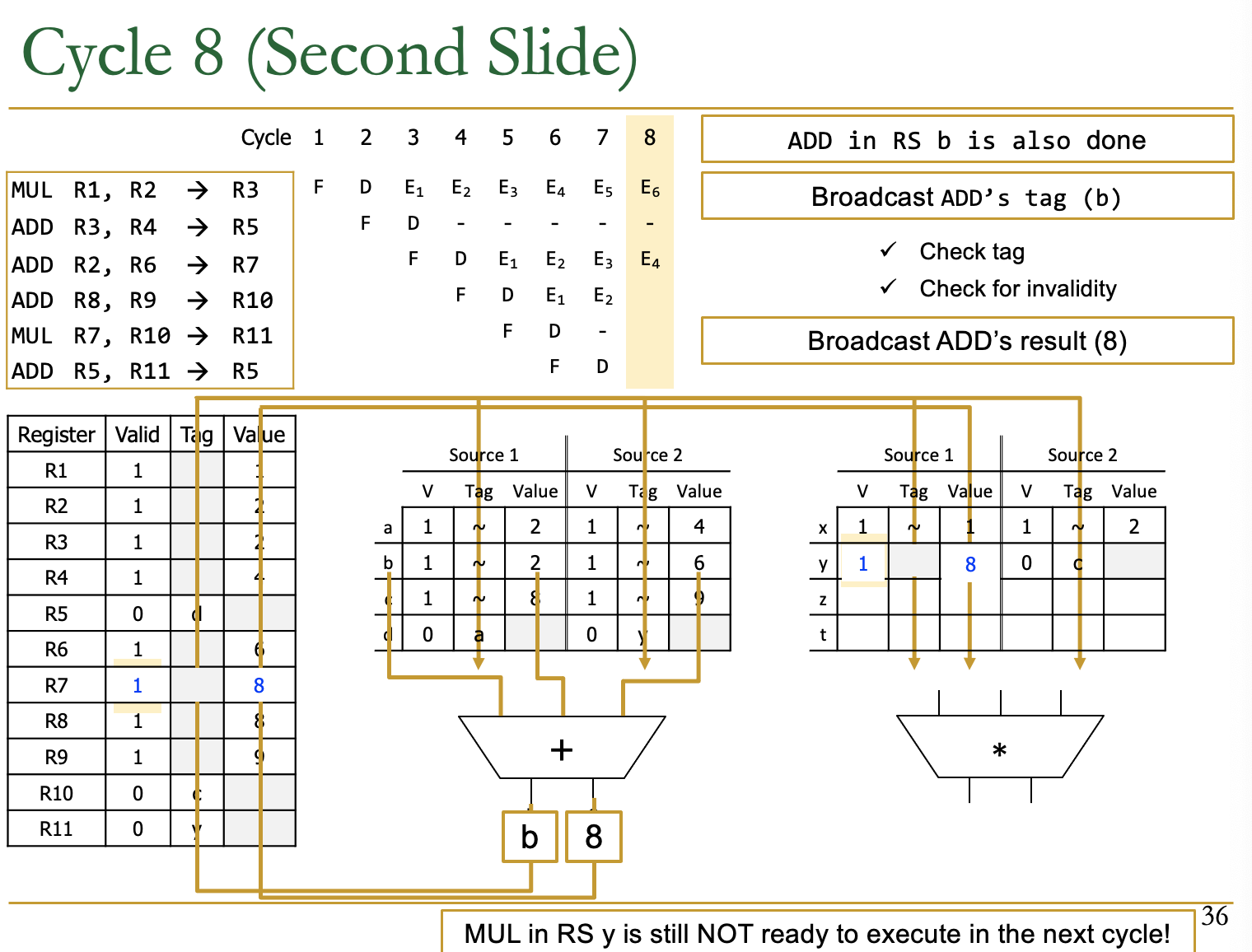
- 此时的第一条指令已经Complete了(EXE执行完)
Question
- 关键路径问题
- 最慢的阶段是:Tag Broadcast、value capture、instruction wake up
- 如何减少这个关键路径的问题:
- 更新可以分为好几个周期,因为不更新也不会影响正确性,原来有依赖的指令不会提前开始运行
- Dataflow Graph
使用了Tomasulo算法后就有类似的图结构了
让指令之间能并行的都执行了
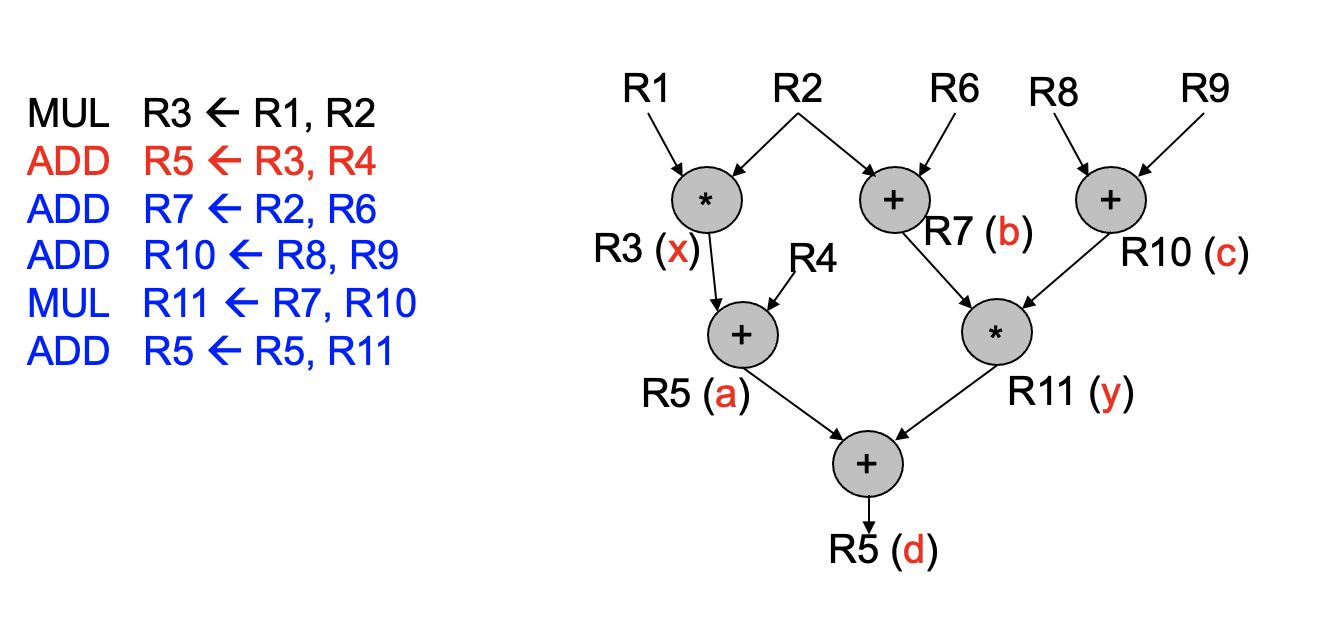
Out-of-Order Execution with Precise Exception
- Idea:使用ROB去reorder instructions在committing到AS之前
- 一条指令更新RAT(Register Table)当其complete了EXE
- 这些也称为Front Register File,不是有编制的,不影响架构的状态
- 一条指令更新分离的Architectural Register File当其retire
- Architectural Register就是我们常见的r0-r31 ,有编制的
- Architectural Register总是按照program order来更新
Lecture 5 Superscalar&SIMD&Multithread
Recall:Tomasula Algorithm
- ID:若RS中有空的entry,那么我们要rename dst register
- 为这条指令占有一个RS Entry
- 对每一个RS Entry中的source register:若valid bit在Register Table中为1,那么RS.source.v=1,RS.source.value=source register;若为0,那么RS.source.v=0,RS.source.tag=source register.tag
- 对于每一个Register Table中的dst register:Rename to the tag of the corresponding RS entry。重命名为对应的tag
- RS:当在RS中时,每一条指令
- 更新:检查common data bus(CDB)看自己的source的tag,when tag seen,grab value for the source and keep it in RS
- Issue:当两个operands available,那么这条指令就可以准备dispatch了
- EXE:在FU中执行指令,产生其boardcast tag和value
- WB:需要竞争总线,因为可能有很多的EXE的输出
- 竞争总线,选择一个EXE输出的Boardcast Tag和Value
- 将广播标签及其广播值放入CDB(总线)
- 更新连接到CDB的寄存器文件Register File Table,如果寄存器文件中的标记与广播标记匹配,则将广播值写入寄存器(并设置有效位)
- 更新连接到CDB的RS,如果广播标记与RS条目中任何源的标记匹配,则写入向源广播值并设置源的有效位
Superscalar
超标量,本质还是在提升指令执行的并行度
- Idea:Fetch,decode,execute,retire multiple
instructions per cycle
- N-wide superscalar可以N instructions per cycle
- Issues:
- 需要更多的硬件资源去做
- 指令之间的冲突关系更多了。因为同时有多条指令在执行会产生很多的冲突。
- Superscalar execution和out=of-order execution是正交的概念,互不影响
- [in-order,out-of-order]×[scalar,superscalar]
一个Example
Idea:Multiple copies of data-path:Can fetch/decode/execute multiple instructions per cycle
Issue:冲突更加复杂
比如我们要做一个可以处理两条指令同时执行的超标量流水线CPU,那么此时我们要从Instruction Memory中拿出2个指令,Register file的读口、写口也要翻倍,ALU的数量一定要翻倍(最重要的执行阶段),同样的WB阶段的读口和写口也要翻倍。
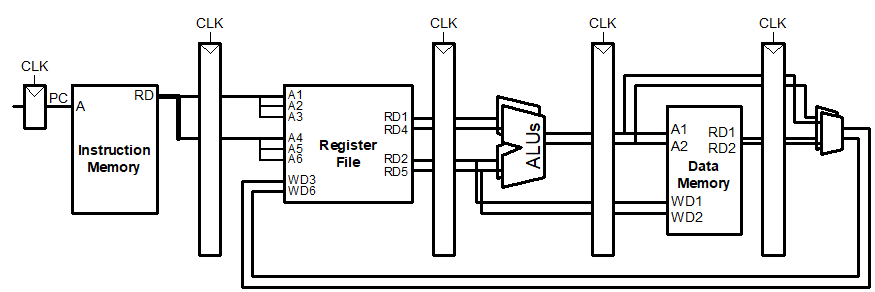
上图的理想的IPC=2,但是实际中我们的superscalar有更多的dependence,难以达到这个IPC。
有Dependence的Superscalar Performance
由于依赖的存在有的指令不能在同一波执行,有的波次之间也需要stall
- Advantage
- Higher instruction throughput
- Higher IPC:instructions per cycle
- Disadvantage
- Higher Complexity for dependence checking
- 需要check在一个pipeline stage中
- 在OoO的processor中寄存器的重命名更复杂
- Potential lengthens critical path delay,clock cycle time
- 硬件资源需求更多。
- Higher Complexity for dependence checking
Vector Ins
SISD:单指令单数据,一个指令只对一个数据操作
SIMD(https://zhuanlan.zhihu.com/p/55327037):单指令多数据,一个指令带着很多的数据,即可以批量对多个数据进行这个指令操作
- Array processor
- Vector processor
MISD:多指令单数据
MIMD:多指令对多数据执行
- multiprocessor
- multithread processor
SISD
在指令或数据流中没有并行的。
SISD的例子:传统的单处理器机器,例如我们信赖的RISC-V pipeline
SIMD
一条指令可以对多个数据进行操作,能够有更高的并行性
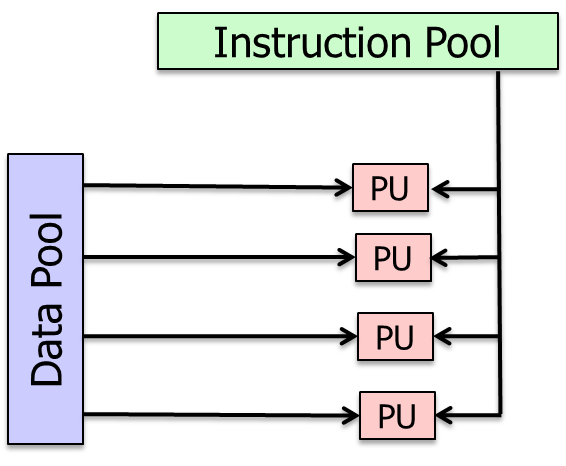
比如可以进行向量的加法。若用SISD进行100维向量的加法,需要100次,若SIMD一次可以操作100个数据,则只需要一次的加法操作
- Intuition of SIMD Capability
- 计算\(A[6:0]+B[6:0]\)
- scalar:一个cyle进行一次加法
- SIMD:一个周期多个操作,比如4个操作
- Scalar:最少需要7个周期
- SIMD:最少需要2个周期
- 计算\(A[6:0]+B[6:0]\)
- SIMD in Intel CPU:
- 256 bit AVX2:8个32-bit的float
- 512 bit AVX512:16个32-bit的float
Vector Processor Limitations
- 内存(带宽)可能会是一个瓶颈
MIMD
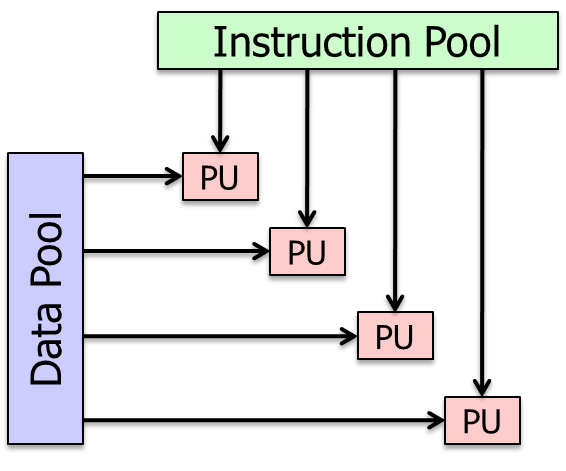
MIMD计算机利用多个处理器实现异步和独立的并行性。
在任何时候,不同的处理器都可能对不同的数据块执行不同的指令。
多用于Multiprocessor和Multithreaded processor
MISD
MISD计算机利用多个指令流对单个数据流。
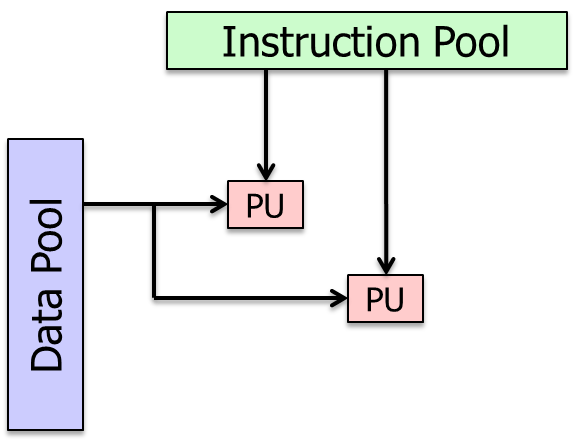
Support Vector Insns
- Vecoter Register File:端口数量增加
- V ALU:ALU数量增加
- V Memory:端口数量增加
Programmer Visible Architectural States
- Memory
- Array of Storage locations indexed by an address
- Memory Bank Design:与原来的不同给一个地址出一个数不同,现在给一个地址,出来4个数(一般是连续的)
- Register
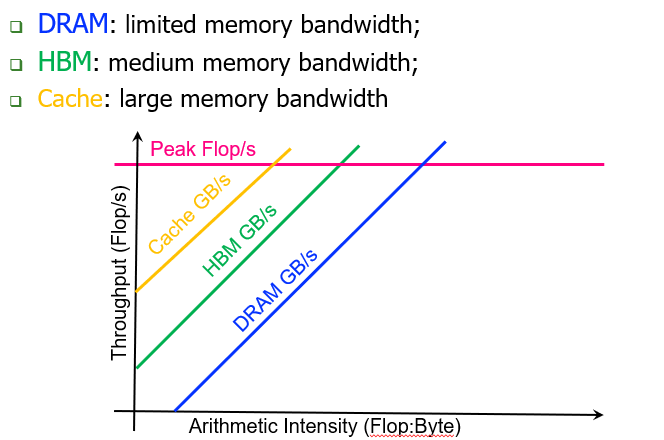
Roofline Model for SIMD CPU
本质上来说看的是理论的算力。加了SIMD,对算力是有提升的。
在Roofline Model中可以体现出来。Throughput会是普通pipeline的几倍
Fine-Grained Multithreading
https://www.cnblogs.com/caishunzhe/p/12817245.html
- FMT(fine-grained multithreading)又叫交叉多线程或指令交错多线程
- 每个时钟周期都进行线程的切换,多个线程交替执行,同一个周期只从一个线程发射指令到功能部件
- 理论上,FMT通过有效的调度可以完全隐藏存储延时,即在存储操作完成之前不从同一个线程取指
一个物理核一般支持两个逻辑核
- Idea:
- 硬件有多个线程的context(PC+Registers)。每一个cycle,取指令引擎从不同的线程去fetch
- 让ALU的利用率更高
- 每一个时钟周期都进行线程的切换,以确保没有两条指令来自同一个thread
为什么:因为Thread之间没有依赖,Thread内部有依赖,每轮时钟周期从不同的Thread中取指令可以避免dependence。
- Advantage
- 在线程中不需要处理控制和数据依赖的逻辑
- Disadvantage
- 单线程性能下降
- 用于保持线程上下文的额外逻辑
- 如果没有足够的线程覆盖整个管道,不会重叠延迟
- idea:
- 每个周期切换到另一个线程,这样就不会有来自线程的两条指令同时在pipeline中
- Advantage
- 通过与其他线程的有用工作重叠延迟来容忍控制和数据依赖延迟
- 通过利用多线程提高pipeline利用率
- 一个thread之内不好的并行,可以通过thread之间的并行,来提升并行度
- 提升了利用率
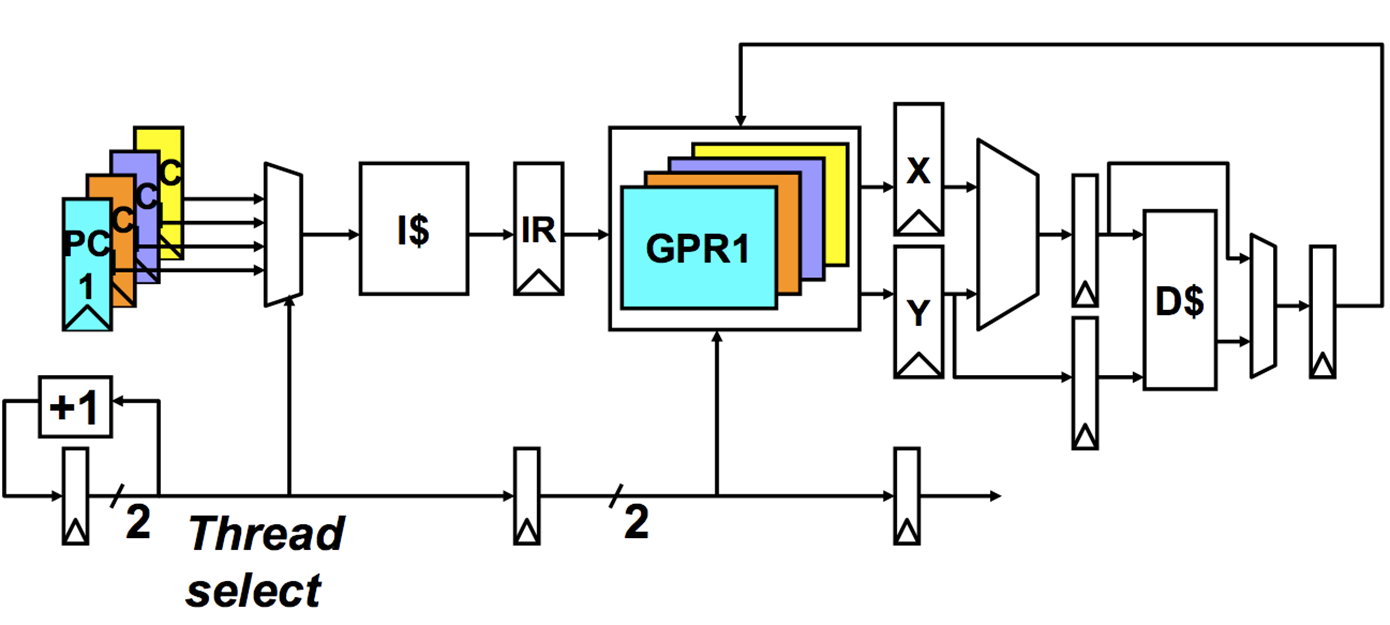
Advantages
- 不需要额外的Dependency检测
- 不需要branch预测逻辑
- Otherwise-bubble周期用于从不同线程执行有用的指令
- 提升系统的吞吐率、延迟容忍、利用率
Disadvantages
- 更多的硬件复杂度:更多的context(PCs、Register Files)
- 减少了单线程的表现
- 缓存和内存中线程之间的资源争用
- 线程之间仍然保留一些依赖项检查逻辑(加载/存储)
Multi-Core
- idea:把多个核放在同一个模具die上。
- Technology scaling 使得更多的晶体管可以放到同一个模具区域上。
- 还可以对专用于多处理器的芯片区域做什么?
- 拥有更大更强大的核心
- 内存层次结构中有更大的缓存
- 同步多线程
- 在芯片上集成平台组件(例如,网络接口,内存控制器)
Why Multi-Core
- 可选的替代方案:更大、更强大的单核
- 更大的超标量问题宽度、更大的指令窗口、更多的执行单元、更大的跟踪缓存、更大的分支预测器等
- 提高单线程性能,对程序员和编译器更透明
- 非常难以设计(可扩展的算法,以提高单线程性能难以捉摸)
- 耗电-许多乱序执行结构在扩展时消耗大量的功率/面积。
- 收益递减
- 对内存受限的应用程序性能没有显著帮助(可伸缩算法对此难以捉摸)。
- MultiCore的优势
- 更简单的核心,更节能,更低的复杂性,更容易设计和复制,更高的频率(更短的线,更小的结构)
- 在多程序工作负载上提高系统吞吐量,减少上下文切换
- 并行应用程序中更高的系统吞吐量
- MulitiCore的缺点
- 需要并行任务/线程来提高性能(并行编程)
- 资源共享会降低单线程性能
- 共享硬件资源需要管理
- 引脚数量限制数据供应增加的需求
Lecture 6 Memory
理想的计算平台

Memory Overview
我们的目标:带宽大、容量大、延迟低。一般而言三者不能兼得,而且要考虑cost
- 容量大,导致,更长的寻址定位时间,即延迟高
- 延迟低,速度快,导致,cost高:SRAM、DRAM、SSD、Disk、Tape
- 带宽大,导致,cost高:更多的bank、port、channel,higher frequency or faster technology
各种存储元件的比较:
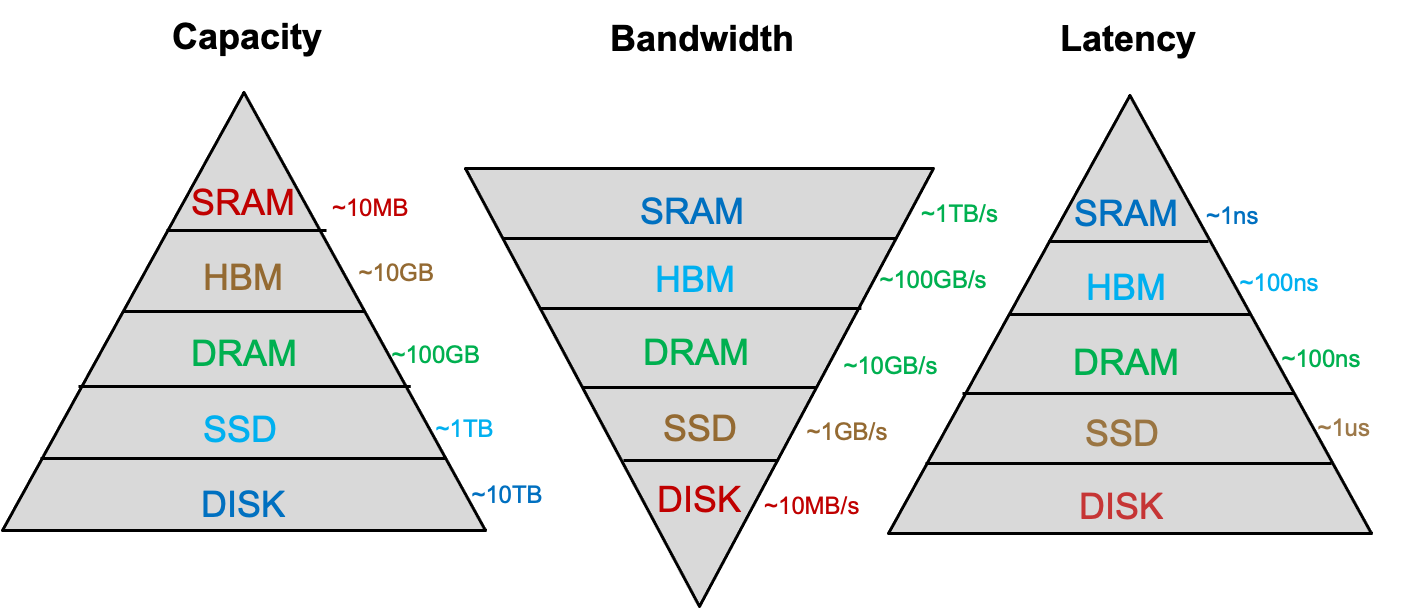
- Flip-Flops
- Very Fast,Parallel Access
- Very Expensive,一个bit需要几十个晶体管
- SRAM
- 相对快,only one data word at a time
- 贵,一个bit需要6+个晶体管
- DRAM
- Slower,one data word at a time,reading destroys content(refresh),需要一些特定的进程,存在数据出错的情况
- cheap,一个bit需要一个晶体管和一个电容器
- Flash Memory
- Much Slower,access takes long time,很慢,non-volatile非易失性
- Very cheap,一个晶体管可以存储16bit
SRAM
Cerebras‘s Wafer Scale Engine(2019)
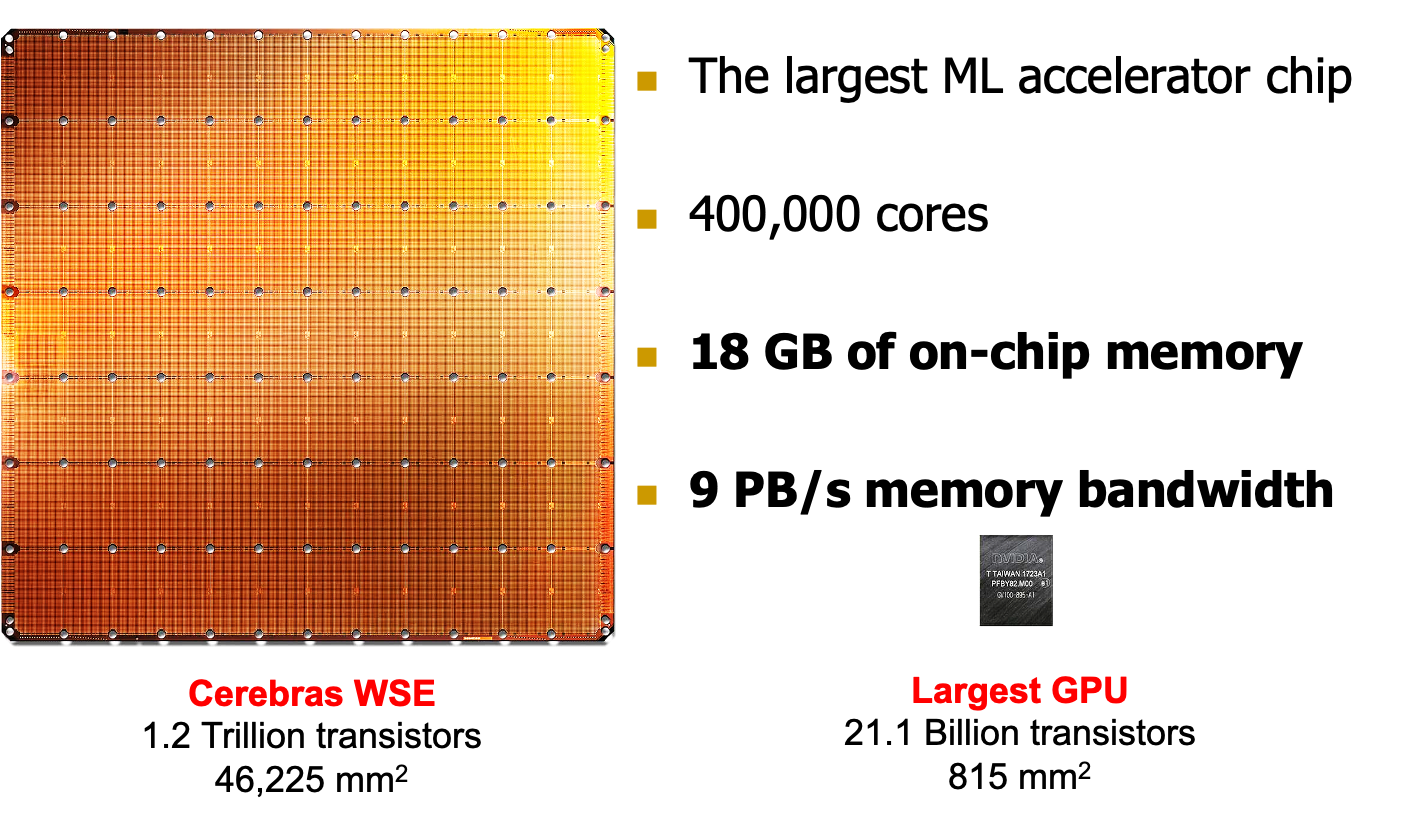
SRAM和DRAM都是内存,其访问方式如右图
- Goal:buffering data on chip,减少外部的访问
- Advantage:随机访问有高性能
- Disadvantage:low capacity(MBs)
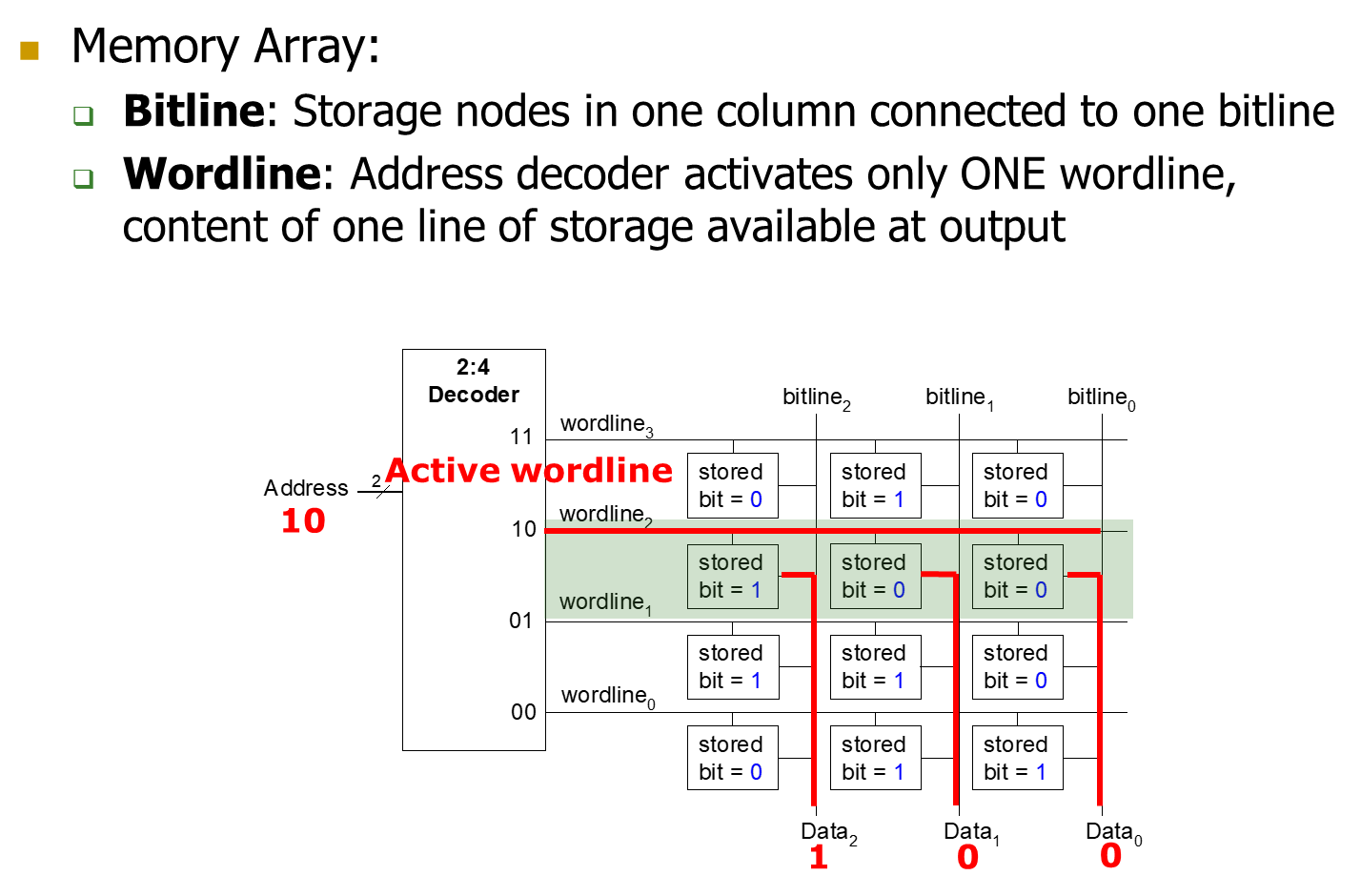
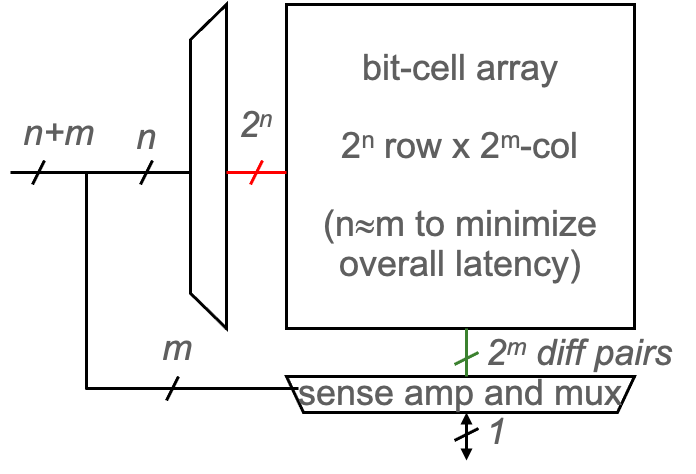
Memory Arrays
输入N位地址,输出M位带宽的数据(一个word)
- Goal:高效地进行大数据的存取
使用了Memory Arrays,取都是取一行one row出来的,即M位的数据
- 一个m位值可以在每个唯一的n位地址上读或写
- 所有值都可以访问,但一次只能访问m位
- 访问限制允许更紧凑的组织

比如一个N地址位M数据位的Array
- 有\(2^N\)个行,和M个列
- Depth:深度就是行数,即word的个数
- Width:带宽就是一个word的位数
- Array Size = Depth*Width
Bit Line & Word Line
SRAM和DRAM的内存阵列组织形式是一样的,只是bit的存储方式不同。

- Where to Use SRAM?
- Cache in CPU
- Shared Memory in GPU
- On-Chip buffer in AI accelerator
- How to Use SRAM
- Multiple small separate SRAMs:低延迟和高吞吐率
- Banked Design:wide access ports
Memory Banking
- Memory被分为了很多个bank,每个bank可以独立访问
- 每一个bank每个周期都可以访问一次
- 可以同时进行N次协同的访问,如果有N个bank
即,把同一个地址输入到N个Banks中,每一个bank返回一个word/bit,最后进行选择,从而同一周期获得更多的数据,下面是一个bank,有row buffer
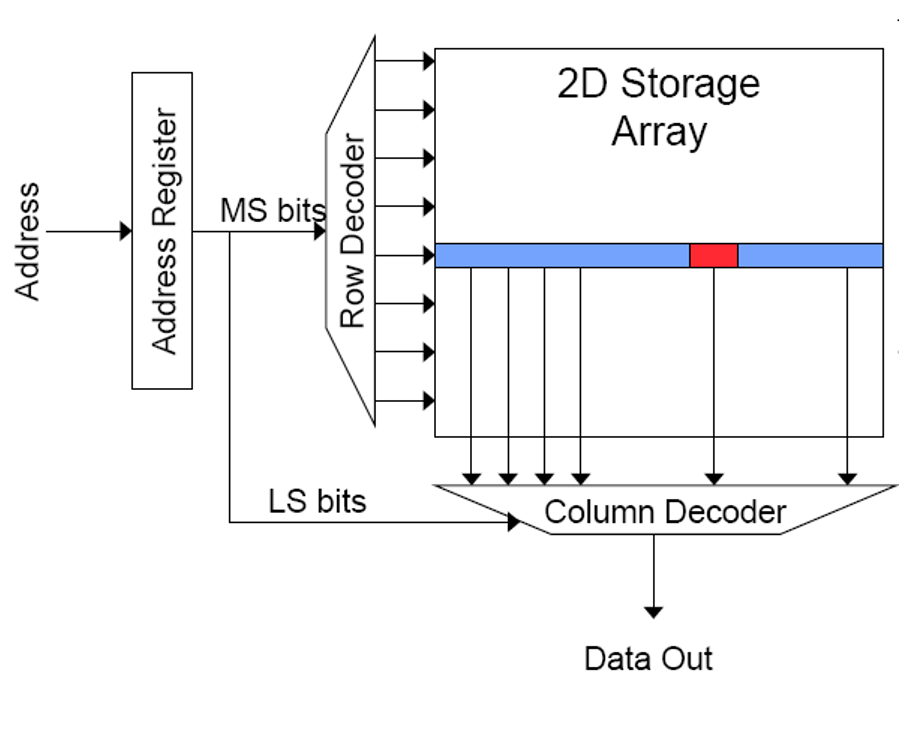
Read Sequence
Address decode:解码地址,获取word-lines
drive row select:选择读取一个Row
selected bit-cells drive bit-lines,选择好的bits被送上bit-lines,一整行进行读取
Differential sensing and column select,选择column
pre-charge all bit-lines
HBM&DRAM
- Motivation and Goals
- 应用视图Application Perspective
- 性能视图Performance Perspective
- 可靠性视图Reliability Perspective
Main Memory System
main memory是计算系统中最重要的组成部分
main memory系统必须scale:size、technology、cost、efficiency
Application Perspective:
目前都是内存存在瓶颈:Memory带宽、容量
- Important workloads
- 需要更快和更高效的大数据处理方式
- Data is increasing
Performance Perspective:
从性能角度出发,DRAM也是很重要的。Cache的访问速度慢,miss rate高。
CPU的周期被bound在cache,在等内存回数据
Energy Perspective:
内存访问的功耗很大
增加计算,减少内存访问是很好的趋势。我们需要减少对内存的访问。
Memory对功耗的要求很严格,大部分的功耗都在data movement上。
Reliability Perspective:
容量越大,出错的概率更大。
DRAM
我们的目标是大容量、bandwidth,没有latency
- Capacity:18年增长了128x
- Bandwidth:20x
- Latency:1.3x
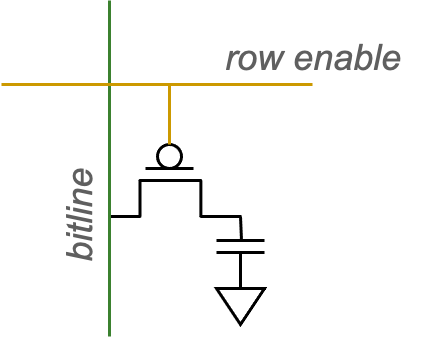
Dynamic Random Access Memory
- 电容器充电状态表示存储值
- 电容器充电和放电表示了1和0
- 1个电容器和1个晶体管
- DRAM cell loses charge over time,电荷会流失
- DRAM cell needs to be refreshed,需要recharge
Bank
Goal:需要更大的内存阵列
Challenge:大内存意味着更慢的访问,我们能否在不降低访问速度的情况下进行大内存的访问?
Idea:将内存划分为更小的阵列,并将阵列连接到输入/输出总线
Architecture of DRAM

有很多的Channel。
- Channel是并行的,但是DIMM是串行的,每次只能访问一个DIMM
- Memory Channel是内存接口
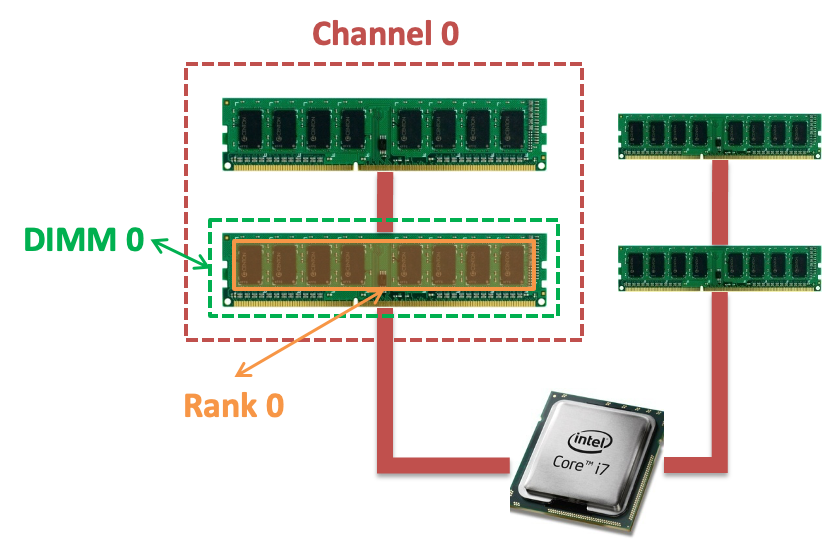
一个DIMM有正反两面:每面都是一个RANK
- 一个芯片的容量一般是固定的,芯片越多容量越大
- 两个RANK是串行的
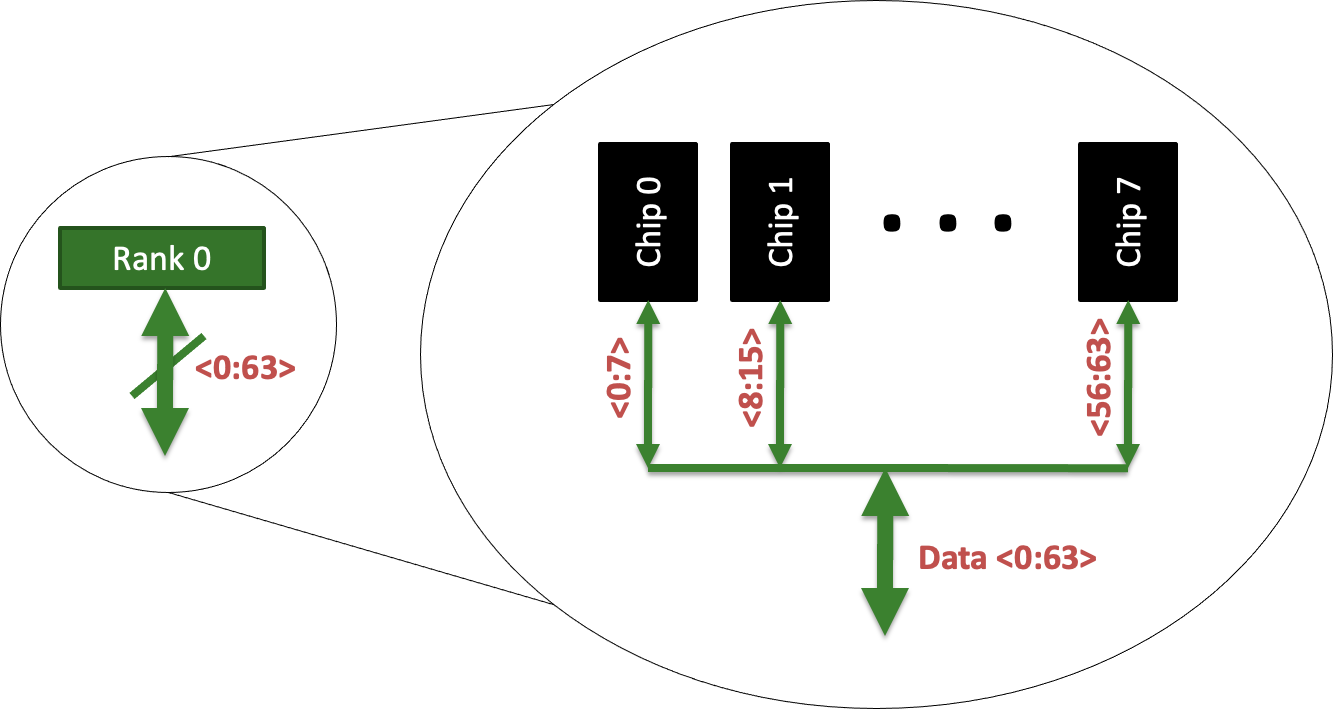
每一个RANK上面有Chips
- 比如8G有8个chip,实际会更多,有ECC校验的芯片
- chip是并行的
每一个chip中有很多的Bank
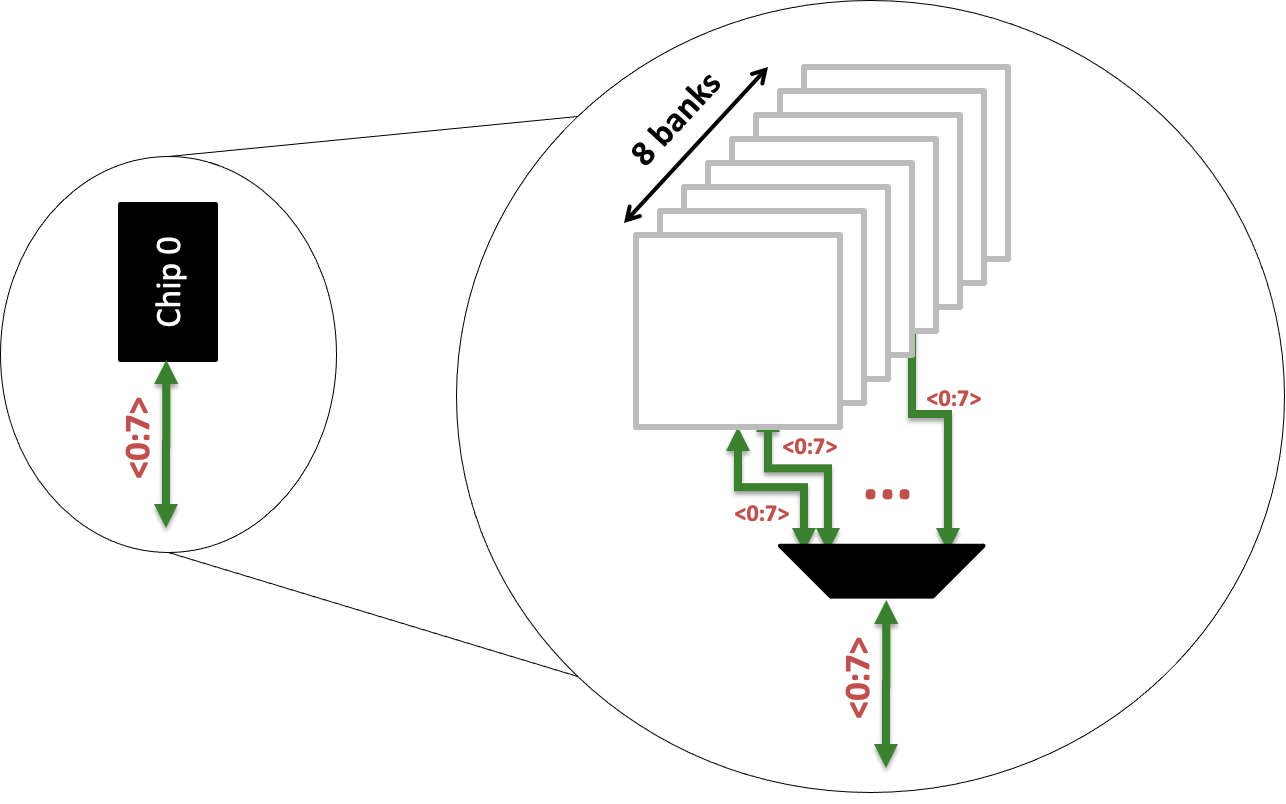
Bank的拆解
- Row-Buffer,需要提高hit概率,从而提高带宽,因此DRAM要有顺序访问,提高hit
- 下图的一个col是1bit,不是1B?col大小是可以变的?
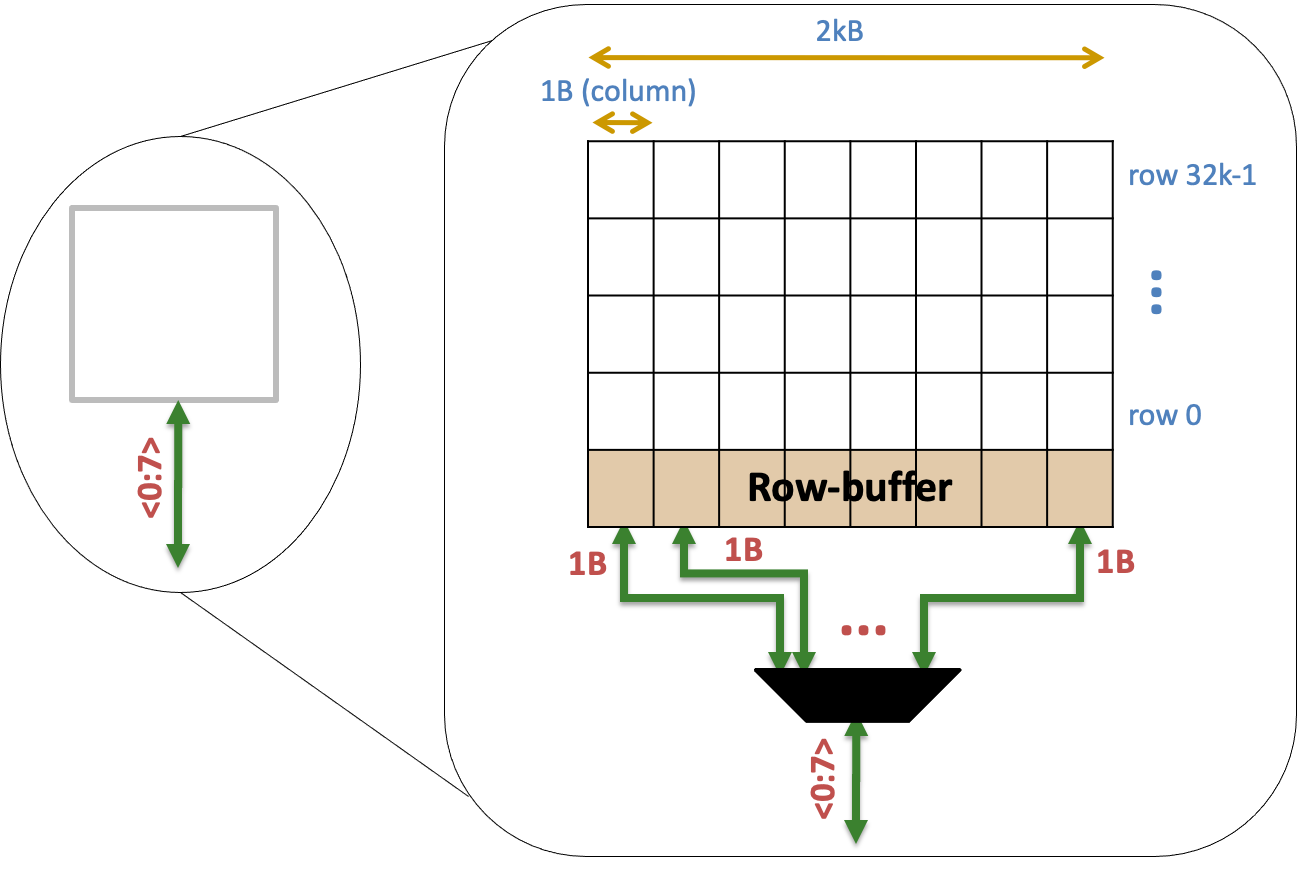
由于每个 rank 由许多 chip 组成,1 个 chip 仅负责部分的资料读取,chip 接收到位址讯号后,将位址丢入内部的 row/column 解码器找出相对应的 bank 位址(每家每款产品的内部 bank 组合有可能不同,因此对应也会有所不同),接著开启 row 线,同 1 排 row 的内部资料就会流到 row buffer 内部,row buffer 判断讯号为 0 或是 1 之后就输出资料。
Transferring a cache block
假设一个cache block为64Bytes
每次从8个chip上表面读一个Byte,concat获得8B
一共需要8个周期
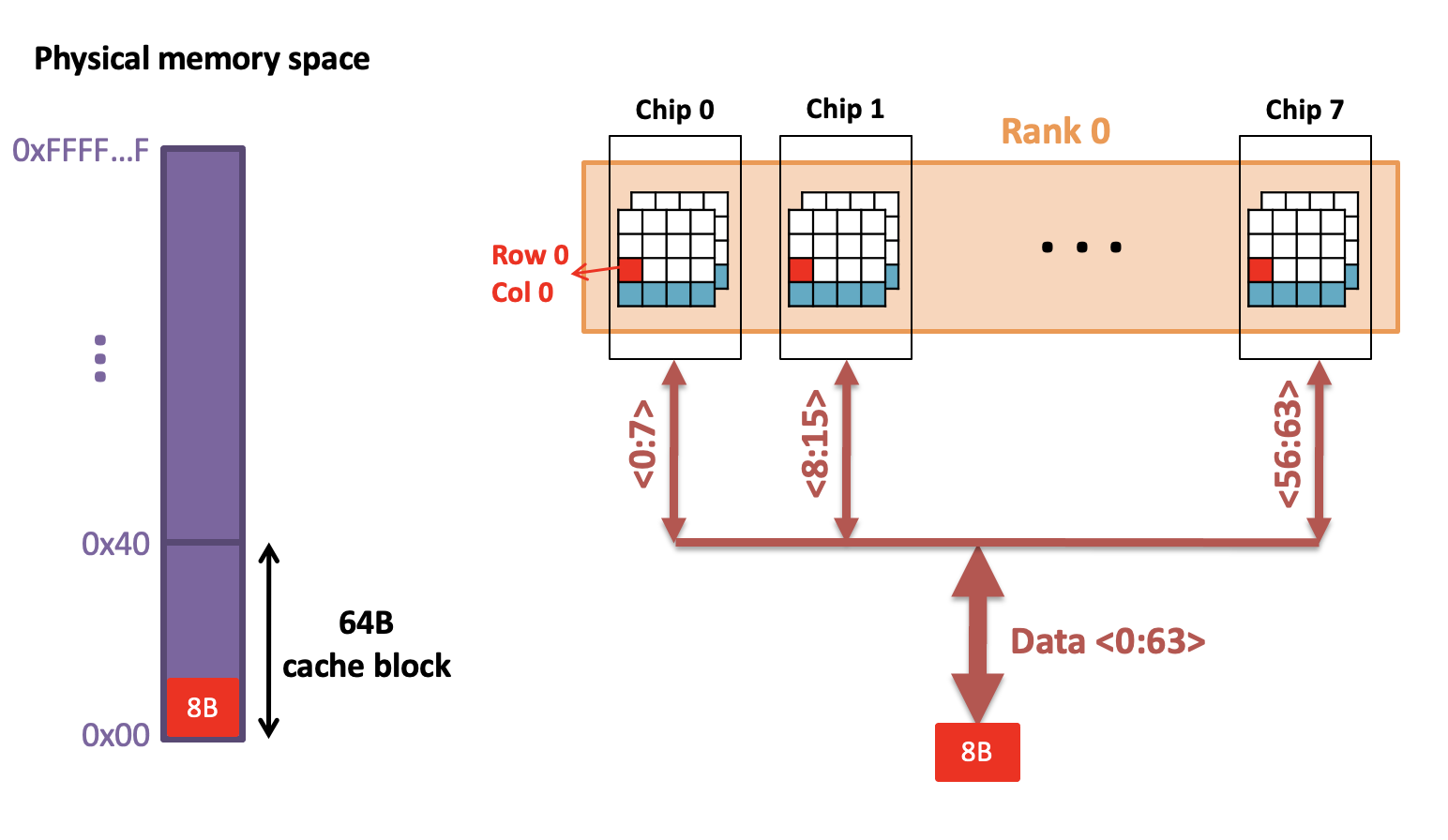
Address Bits of Memory
SRAM
- SRAM总是与计算单元存在于同一芯片中。
- 由于容量小,地址位数量相对较少。
DRAM
DRAM的数据访问不是一个Address就足够,需要多个地址,要channel、DIMM、rank、chip等等的地址。
- DRAM与计算单元是分开的芯片,因此由于物理限制,pin码可能成为瓶颈。
- 由于内存容量大,直接映射的地址位数量多
- 而数据是暂存在Row Buffer的因此顺序访问的效率很高
SSD
Disk
Lecture 7 Graphics Processing Units
GPU
KeyMessages
- 编程模式是英伟达成功的关键,而不是GPU本身。
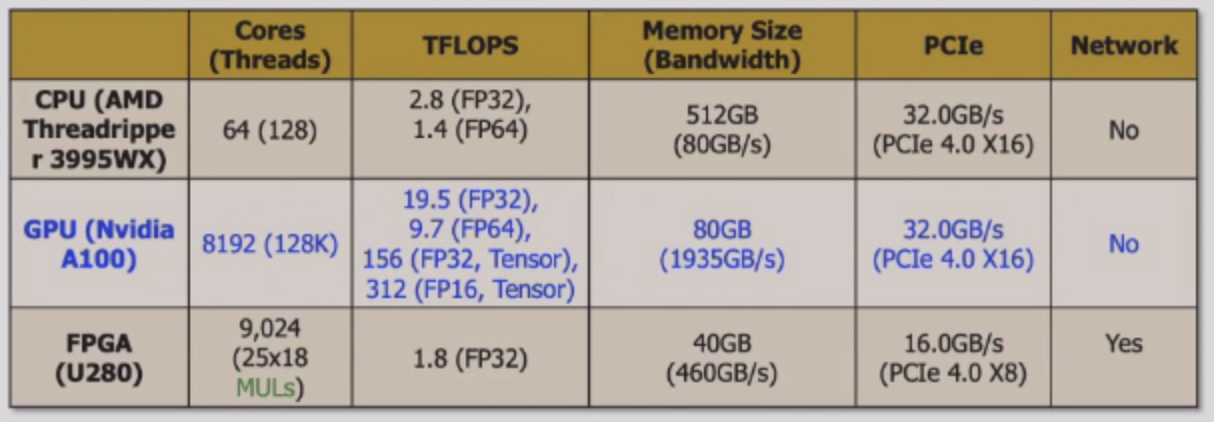
- GPU的内存带宽和计算能力都比CPU高一个数量级。
- 只有当任务具有足够的计算强度时,才会将任务卸载给GPU。
- AI任务需要计算密集型的加速器,例如GPU和AI处理器。
GPU:本质是many-core的,与multi-core不同。multi-core是CPU,many-core是GPU个数更多。
核之间并行,核内也有很多的thread在跑(SMT)
- 我们为什么用GPU?
- 更大的算力
CPU vs GPU
- CPU
- Few complex cores
- 控制复杂,能够进行更多的工作
- Larger cache for low memory latency
- Large and slow memory
- Few complex cores
- GPU
- Lots of simple cores
- 执行简单的、并行度高的计算,不擅长精巧的计算
- small cache for low memory latency
- small and fast memory
- Lots of simple cores
- CPU和GPU之间的关系
- 数据通过PCI Bus或者PCIe Bus进行传输
- GPU是CPU的下游计算端,控制流都在CPU中,GPU干的是简单的活
More Cores,更多的核,带来了更多的问题:如何管理这些核?
Programming Model
- CPU-GPU Co-Processing
- CPU:串行的代码和不是很并行的代码
- GPU:处理并行的代码

CPU会有驱动代码调用GPU。
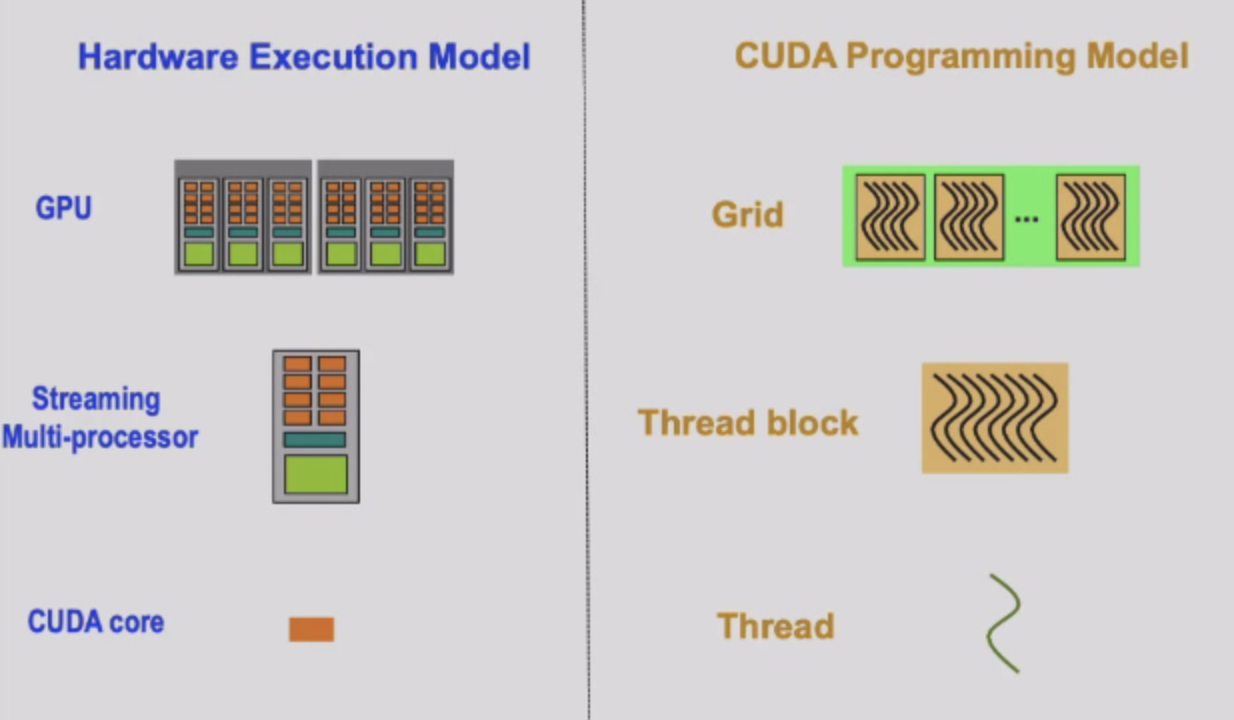
GPUs are SIMD Engines Underneath
- 指令pipeline操作是SIMD类似的pipeline
- 但是Programming是使用threads完成的,不是使用SIMD指令
- Programming model VS Execution model
- 我们不能让用户改代码,我们需要改进硬件的执行方式
- 编程模型和执行模型
Programming Model
- 编程者表达code的方式
- Sequential,Data Parallel(SIMD),Dataflow,Multi-Thread(MIMD)
Hardware Execution Model
- 硬件如何执行代码的方式
- OoO Execution、Vector Processor,Array Processor,Multiprocessor
- Discussion:执行模式可以和编程模式很不同
- 编程的代码可以在很多的硬件上面都能跑
NVIDIA GeForce GTX 285

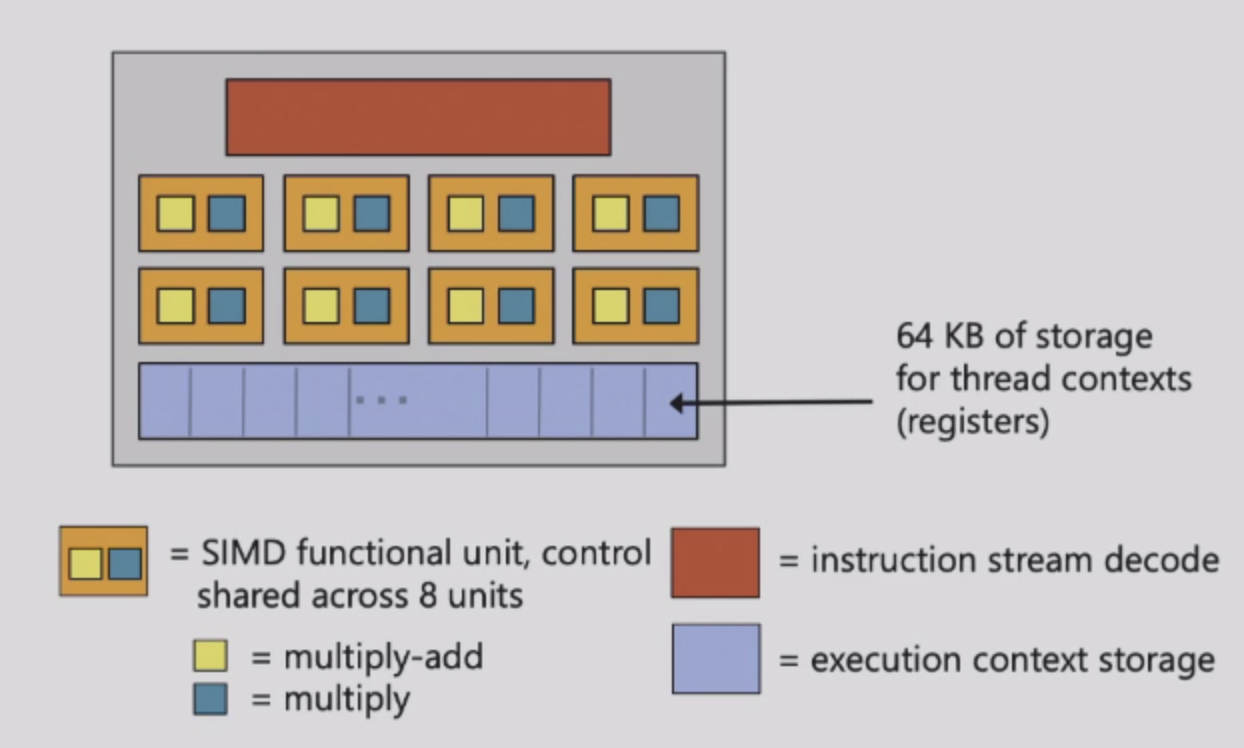

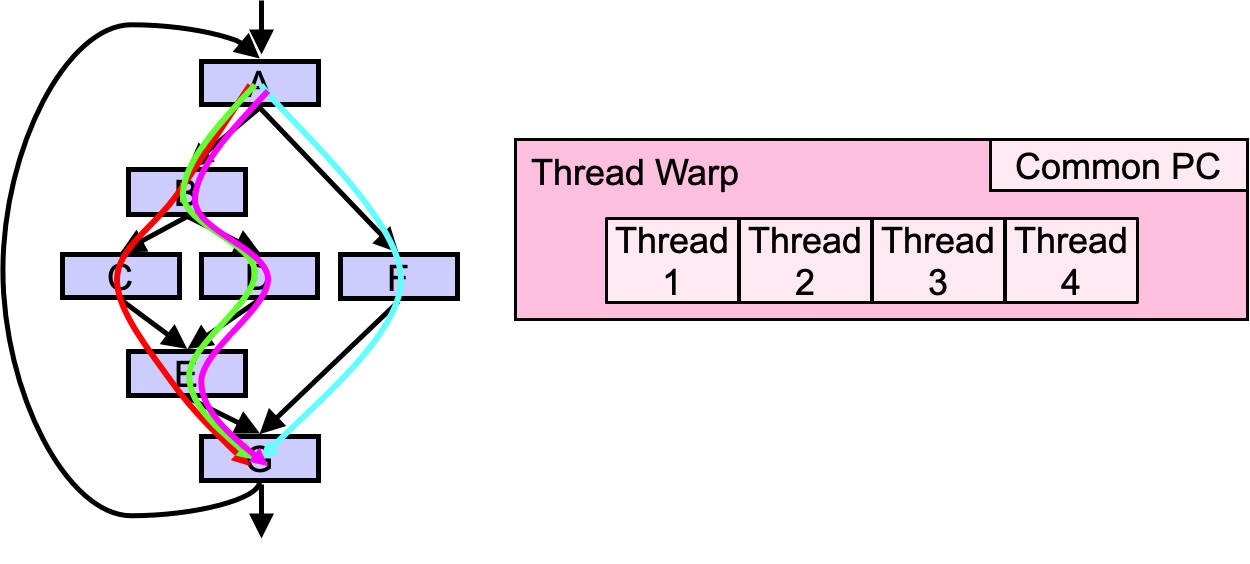
- Groups of 32 threads share instruction stream,每一个group为一个warp
- 32个warp可以同时interleaved
- 1024个thread context能够存储在一个core上
- 8个SIMD计算单元每一个core上
- SM:Streaming Multi-processor
Programming Model
1 | for (i=0;i<N;i++){ |
SISD
- Pipeline Process
- OoO execution Processor
- Superscalar
一条一条执行,load、load、add、store,一直串行
SIMD
以SIMD为2为例子,我们每次可以load两个B[i],两次迭代就变成了一次。
即一次load把B[0]、B[1]读出来了,再一次load把A[0]、A[1]读出。
然后add,把C=B+A,这里的ABC都是二维向量,再进行store
这样,总体而言我们的速度就快了2倍。
1 | # Vectorized Code |
Multithread:SPMD
Single Program Multiple Data
每次的迭代都有一个thread执行,thread1执行第一轮迭代,thread2执行第二轮,这些迭代是独立的,因此可以并行。每个核可以在同一时间内处理一个指令流,那么就可以进行并行
- SPMD的核心思想:多个指令流执行同一个程序
- 每个程序/过程
- 1)处理不同的数据
- 2)在运行时可以执行不同的控制流路径
- 许多科学应用程序都以这种方式编程,并在MIMD硬件(多处理器)上运行。
- 现代图形处理器以类似的方式在SIMD硬件上编程
Hardware is Free to schedule.
不同的设备可以适应编程模型.比如一个编程模型的grid,里面有8个block,一个GPU有2个SM,那么4周期执行完,一个GPU有4个SM,则两周期执行完.
GPU Programming Example
The device executes CUDA kernels
- Grid:里面有很多的Block,对应硬件的device
- Block中有很多的Thread,这些thread共享block的shared memory,独享regs,对应硬件层面的SM
- Thread对应硬件层面的core
- Thread Block
- 一个thread block回去一个SM中,SM中可能对应很多的thread block
Traditional Program Structure
- Function prototype
1 | float serialFunction(...); |
- main()
- Allocate memory space on the
device-
cudaMalloc(&d_in,bytes)
- Allocate memory space on the
device-
- Language
cudaMalloc((void**)&d_in,#bytes)
Sample: Vector Add
用cuda编程,一个thread执行一个加法,有n个thread,n个核,我们需要把thread变成group,n=16
- 我们分为4个block,每一个block有4个thread,所以blockDim=4
- 每一个block中有thread id
1 | void vecadd(float* A,float* B,float* C,int N){ |
- 我们要确保更多的thread投入使用,即
numBlocks = (N+numThreadsPerBlock-1)/numThreadsPerBlock; - 同时要判断数组是否越界,即在GPU的工作中我们需要对i进行判断
GPU的架构
Streaming Processor Array—device
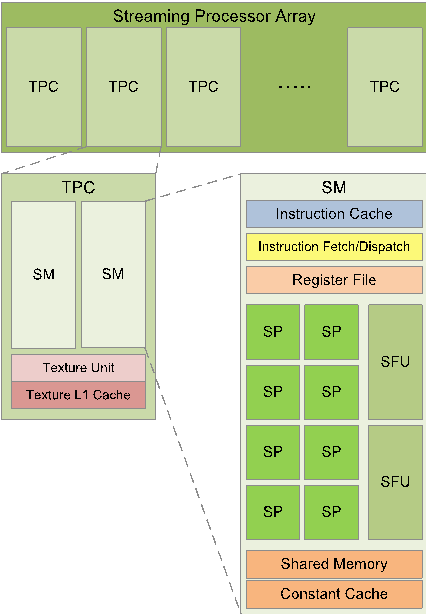
Streaming Multiprocessors(SM)/Compute Unit—block
- Streaming Processor Array下有很多的SM
- block也可以看成分为了很多的warp,warp里是多个core执行SIMD的任务
Streaming Processors(SP)—core
- SM中很多的SP,即/cores
SIMT就是将一些Core进行分组,对应了Warp
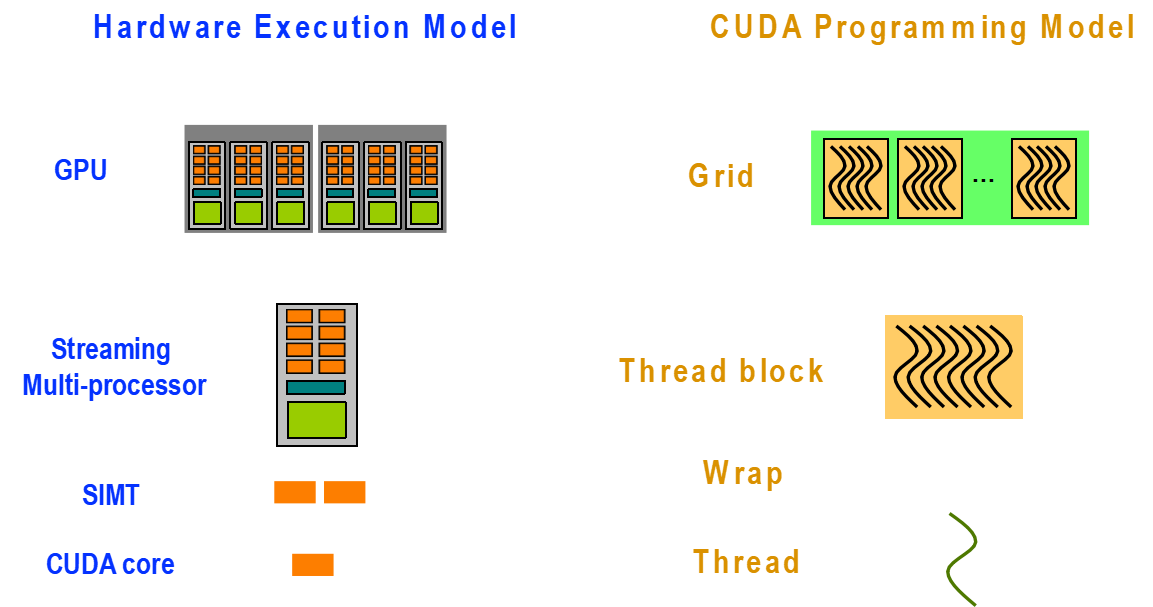
GPU的SIMD不会暴露给Programmer
GPU的Warp也不会暴露给Programmer
SIMD:SIMD指令的单个顺序指令流,每个指令指定多个数据输入
- VLD,VST,VADD等
SIMT:标量指令的多指令流,线程动态分组到warp
- 包装完后每次进入SIMDpipeline都是一个warp进入,SIMDpipeline中有很多的scalar pipeline
- SIMD单元中有很多的core
Lecture 8 GPU optimization
Recall
- Comparison of Memories
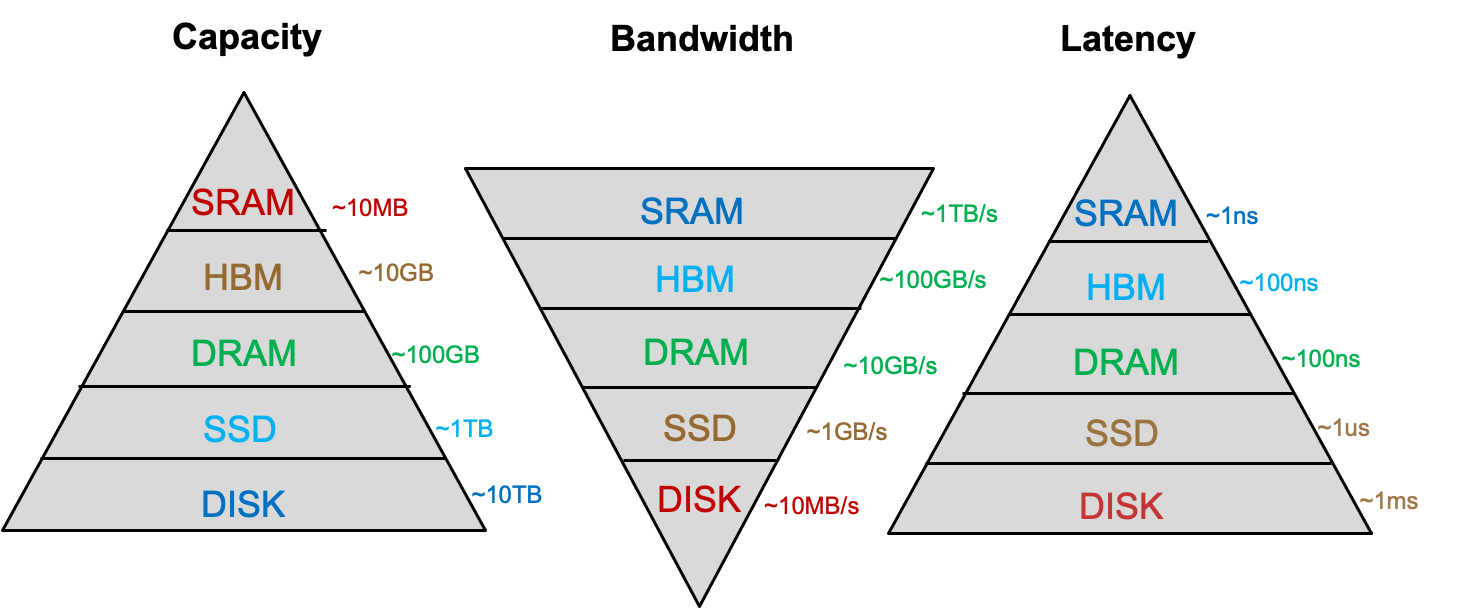
- FF vs SRAM vs DRAM vs SSD
- FF~K:Very fast,parallel access,very expensive
- SRAM~M:相对快,一次只能一个data word,expensive
- DRAM~G:比较慢,一次也一个word,reading destroys content(refresh),cheap
- Flash Memory~T:很慢,访问时间很长,非易失性,很便宜
- SRAM Summary
- SRAM
- Goal:Buffering Data on chip to reduce external memory traffic
- Advantage:可以支持随机访问有高性能
- Disadvantage:Low capacity通常是几MB
- Where to use
- Cache in CPU
- Shared Memory in GPU
- On-chip buffer in AI accelerator
- How to use
- Multiple small separate SRAMs
- Banked design:wide access ports
- SRAM
SIMT & Warp
SIMT是硬件层面上的,Warp是软件层面的
- thread是组成一个warp在里面调度的
- 我们希望一个warp访问顺序的内存地址,只用产生一个DRAM的操作,利用Row Buffer提升性能。
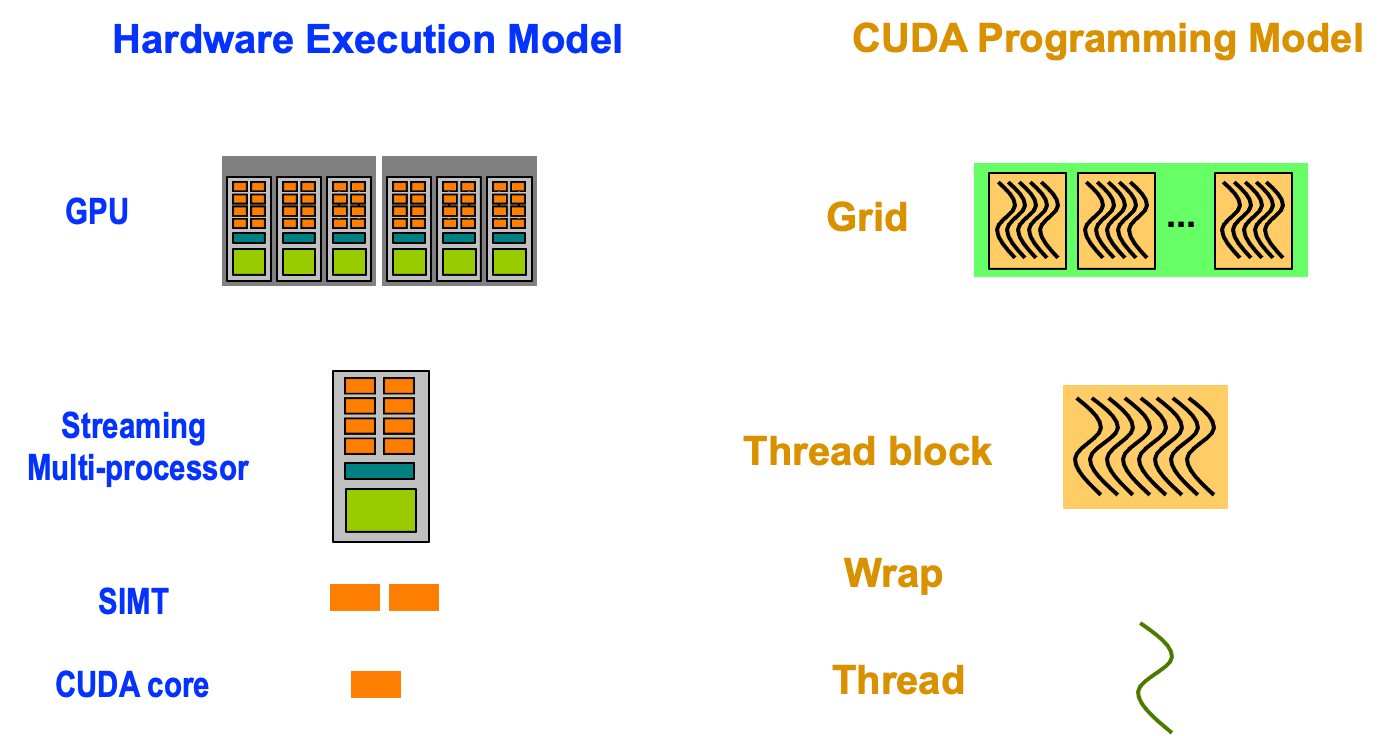
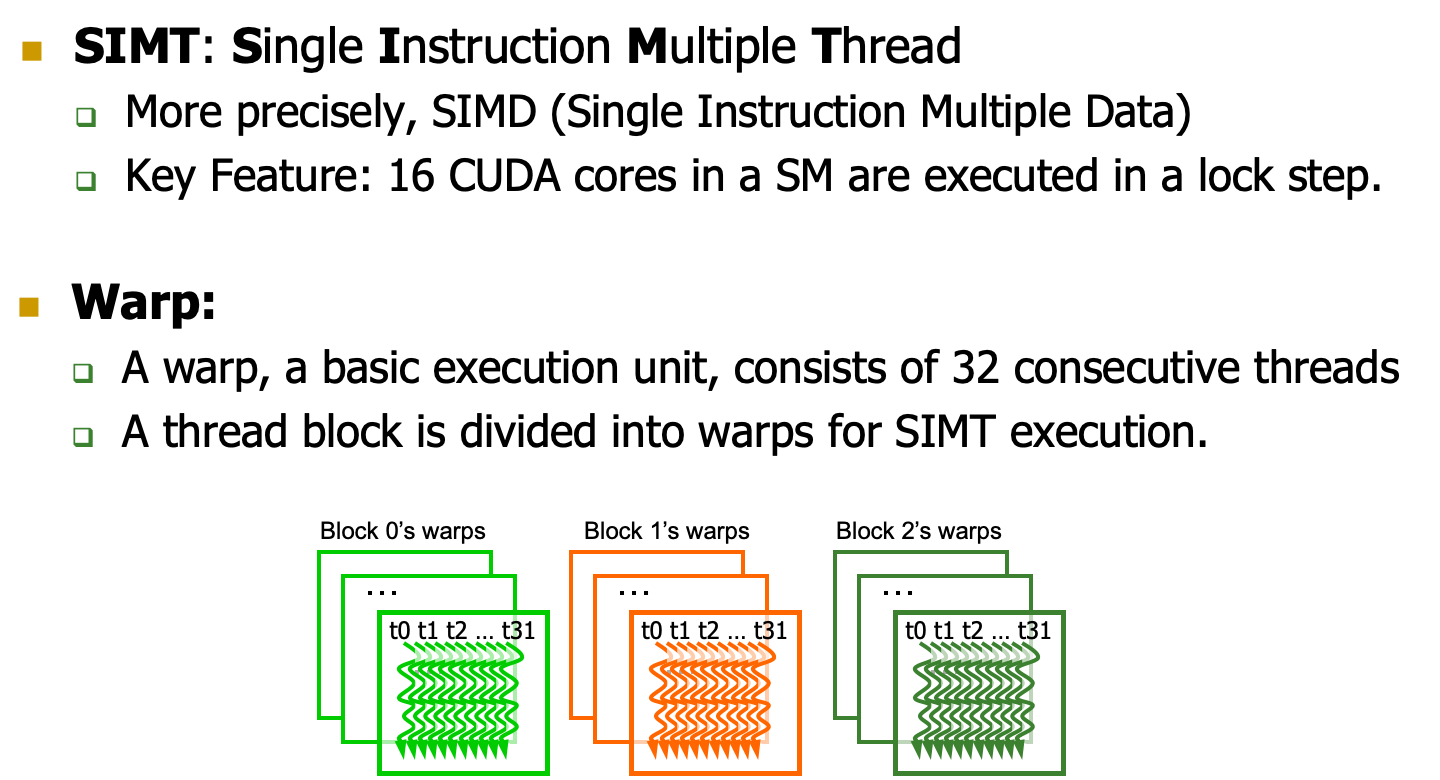
Warp
SM采用的SIMT(Single-Instruction, Multiple-Thread,单指令多线程)架构,warp(线程束)是最基本的执行单元,一个warp包含32个并行thread,这些thread以不同数据资源执行相同的指令。
Optimization
减少全局内存访问
- Multithreading
- Memory Coalescing减少内存访问
- Shared Memory
Multithreading
使用warp的方式
Memory Coalescing
【https://zhuanlan.zhihu.com/p/300785893】
DRAM对于顺序访问更加友好。因此我们希望Warp中所有的线程访问全局内存是连续的。当warp中的所有线程执行load指令时,硬件会检测它们访问的全局内存位置是否是连续的。如果是的话,硬件会将这些访问合并成一个对连续位置的访问。
- 例如,对于warp的load指令,如果线程T0访问的全局内存位置是N、线程T1的位置是N+1、线程T2的位置是N+2,... 则在访问DRAMs时,所有这些访问都会被合并为单个请求。这种合并访问允许DRAMs 以 burst 的方式传递数据。
【Example】
假设我们有两个行优先存储的二维矩阵M, N,要实现一个内核来计算MxN。
内核中的每个线程会访问矩阵M的一行(下面的矩阵A)和矩阵N的一列(下面的矩阵B)。
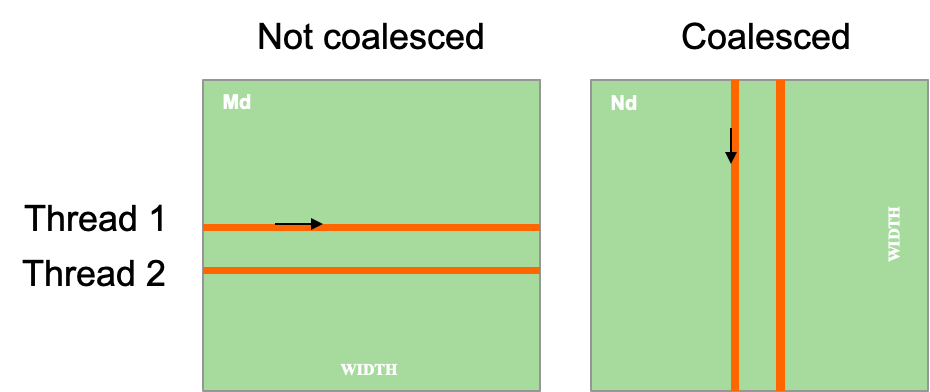
注意:
- Memory Coalescing 合并发生在不同线程的同一周期之间,而不是线程内部的不同迭代之间。
- warp中的所有线程都执行相同的指令,它们在任何时候都在同时执行第k次迭代。因此,一个线程在其生命周期内是否读取整行数据并不重要。重要的是,wrap内的所有线程在每次内存访问时可以合并。
对于M的访存:
- 第k个迭代,Thread i 读取第i行的第k个数据
- 访问不会合并
对于N的访存:
- 第k个迭代,Thread i 读取第k行的第i个数据
- 访问可以合并
Shared Memory
- shared memory:因为shared mempory是片上的(Cache级别),所以比局部内存(local memory)和全局内存(global memory)快很多,实际上,shared memory的延迟要比没有缓存的全局内存延迟小100倍(如果线程之间没有bank conflicts的话)。在同一个block的线程共享一块shared memory。线程可以访问同一个block内的其他线程让shared memory从全局内存加载的数据。这个功能(结合线程同步,thread synchronization)有很多作用,比如实现用户管理的数据cache,高性能的并行协作算法(比如并行规约,parallel reduction)等。
- Bank:bank是一种划分方式。在cpu中,访存是访问某个地址,获得地址上的数据,但是在这里,是一次性访问banks数量的地址,获得这些地址上的所有数据,并逻辑映射到不同的bank上。类似内存读取的控制。
- Shared Memory是一种banked memory
- 一般来说32个banks在nvidia GPU
- 连续的32位word被分配到连续的banks中
- Bank = Address % 32
- Shared Memory Banks Conflict
- 只在warp内部出现
- 为了实现内存高带宽的同时访问,shared memory被划分成了可以同时访问的等大小内存块(banks)。因此,内存读写n个地址的行为则可以以b个独立的bank同时操作的方式进行,这样有效带宽就提高到了一个bank的b倍。 然而,如果多个线程请求的内存地址被映射到了同一个bank上,那么这些请求就变成了串行的(serialized)。
- Data Reuse
- 有些memory locations会被反复访问,因此我们可以将其放入共享内存,下次使用直接从shared memory中取即可。
- 原始的计算方法:
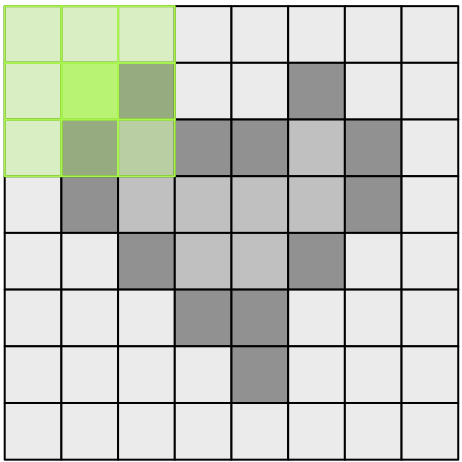

- 使用Data Reuse:Tiling平铺
- 为了利用数据重用,我们将输入划分为可以加载到共享内存中的块tiling
- 这里的高斯卷积是3*3的,因此我们的图像要padding,所以tiling的大小为(L_SIZE+2)^2。
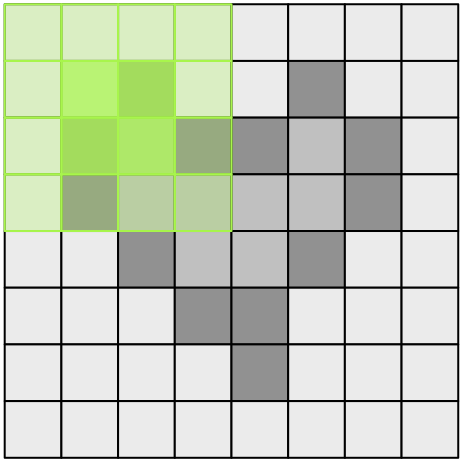

- 矩阵乘法例子
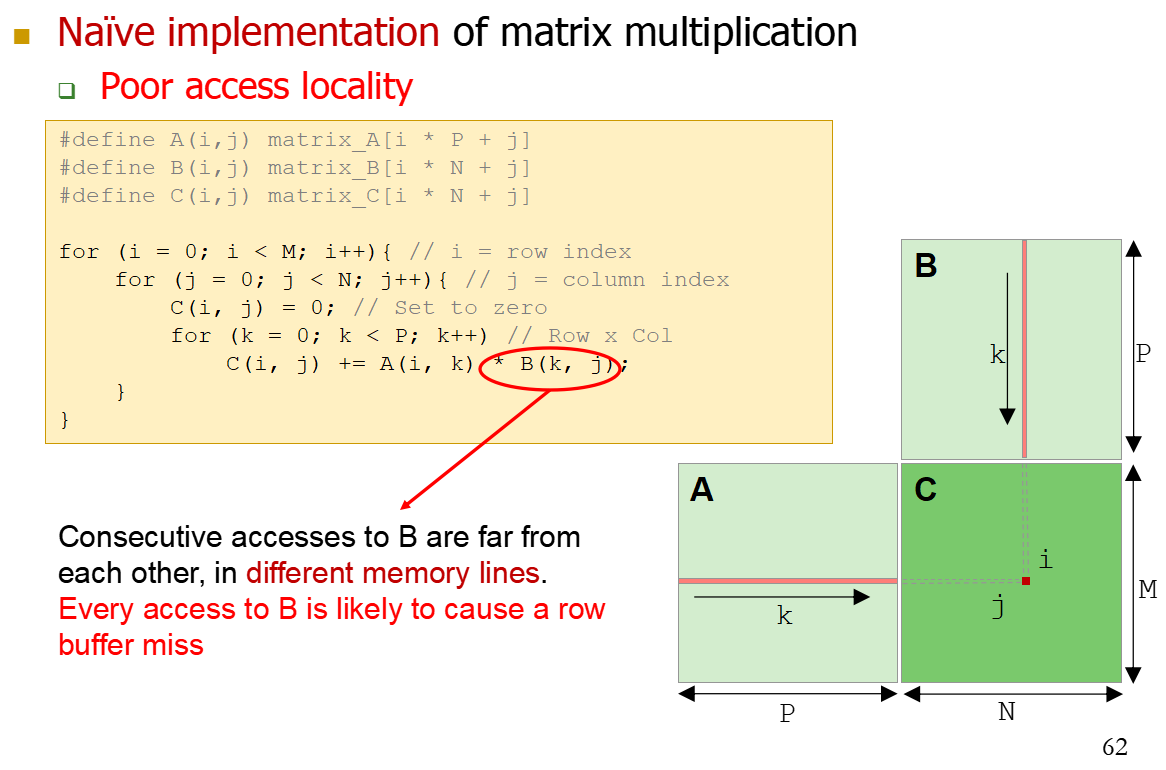
- 用普通的CPU进行矩阵计算如下,矩阵B的读取容易Row Buffer Miss,因为不是Row读入的,A的话会多次Row Buffer Hit。
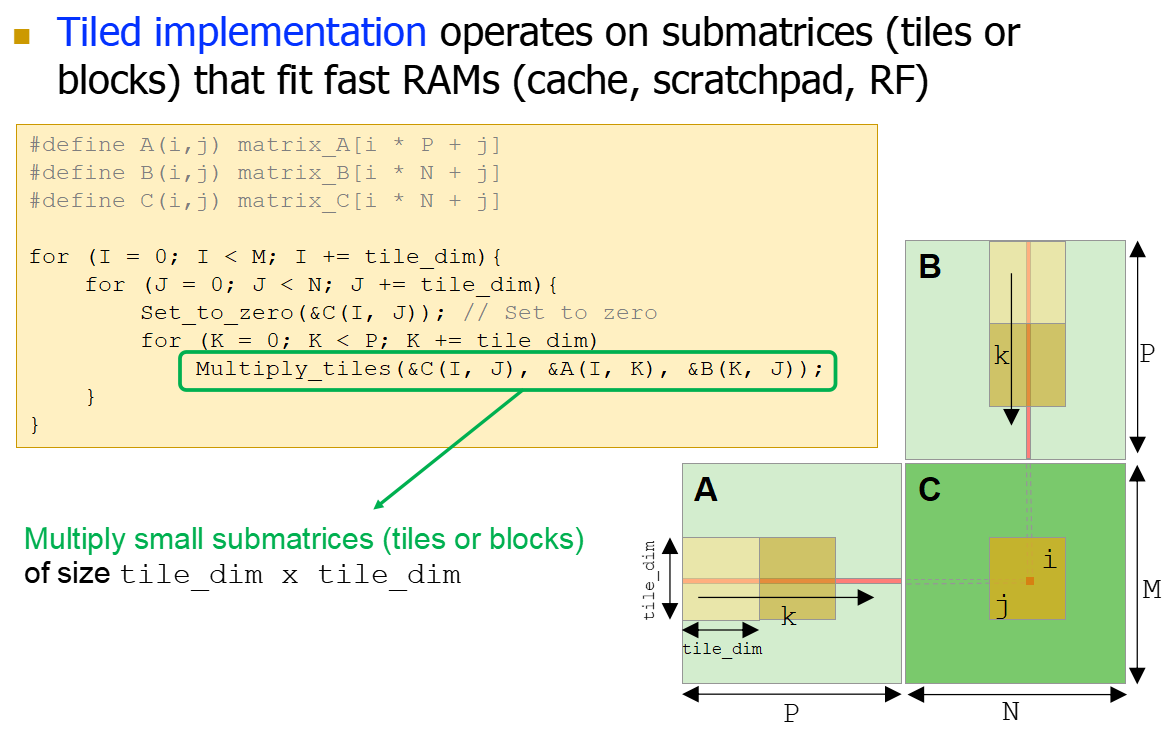
- CPU使用tiled平铺的实现,将子矩阵的乘法放入RAMs更快进行计算
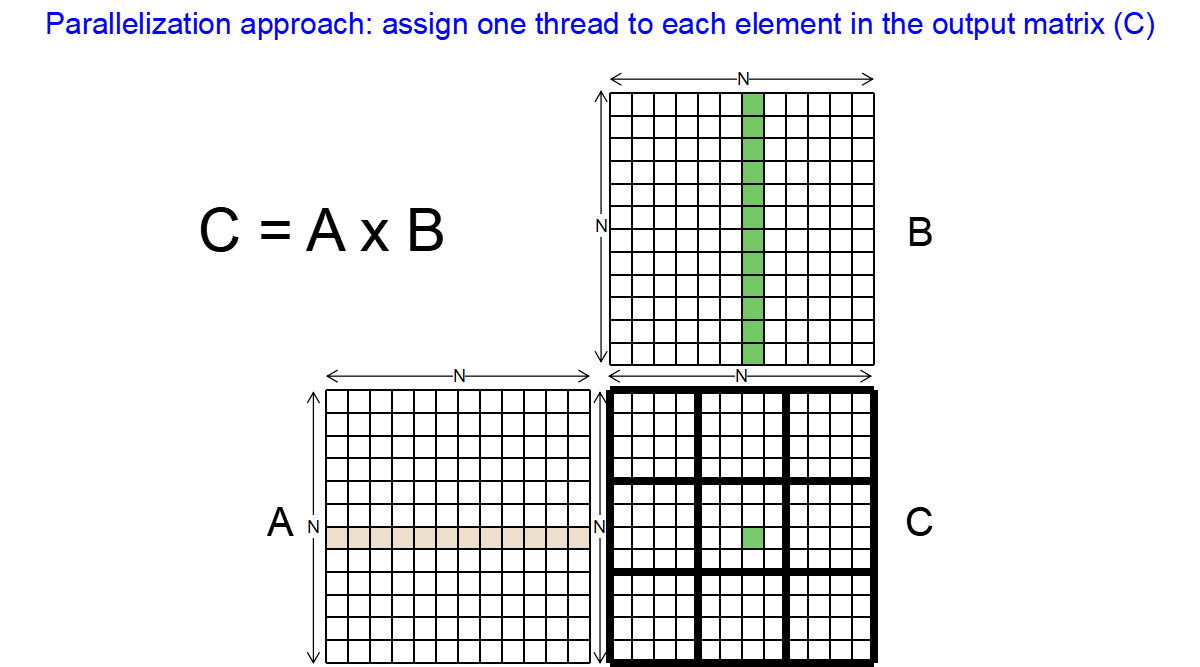
GPU的Matrix-Matrix乘法计算需要计算的C矩阵分为小块,分别计算,每一个元素都可以并行计算
1
2
3
4
5
6
7
8
9__global__ void mm_kernel(float* A, float* B, float* C, unsigned int N) {
unsigned int row = blockIdx.y*blockDim.y + threadIdx.y;
unsigned int col = blockIdx.x*blockDim.x + threadIdx.x;
float sum = 0.0f;
for(unsigned int i = 0; i < N; ++i) {
sum += A[row*N + i]*B[i*N + col];
}
C[row*N + col] = sum;
}
可以使用Reuse,因为并行计算过程中有些thread的需要读取的值是一样的,比如下图C绿色部分的计算都要B绿色部分的值
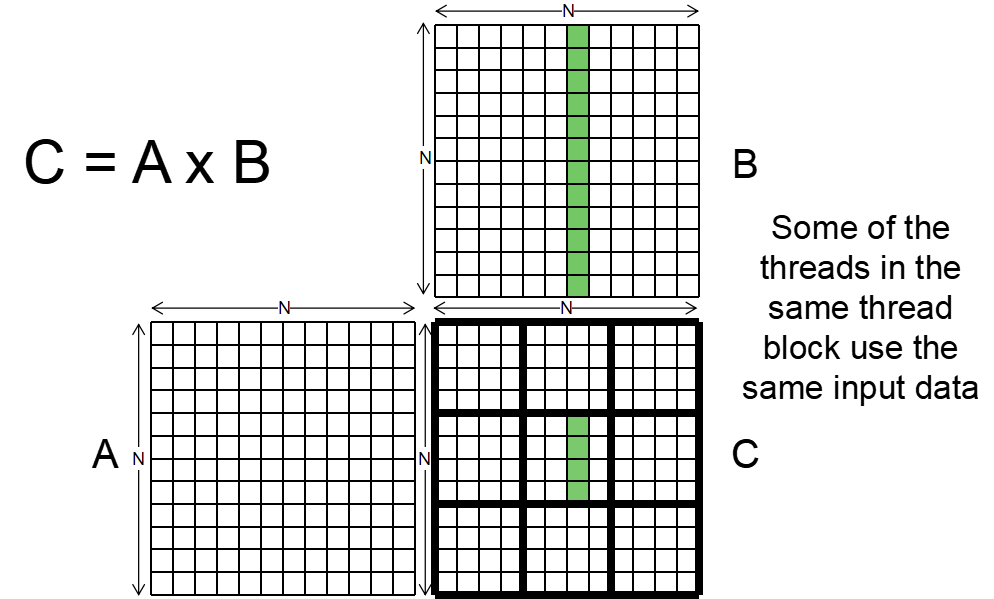
GPU用同样可以使用Tiled,进行平铺,把每一个小块进行乘法最后相加
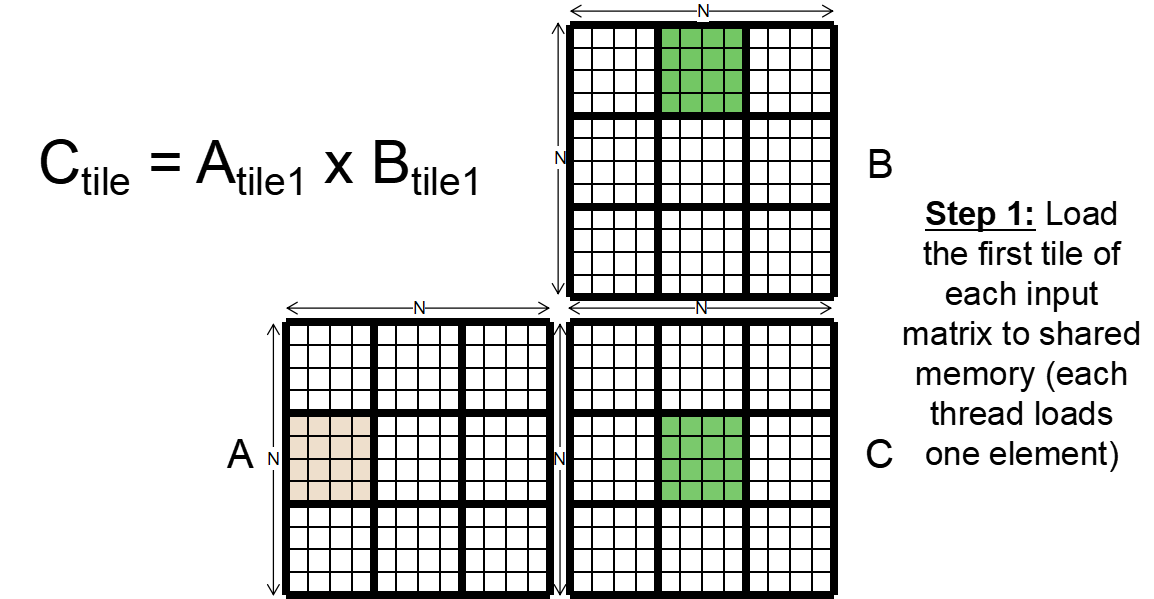
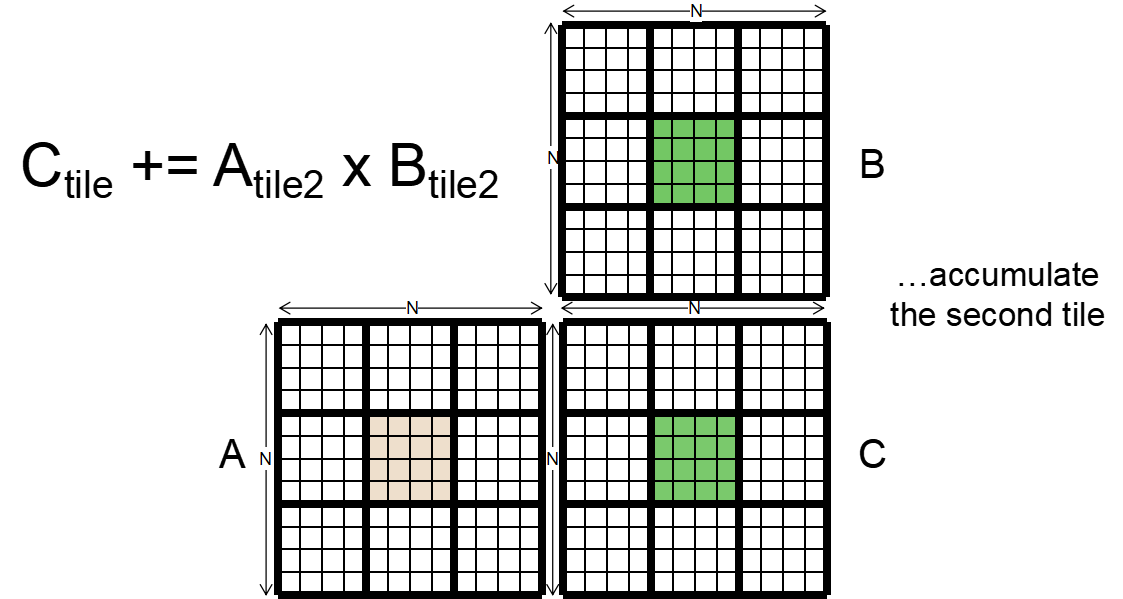
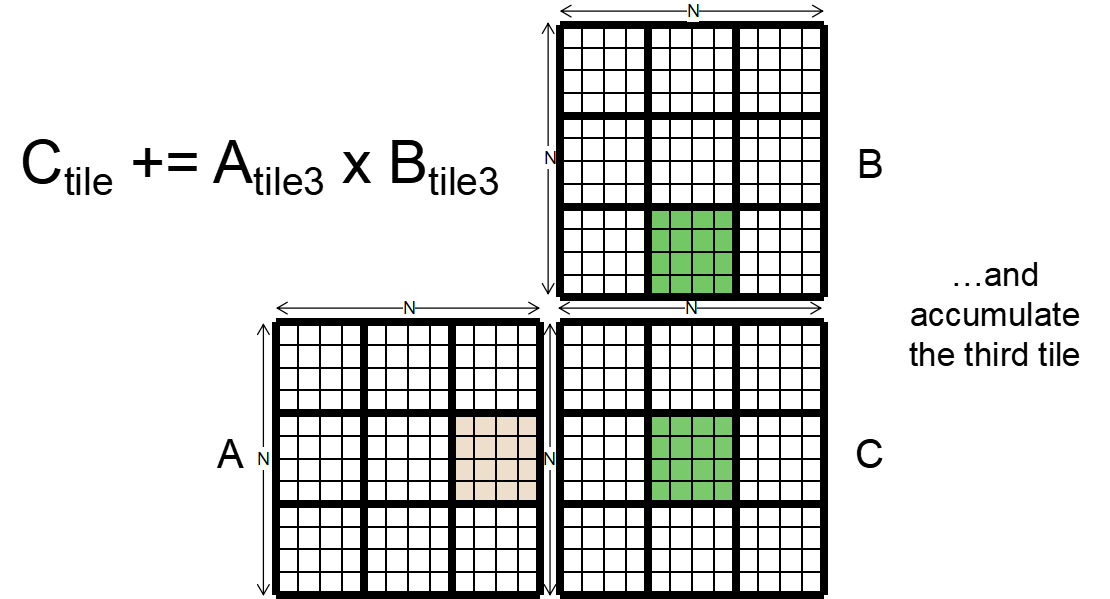
- Synchronization Function
void __syncthreads()- 同步block中的所有线程
- 一旦块中的所有线程都到达这一点,执行就会正常恢复
- 用来解决RAW、WAR、WAW hazard
SIMT Efficiency
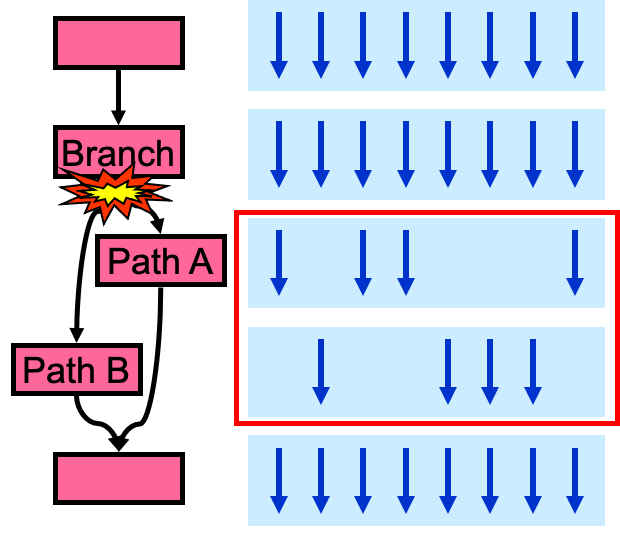
Divergency
- 每一个thread可能有不同的控制循环逻辑,因此尽管用的同一套指令,但是难以并行。
- threads 能执行不同的控制流
- GPU用的是SIMDpipeline节省control
logic,因此我们最好让相同控制逻辑的thread放在一个warp中
- 我们知道GPU是SIMT架构,warp是GPU调度的基本单元,也就是说一个warp中的threads执行同一条指令,并且每个thread会使用各自的data执行该指。
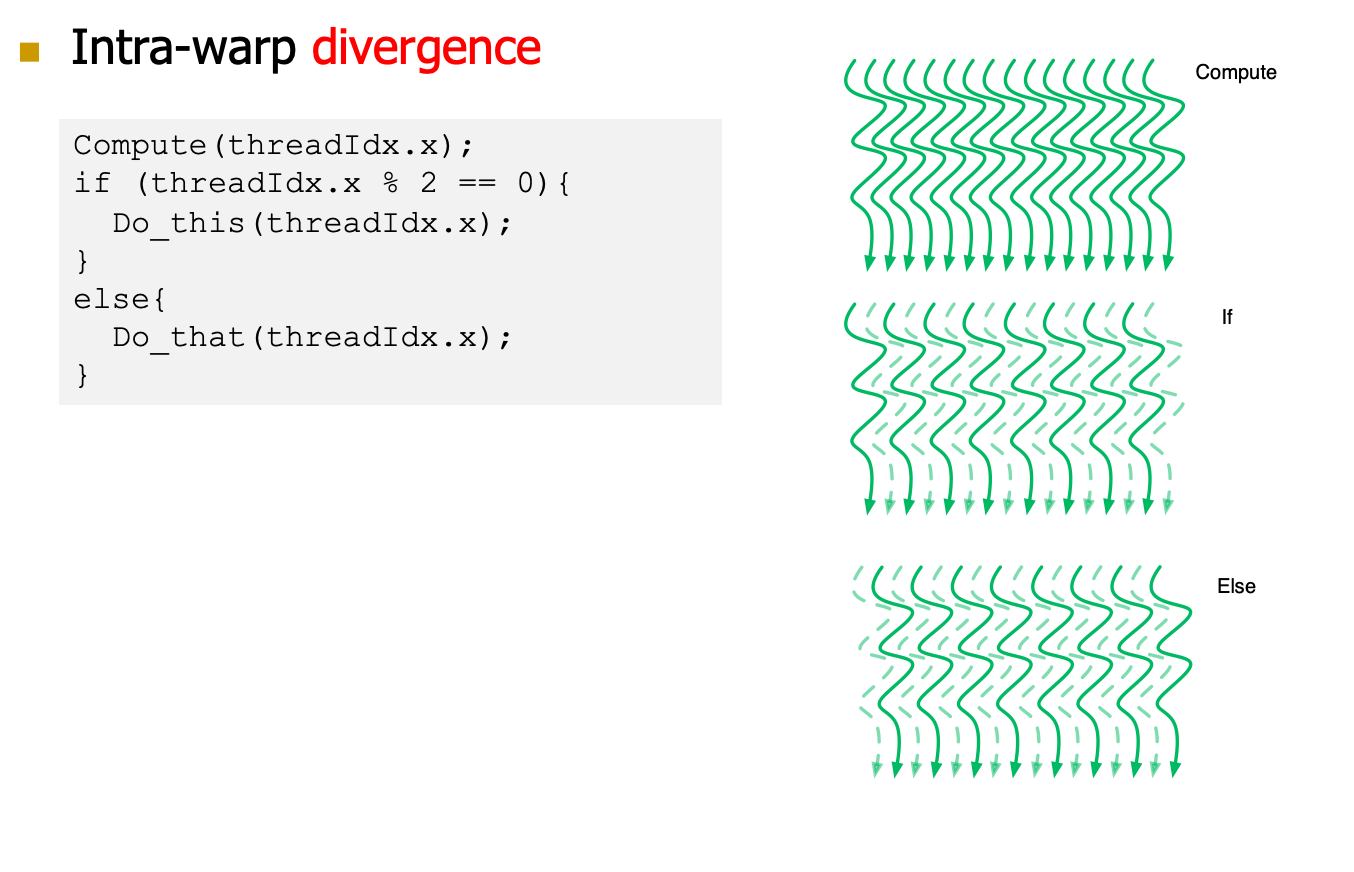
- 那么问题来了,遇到分支语句如if…else,for,while,如果这些线程遇到这些控制流语句时,如果进入不同的分支,同一时刻除了正在执行的分之外,其余分支都被阻塞了,十分影响性能。这类问题就是warp divergence,如下图所示。为了获得最好的性能,就需要避免同一个warp存在不同的执行路径
- SIMT每个周期只能执行一条指令,我们怎么并行执行conditon branch指令
- branch本身没有问题,我们只要保证同一个warp执行同一个指令就可以
- 那么假设我们的warp中部分的指令执行了A部分执行了B,那我们直接分步执行然后最后merge起来即可。
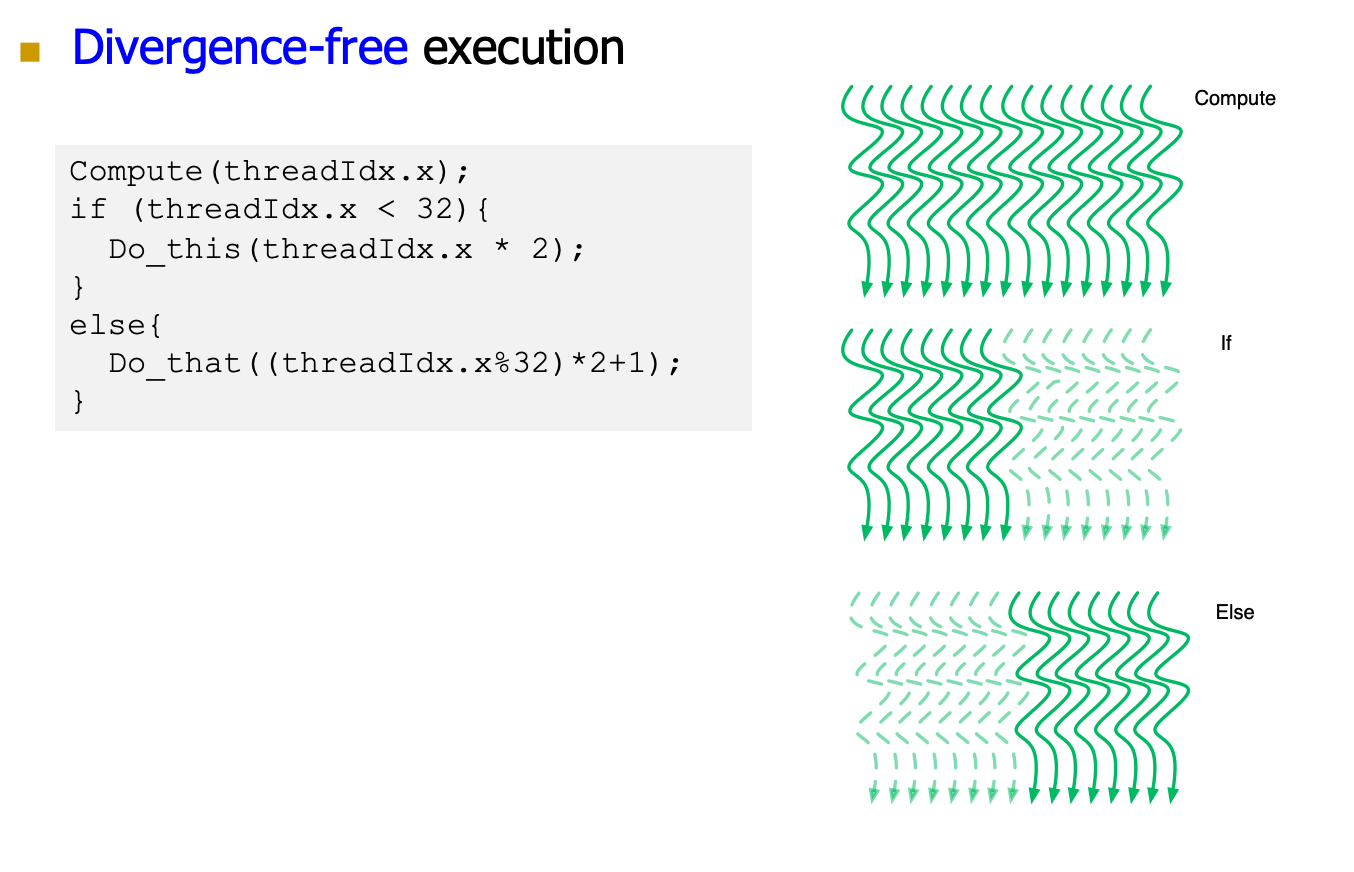
为什么Divergency-Free的SIMD利用率更高?因为相同的控制逻辑的thread warp分在了一起,而第一种的thread是隔开的,一个warp加入都是32thread,那么第一个的SIMD使用率只有50%,第二个是100%。第二个同一个warp的thread的执行路径一致性强!
Atomic Operations
CUDA提供了原子指令在shared memory和global memory上
- 它们自动执行Read-modify-write操作
Arithmetic Functions
Add sub max min exch inc dec CAS

Bitwise Functions
- And or xor
比较讨厌有bank conflict的情况,比如我们要访问0和2,访问2和2的比较,一个是并行的一个是串行的。这种有conflict的时候叫做Atomic conflict
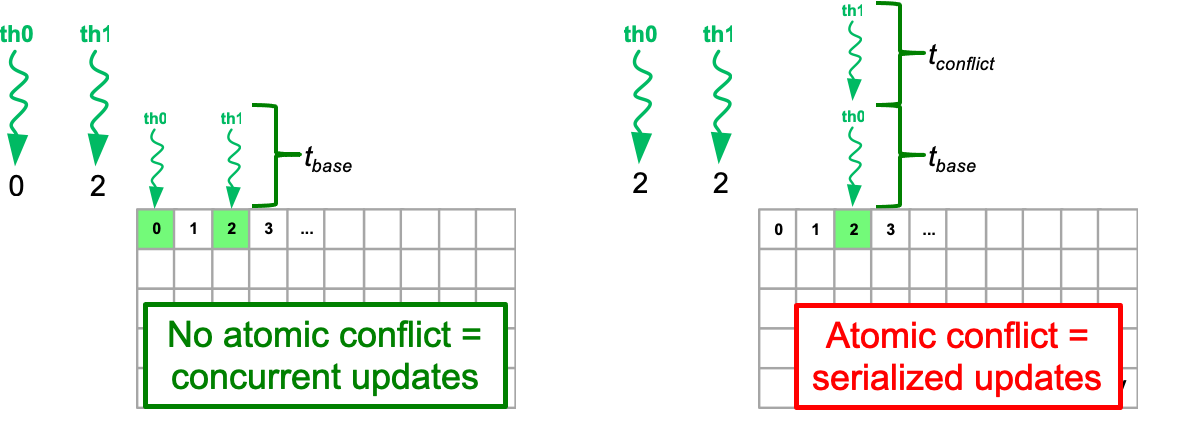
当多个线程需要更新相同的内存位置时,使用原子操作来防止数据竞争
Image Histogram
直方图在图像处理中有广泛的应用
- 在直方图中投票之前可能需要进行一些计算
CPU和GPU的通信
CUDA Streams
按顺序执行的操作序列
- 数据传输CPU-GPU
- 内核执行
- D个输入数据实例,B个blocks
- #Streams: (D/ #Streams)数据实例,(B/ #Streams)块
- 数据传输GPU-CPU
通信和执行我们希望可以尽量快速执行,而不是完全并行。就是一边IO一边计算执行。
原来需要的时间为\(t_T+t_E\)
- 当\(t_T\)占主要时间,Stream执行下的时间\(t_T+t_E/ \#Stream\)
- 当\(t_E\)占主要时间,Stream执行下的时间\(t_E+t_T/ \#Stream\)

GPU Limitation
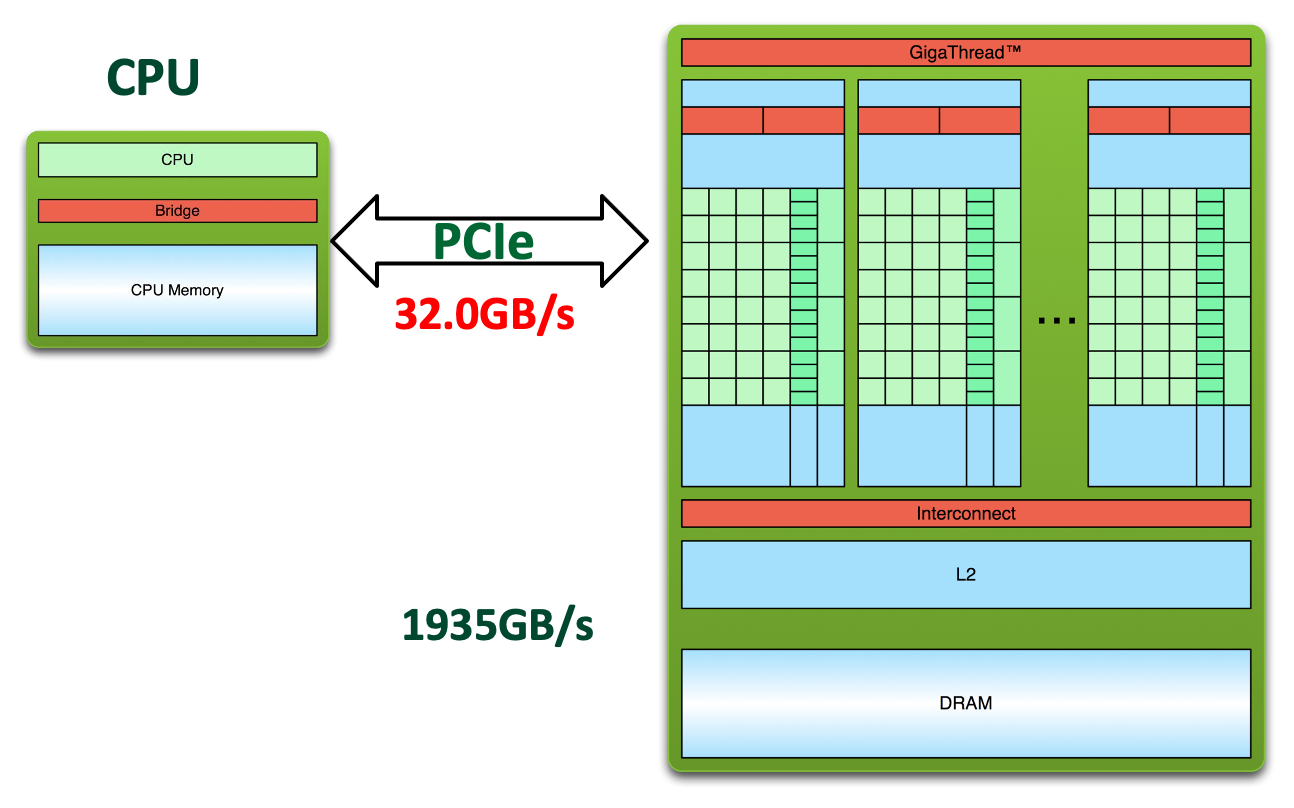
- PCIe的口通信很慢
- GPU并行编程,本质有一个overhead
Lecture 9 Cache
Recall
GPU Programming Model & CUDA Programming Model
Software:warp之内的thread需要分叉少、访问内存连续等特点,才能发挥优势
Data Movement & Computation
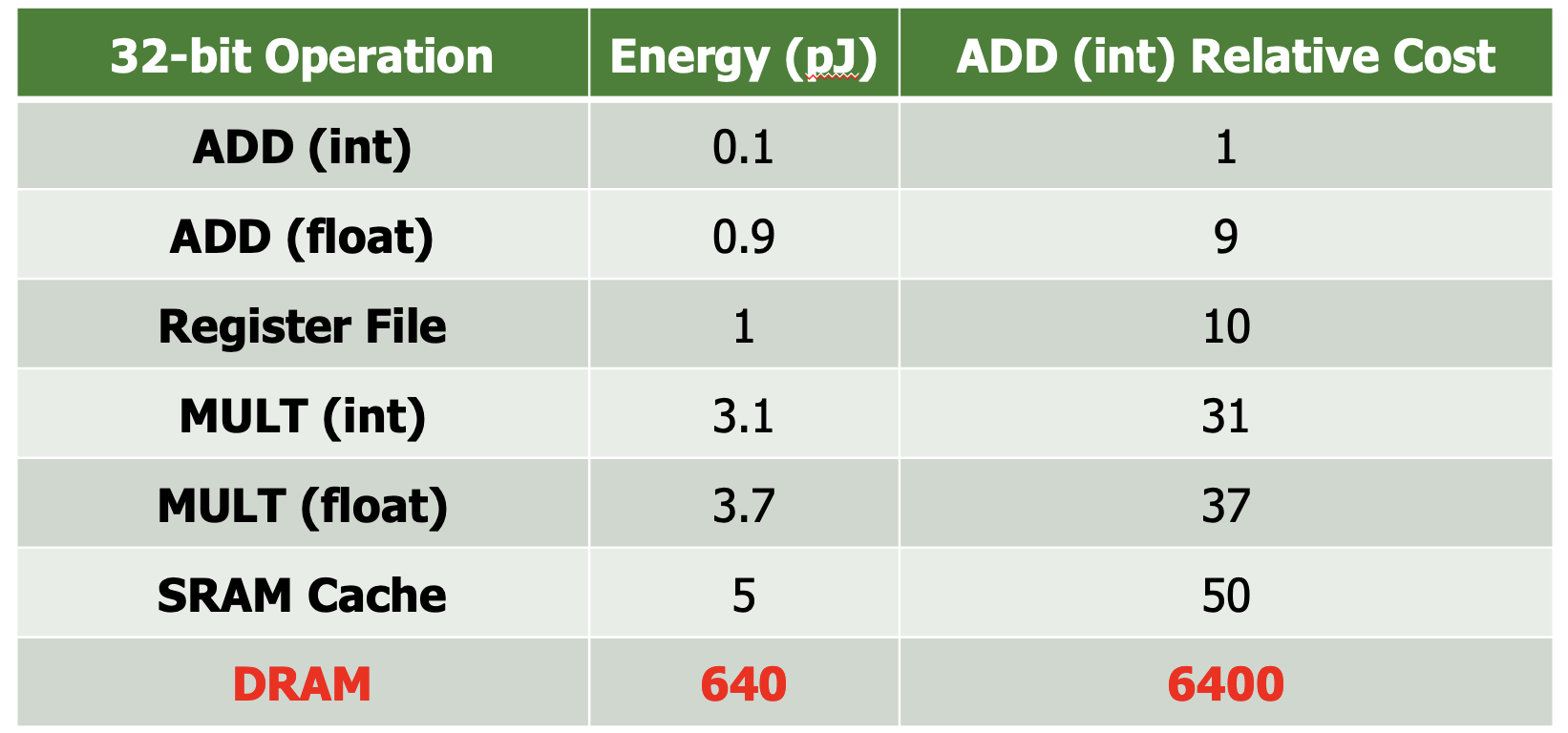
跨芯片访问时间会很多。我们的计算在同一个芯片内会快很多。
DRAM
DRAM内存访问特性:顺序访问很快,因为有row buffer的存在,若row buffer hit,给一个column地址就可以返回。若Row buffer miss,则需要先更新row buffer,再进行column读取。row buffer hit带宽高,miss带宽低。
GPU如何解决延时高的问题?Multithreading、Memory Coalescing、Share Memory
- Multithread:多warp有warp延时时,其他warp也可以跑。增加SM的利用率。
- Memory Coalescing:DRAM对于顺序访问更加友好。因此我们希望Warp中所有的线程访问全局内存是连续的。当warp中的所有线程执行load指令时,硬件会检测它们访问的全局内存位置是否是连续的。如果是的话,硬件会将这些访问合并成一个对连续位置的访问。不用Memory Coalescing,一个warp需要访问#thread次内存,用了之后只需要一个warp一次。Memory Coalescing 合并发生在不同线程的同一周期之间,而不是线程内部的不同迭代之间。
- Share Memory:暂存一些全局数据
Cache是因为DRAM的带宽低,延时高,会漏电,需要refresh
Memory Hierarchy and Caches
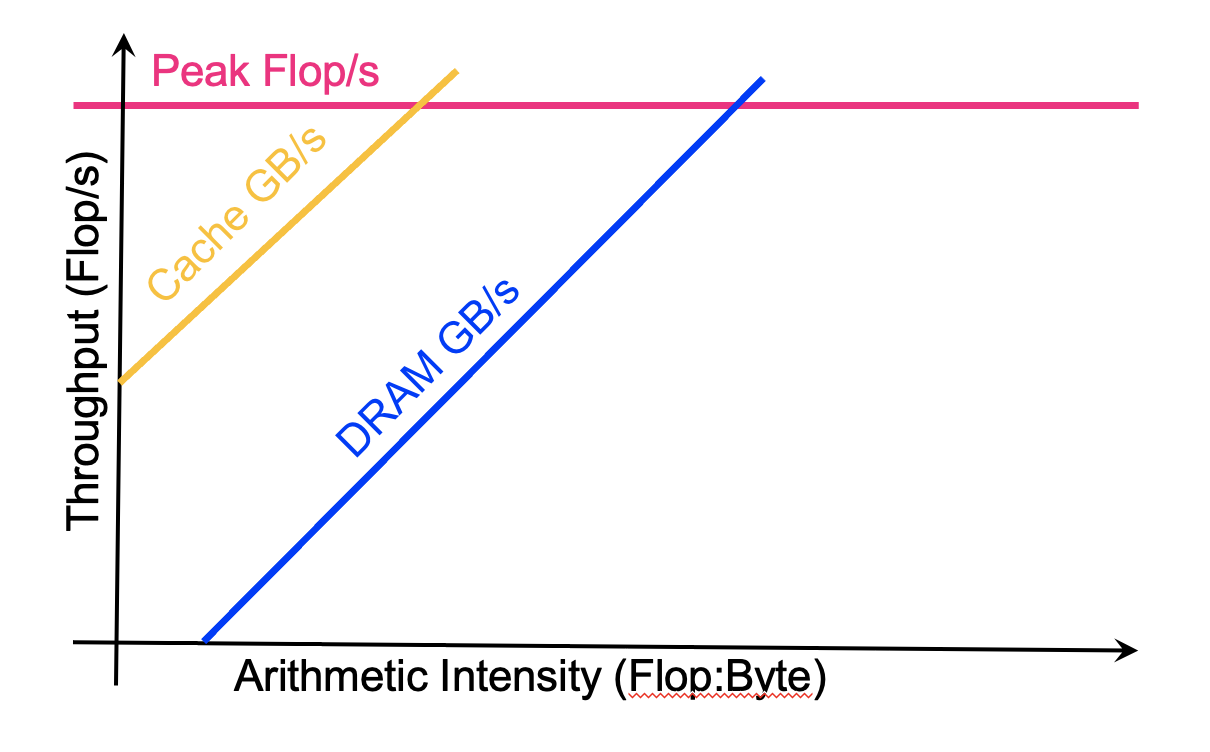
Cache对roofline model的影响,cache的传输速度快,带宽大因此图像如下:
Ideal Memory
- Zero access time
- infinite capacity
- infinite bandwidth
- zero cost
Problem of Ideal Memory
- Ideal memory‘s requirements oppose each other
- bigger is slower
- faster is more expensive
- higher bandwidth is more expensive
Why Cache?
- Challenge:DRAM latency is ~100 ns,slightly decreasing over time
- Our Goal:CPU wants both fast and large memory without modifying
user code
- share memory快而大,但是需要改代码
- cache快而大,且不需要改代码
Memory Hierarchy Example
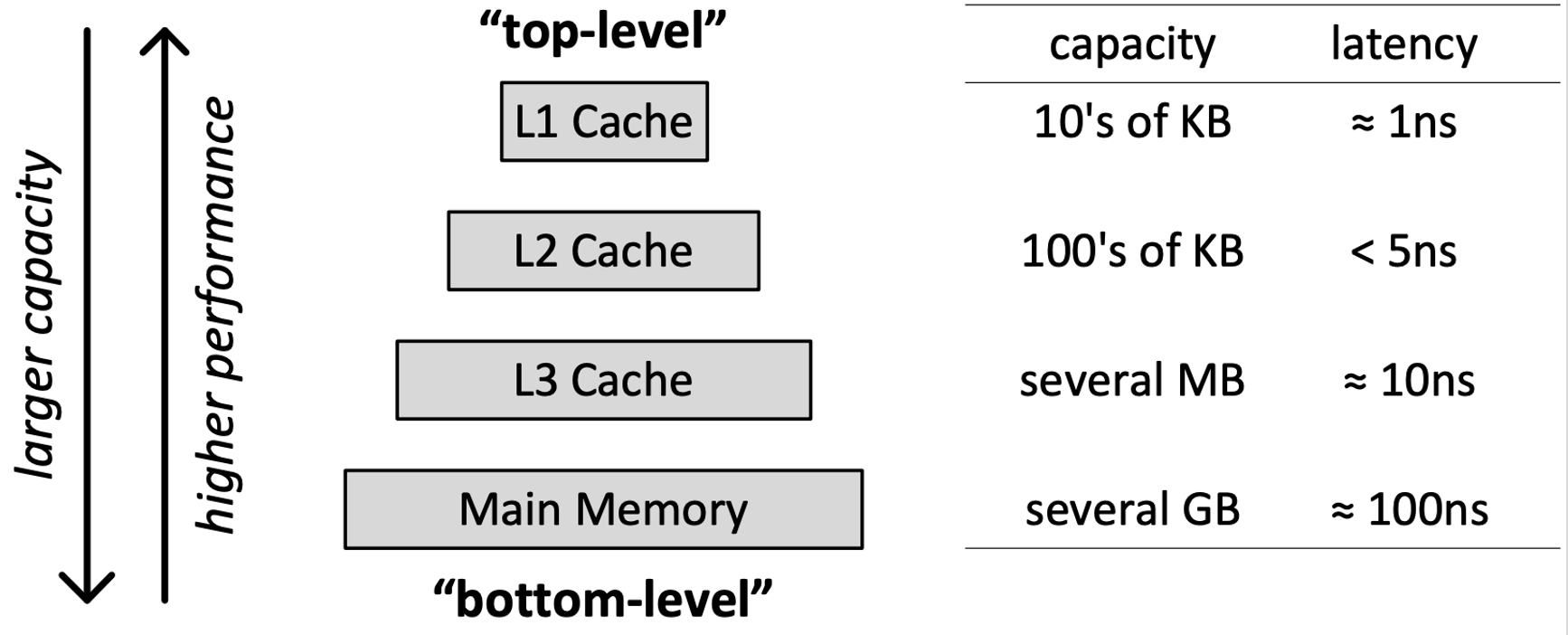
Why Cache Works?
Locality!!!局部性
- 空间局部性
- 如果刚刚做了一些事,那么很有可能你会做与之相关、相似的事情

- 时间局部性
- 如果刚刚做了一些事,那么很有可能你将来马上还会做

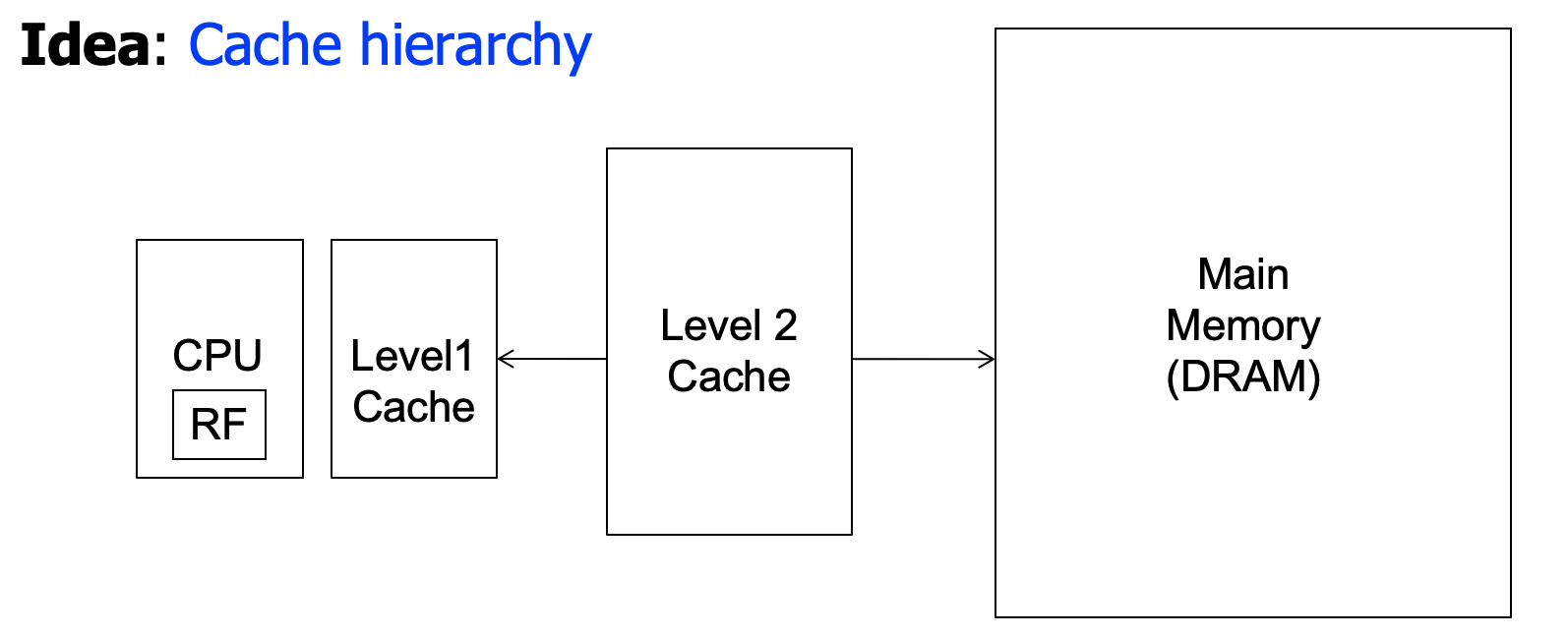
Caching in a pipeline Design
cache needs to be tightly integrated into the pipeline
- ideally,access in 1-cycle so that load-dependence operations do not stall
High frequency pipeline,不能将cache弄的很大
Manual:程序员管理跨关卡的数据移动
- 对于编写大量程序的程序员来说太痛苦了
- “core”和“drum”存储器在20世纪50年代的对比在嵌入式处理器(片上刮擦板SRAM代替缓存)、gpu(称为“共享内存”)、ML加速器……
Automatic:硬件管理跨级别的数据移动,对程序员透明
- c++程序员的生活更轻松一般程序员不需要了解缓存
- 你不需要知道缓存有多大以及它是如何工作的来编写一个“正确”的程序!(如果你想要一个“快速”的项目呢?)
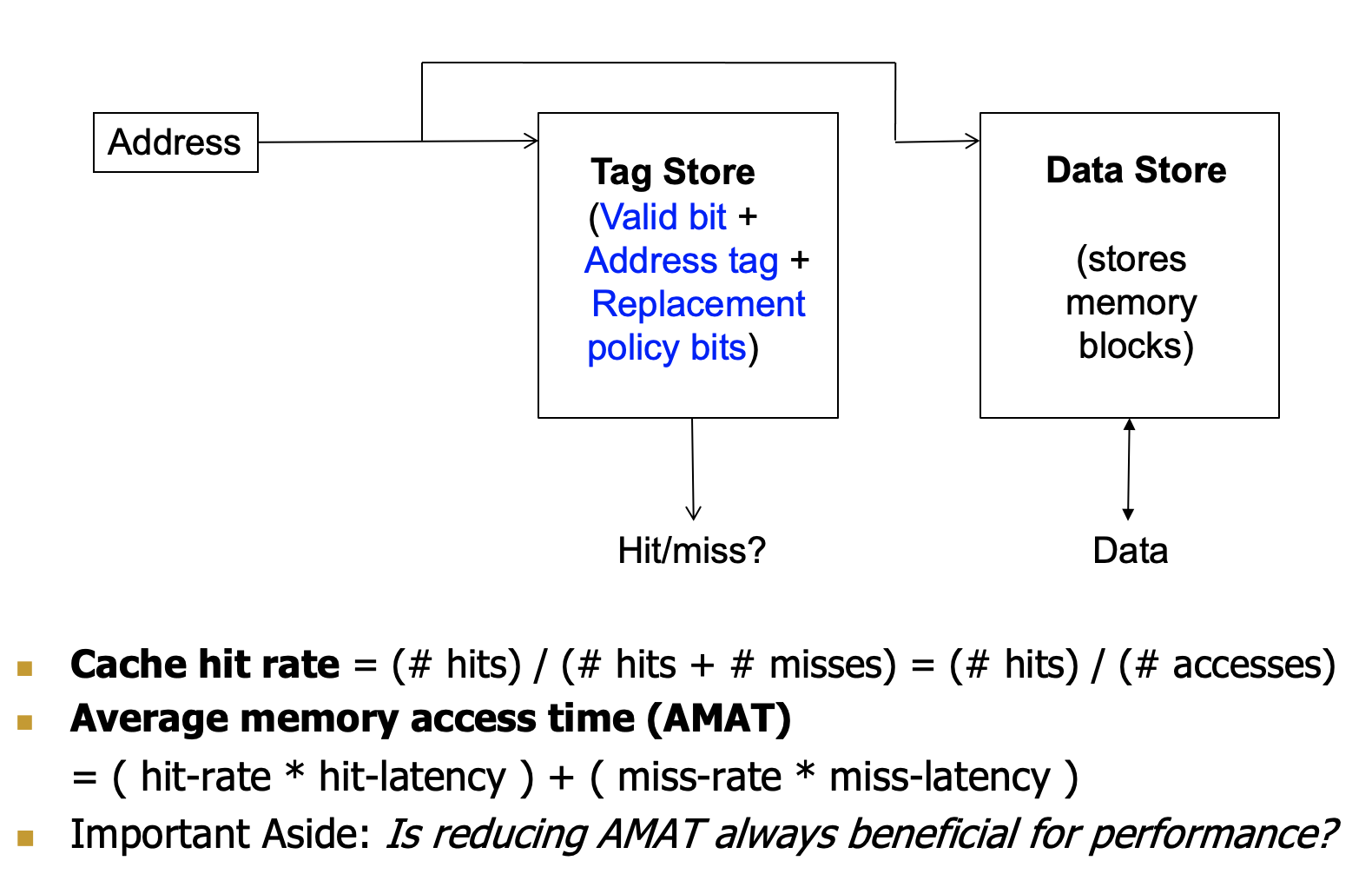
Hierarchy Latency Analysis

我们的访问i级cache的时间为ti,i级的hit rate为hi,miss rate为mi,防问第i级cache成功的时间为Ti
我们的理想是Ti约等于ti,那么我们要求Miss rate小,下一层cache的延迟小,才能保证这个理想。
- 让\(mr_i\)小
- 增加cache的容量会使得\(mr_i\)变小,但是会增大\(t_i\)
- 让\(T_{i+1}\)小
Cache
- 任何“Memory”经常使用的结果/数据的结构
- 避免重复从头开始复制/获取结果/数据所需的长延迟操作
- 就是把经常使用的数据进行暂存
- 在处理器设计上下文中最常见的是
- 一种自动管理的内存结构
- 例如,在快速SRAM中存储最频繁或最近访问的DRAM存储器位置,以避免重复支付DRAM访问延迟
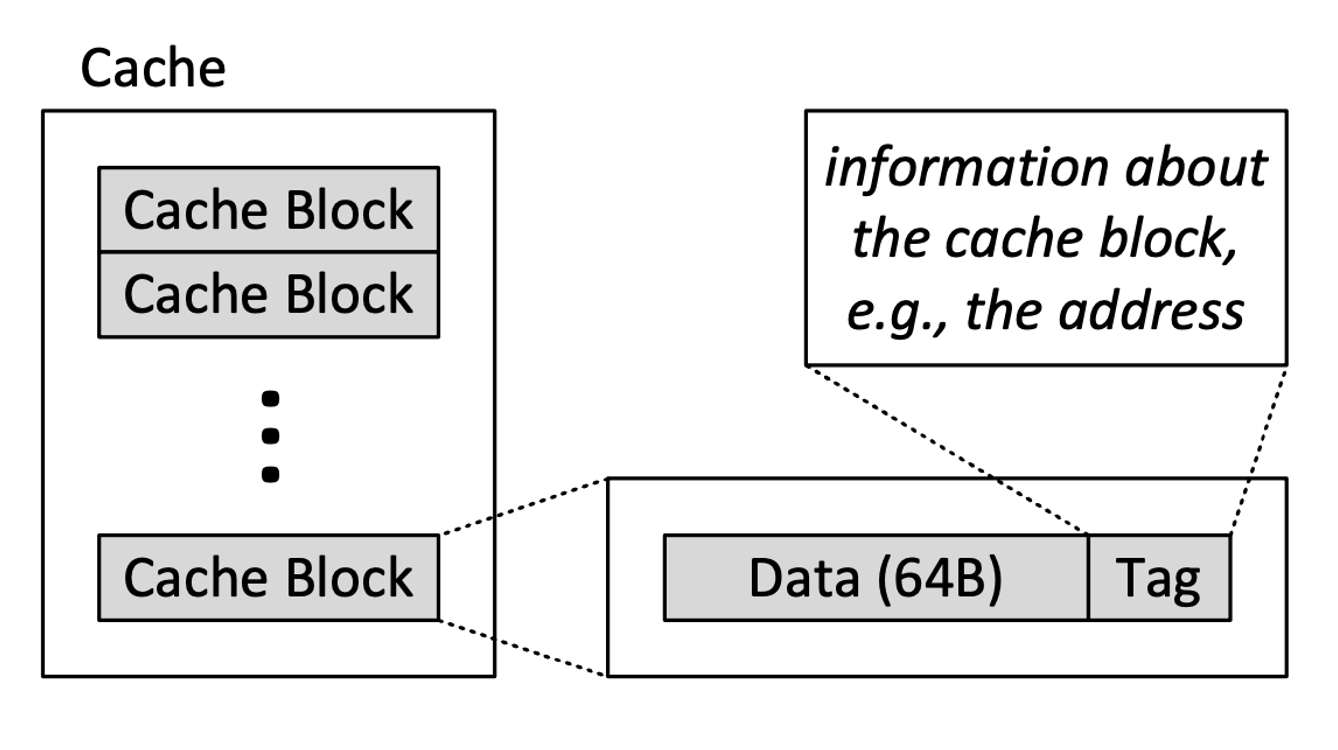
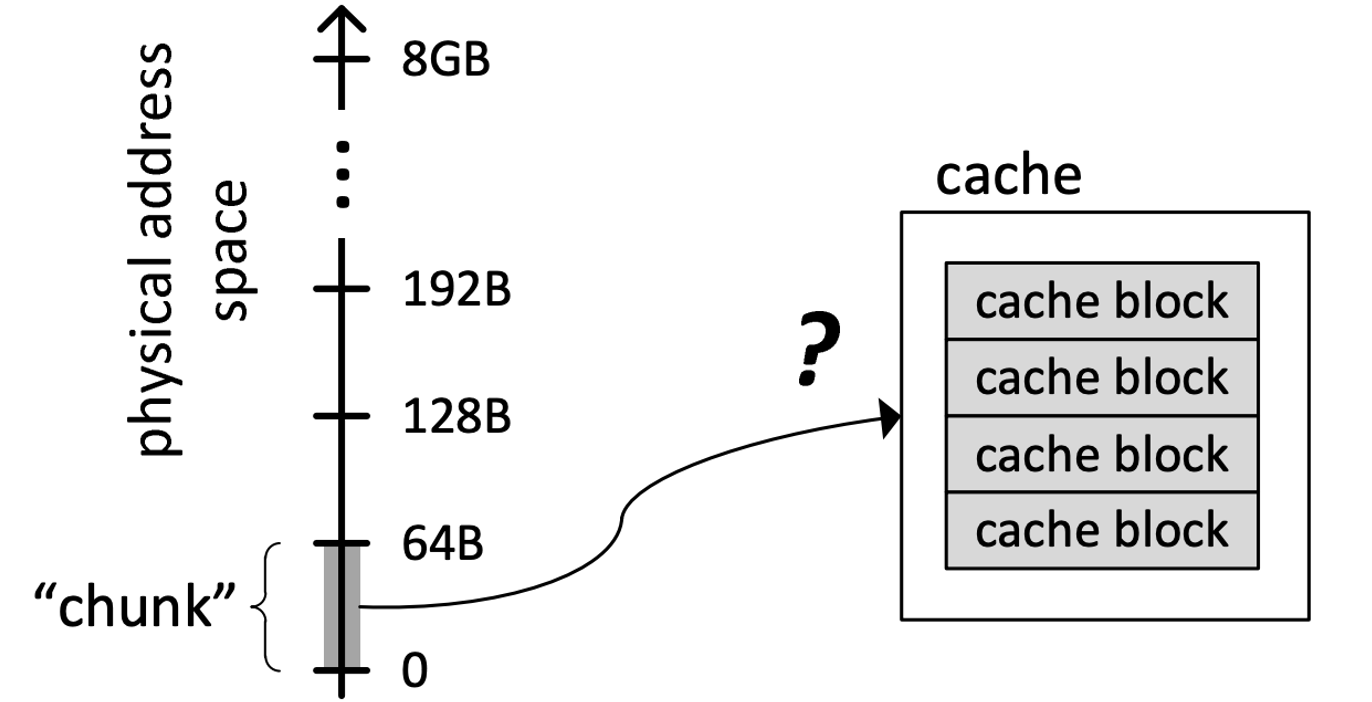
Blocks
main memory逻辑上划分为固定大小的块(block)- 缓存只能容纳有限数量的块,访问都是一个block访问的
- 每个block地址映射到缓存中的一个
potential position,由用于索引标记和数据存储的地址中的索引位确定

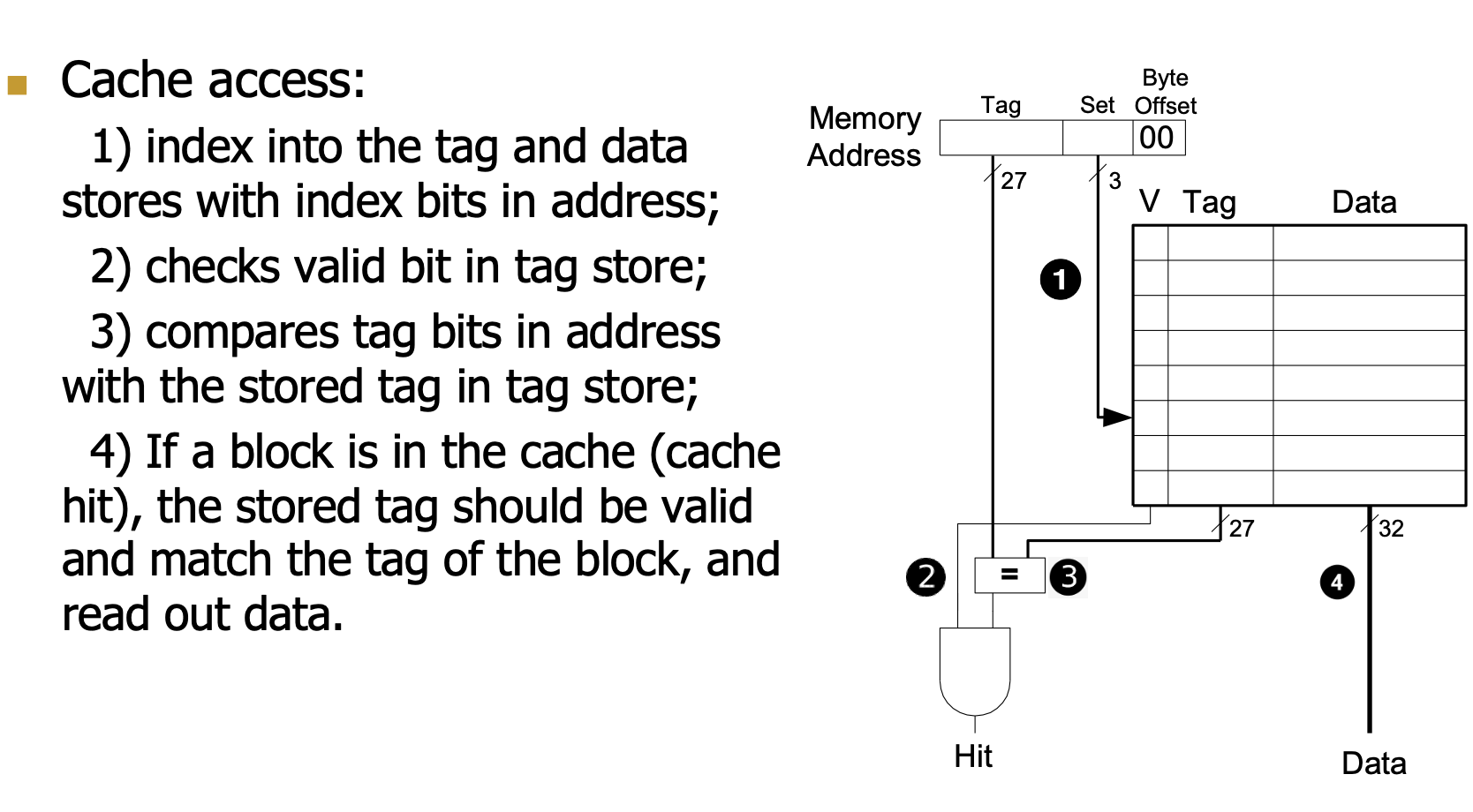
Toy Example
- 256-byte memory(8 bit 地址)
- 64-byte cache,8-byte blocks
- 那么内存有32个block,cache有8个block
Caching Basics
Cache Block(line):Unit of storage in the cache
- 内存在逻辑上被划分为块,这些块映射到缓存中的潜在位置
Hit:if in cache,use cache data instead of accessing memory
Miss:if not in cache,bring block into cache
为了高的hit rate 我们需要设计时考虑:

Placement
如何将内存的地址空间映射到cache?
在缓存的哪个位置可以放置一个给定的“主内存块”
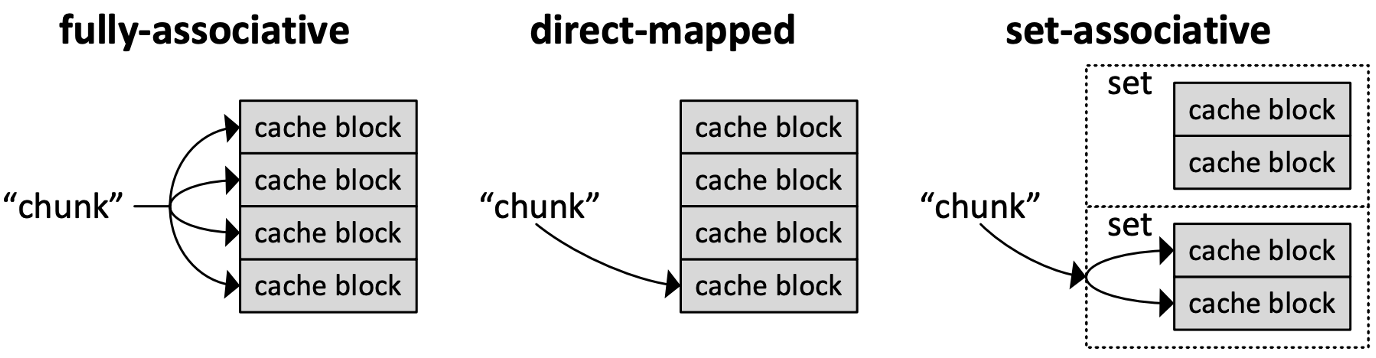
有三种方式:
- Direct-Mapped
一个内存块去一个对应的cache block
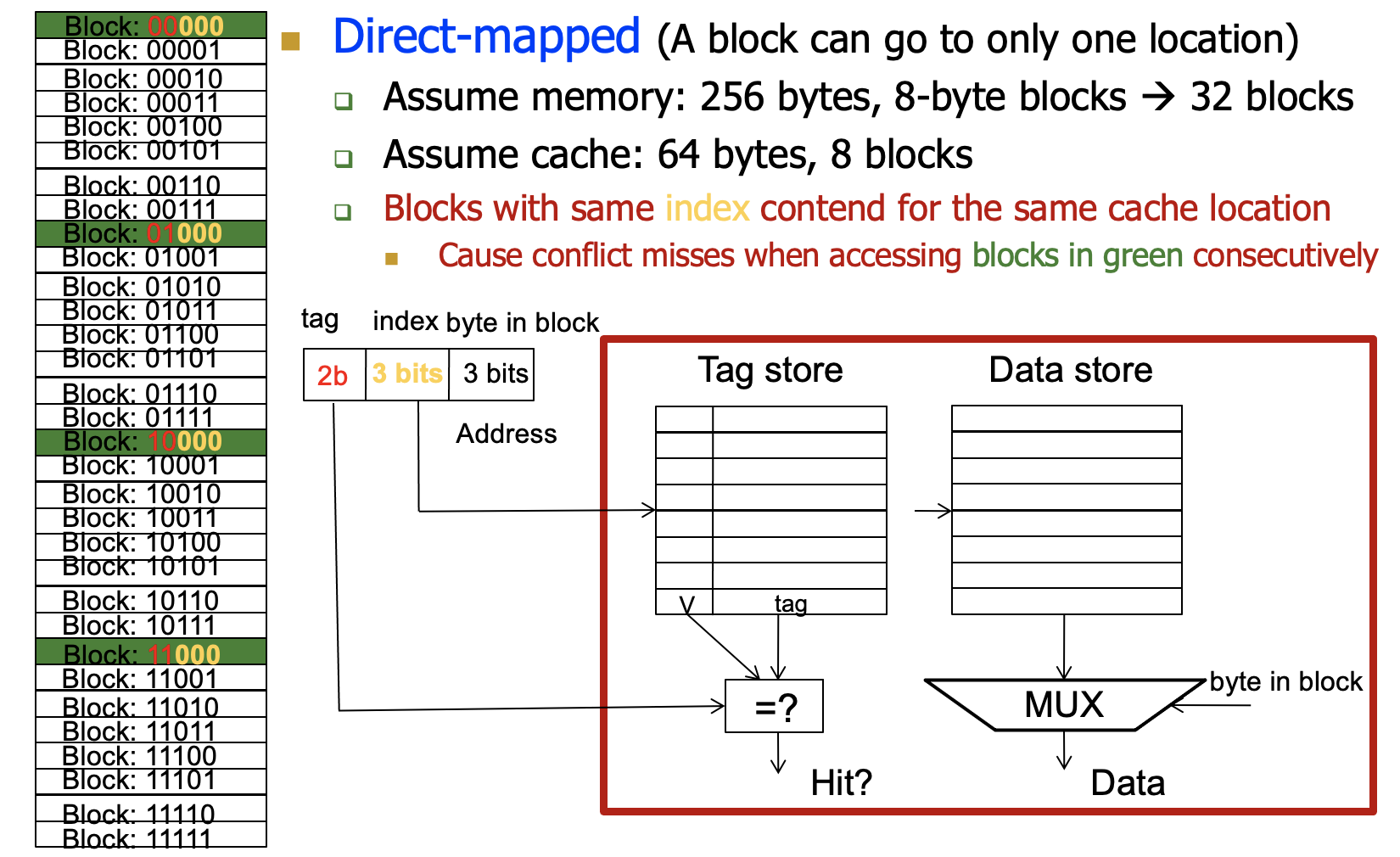
根据index找到对应的cache block,查看tag是否一致确定是否hit
访问方式会导致很多的miss
- Fully-associative
一个内存块可以去任意一个cache block,只要空着就可以进去或者满了替换
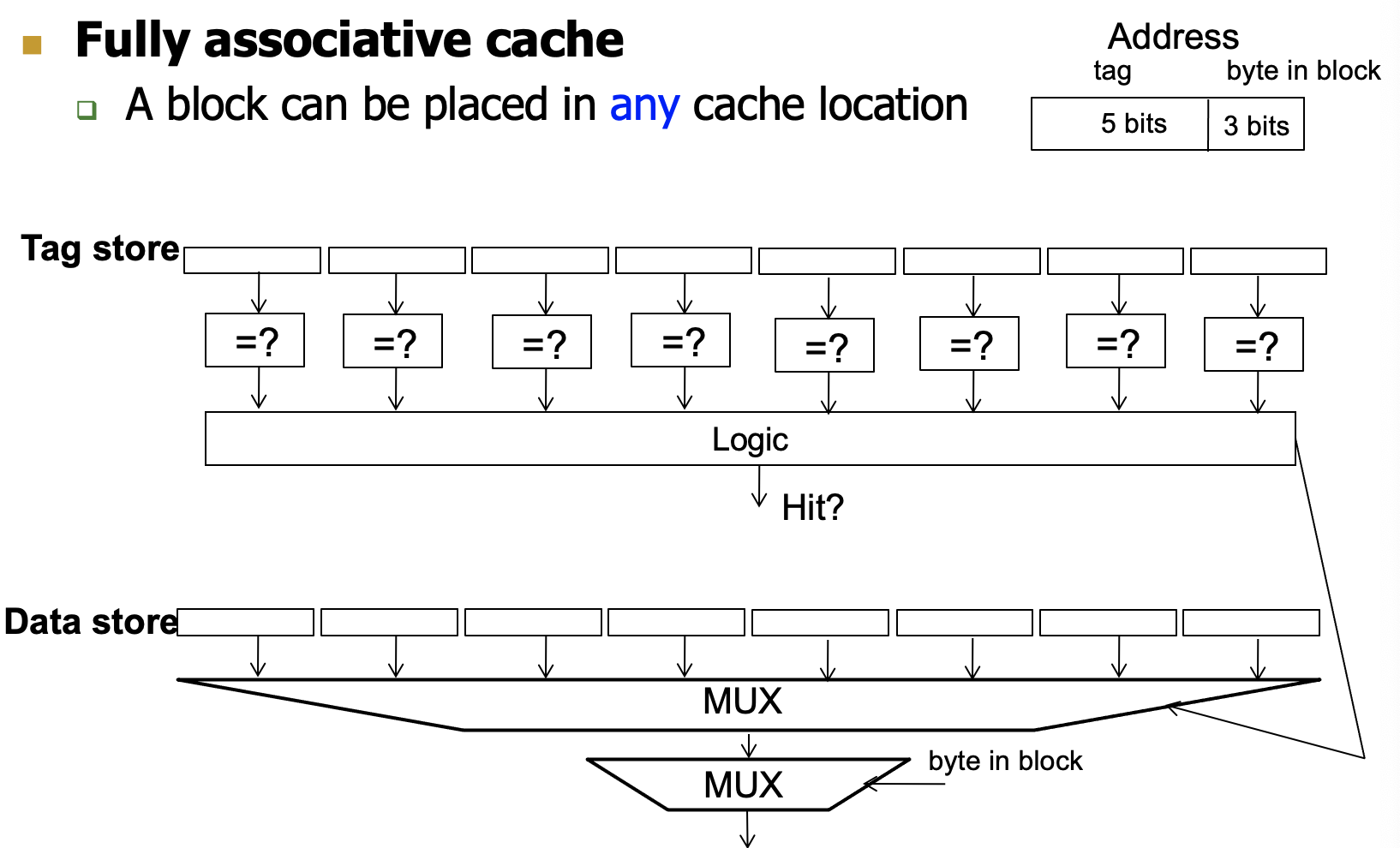
直接对比全部的tag看是否hit,miss的话直接找一个空的cache block或者替换block
复杂度很高
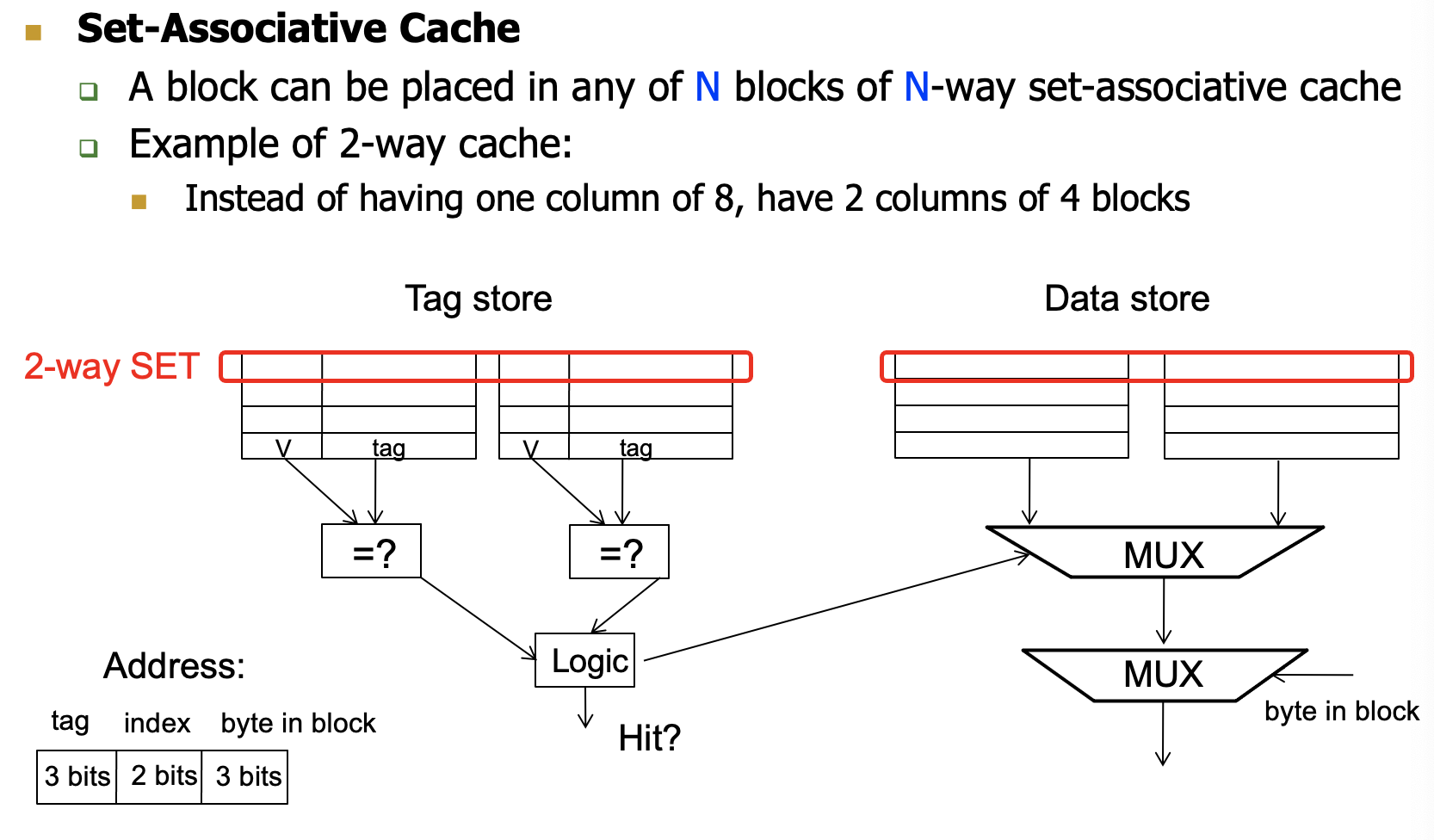
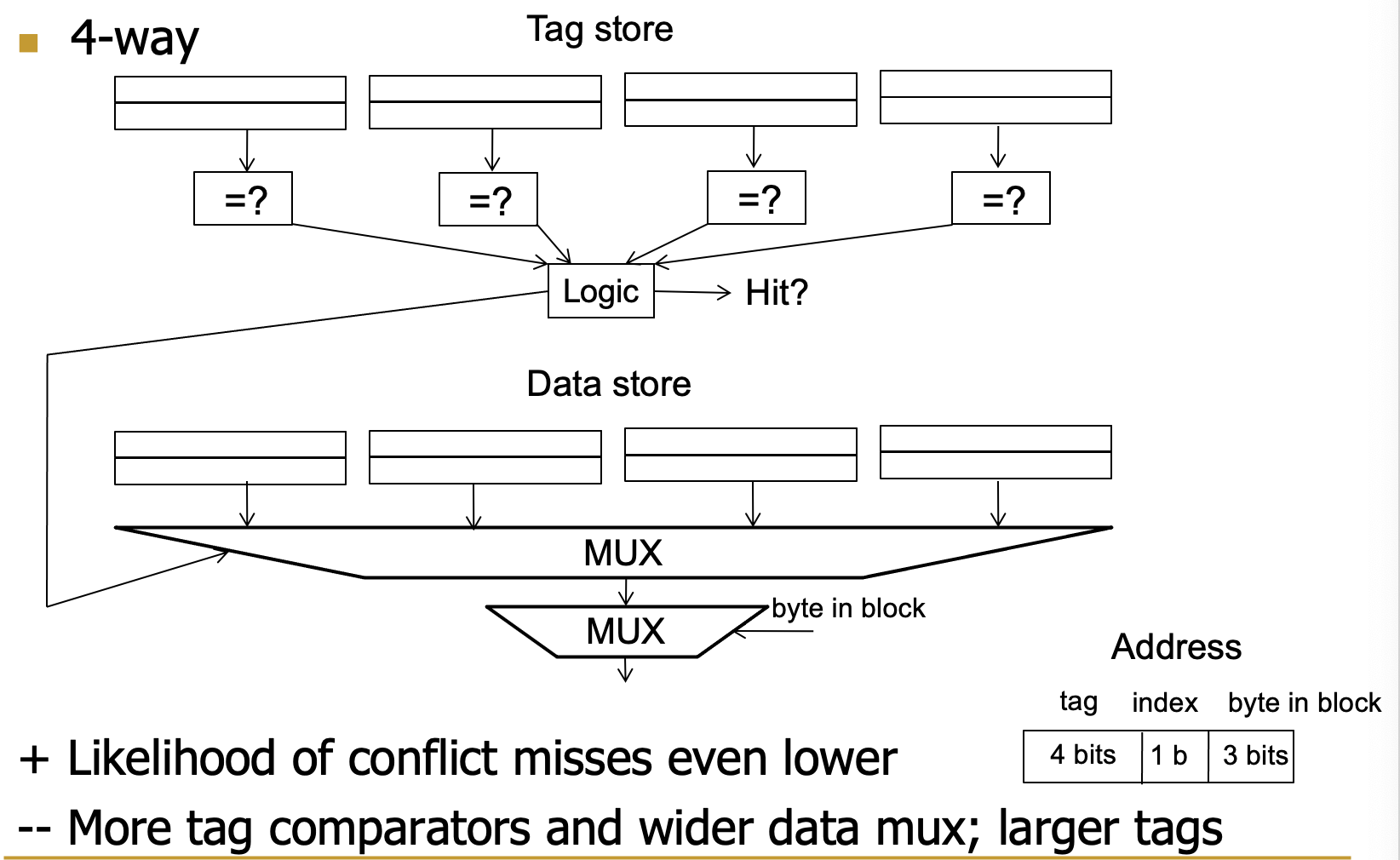
- Set- associative
在N-way组相连中,一个内存块可以去N个cache block中的任意一个
根据index找N个cache block
对比N个里面的tag查看是否hit,miss的话找空位或者可替换位进行替换
Lecture 10 Cache Coherence
Basics
- Cache block:cache中存储的单元,memory是被划分为了很多的block可以映射到cache’中去
- 为了更高的cache hit rate,我们需要考虑
- Placement:在哪一个/如何将memory中的block映射到cache中去
- Replacement:cache满了之后怎么将数据移出
- Granularity of management:block是大是小?
- Write Policy:我们写操作要做什么
- Instructions/Data:我们如何分离处理他们
Cache Block替换策略
- 随机替换
- FIFO
- LRU
- Hybrid replacement policies
- Optimal replacement policy?
LRU
我们需要记录访问N-way中的Block的访问顺序,实时更新
我们其实需要的不是完美的LRU,我们可以允许一些误差。
我们可以使用近似的LRU
N路组相连,我们每一个block需要\(log_2N\)个bit来track,那么一个组就需要\(Nlog_2N\)个bit
PLRU
LRU的近似算法
- Not MRU,最不常用的替换
- Victim-NextVictim Replacement
- PLRU
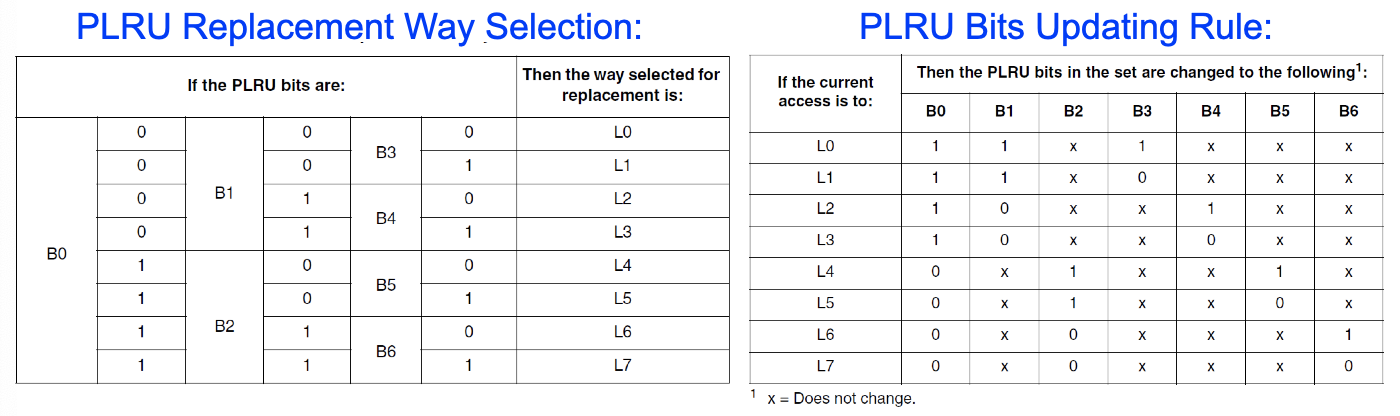
Pseudo LRU for 8-way set- associated cache:
假设我们一个set里面有8个cache block(L0-L7),7个bit给rule(B0-B6)
PLRU根据Rule bit选择一个block
更新规则,只用更新Rule bit
Random
LRU一般来说比Random好,但是也有random更好的情况
比如我们一直访问没有hit的同一个set的cache block,就会一直miss
实际使用的情况中,我们使用混合的方式。主要以LRU为主,附带Random
Optimal Replacement Policy
Belady‘s OPT
- 基于假设:我们已经知道了我们未来要使用的block
- 替换将来最长未使用
Write Policy
Cache Policies:Handling Memory Write
- Where should you write the result of a store?One policy for each
step:
- step1:store instruction - cache,either policy
works
- Write-Allocate Policy(default)
- Allocate the cache line put it in cache
- Issue:Read an entire cache block from memory
- 把memory先写到cache里面
- Write-No-Allocate Policy(PCIe/IO)
- Write it directly to memory without allocation in cache
- 没有cache的分配
- Write-Allocate Policy(default)
- step2:cache- memory
- Write-Back
- 不写回memory,直到cache block要被替换出去
- 好处:我们的cache可以预先处理多次修改,再只用一次访问memory写回
- 缺点:需要额外的dirty bit来检查是否memory和cache一致
- Write-Through
- 更新cache的同时,将memory同步更新
- 好处:简单,不会出错,Cache数据都是最新的
- 缺点:需要大量访问内存
- Write-Back
- step1:store instruction - cache,either policy
works
Instructions vs Data Caches
- Core question:Separate or Unified
- 统一的利弊:
- +缓存空间的动态共享,不会出现静态分区(即单独的I和D缓存)可能出现的过度配置
- -指令和数据可以相互碰撞(也就是说,两者都没有保证空间)
- -I和D在管道中的不同位置被访问。为了快速访问,我们应该把统一缓存放在哪里?
- 现代CPU
- 一级cache往往是split的
- 高级的cache是unified的
Cache Performance
Cache Size:
- 我们希望是越大越好,因为有更好的时间局部性,但是越大不是完全越好的。
- too large:局部性强,影响了hit和miss rate
- 访问更慢
- too small:
- 局部性不强
Block Size:
- too small:
- 空间局部性不够,有很大的一部分被tag使用
- too large:
- block的数量少了
- cache的利用率低
- 太小不好,太大不好,在中间最好
Associativity
- Large Associativity
- Small Associativity
Cache Miss
Compulsory miss
第一次访问就会miss,我们的解决方法是:预取
- caching cannot help
- 我们将可能需要的数据提前放入cache中
Conflict miss
多个memory内存去了同一个的block,那么我们就尽量增加associativity
- More associativity
- Victim cache
Capacity miss
Utilize cache space better:keep blocks that will be referenced
Cache in Multi-core CPU
Recall:Multi-Core over Large Superscalar
- Technology push
- 指令发布队列的大小限制了超标量的循环时间,OoO处理器→降低了性能
- 复杂度随问题宽度的二次增长
- 支持大指令窗口和问题宽度的大型多端口寄存器文件→更多的资源,降低频率或更长时间的RF访问,降低性能
- Application push
- 很多app需要在你的cpu上跑
Challenge from Multi-core CPU:
- 需要缓存来缓解长内存延迟的负面影响
- 多核CPU也要通过cache改进内存访问延时长的问题
- 如何设计一个cache给多核用?核心需要一个一致的内存视图。A consistent view of memory
Caches in Multi-Core CPU
Cache的效率在Multi-Core/Multi-Thread系统中十分重要
- 内存带宽非常宝贵,读取的数据一定要物尽其用
- 缓存空间是跨内核/线程的有限资源
多个决定:
- Shared vs private Cache
- How to preserve coherence and consistence
Private & Shared Caches
Private Cache
- 这个私有的cache属于一个core
Shared Cache
- 共享的cache是被多个core共享的
资源共享的好处
通信延时降低
资源利用率效率提升
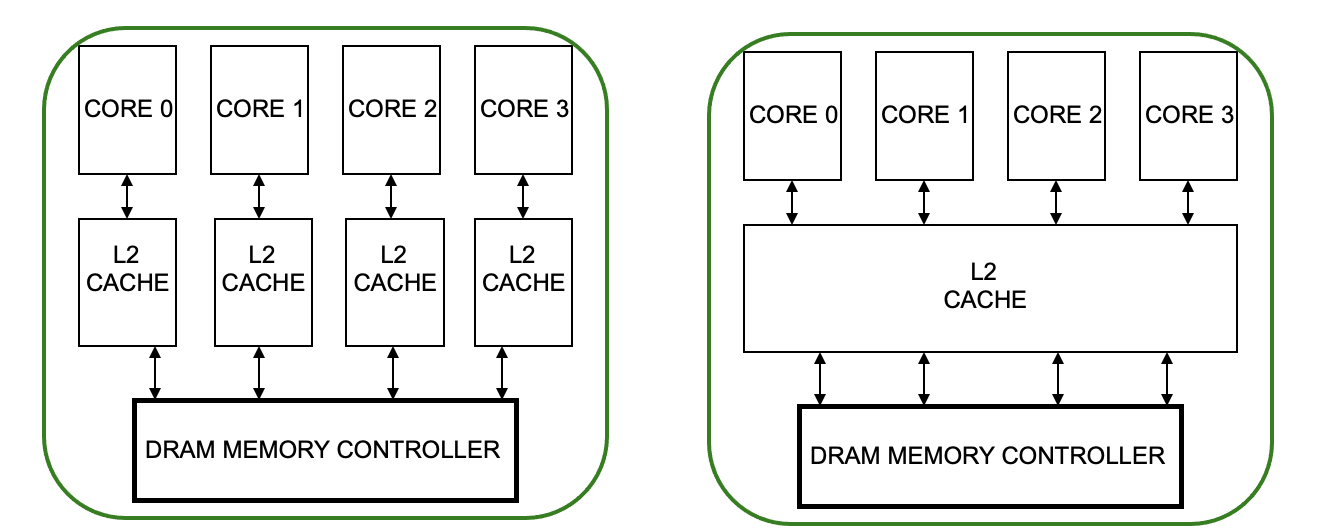
Resource Sharing Concept and Advantages
- Idea:与其将一个硬件资源专用于一个硬件上下文,不如允许多个上下文使用它
- 比如:functional units、pipeline、caches、buses
- Advantages
- 资源共享提高了利用率/效率,增加了throughput
- 当资源被一个线程闲置时,另一个线程可以使用它;无需复制共享数据
- 减少了通信延迟
- 例如,多个线程之间共享的数据可以保存在多线程处理器的同一缓存中
- 兼容共享内存编程模型
- 资源共享提高了利用率/效率,增加了throughput
- Disadvantages
- 共享资源会导致资源争夺
- 当资源不是空闲时,其他线程不能使用它。
- 如果空间被一个线程占用,则需要另一个线程重新占用它
- 有时候会降低某些线程的表现
- 线程的performance会比单独跑要低
- 消除了性能的隔离性,运行时性能不一致
- Uncontrolled(free-for-all)sharing degrades OoS
- 共享资源会导致资源争夺
那么说回多核之间的共享Caches的优缺点
Advantage

Disadvantage

Cache Coherence & Memory Consistency
- 都是一致性,一个是不同处理器对于cache的block的访问的排序,一个不同处理器是对内存操作的排序
- Coherence:Coherence是关于从不同处理器到相同内存位置的操作的排序
- 对每个缓存块的访问进行本地排序
- Consistency:Consistency是指对来自不同处理器(对不同内存位置)的所有内存操作进行排序
- 对所有内存位置的访问进行全局排序
Cache Coherence
什么是缓存一致性?【https://zhuanlan.zhihu.com/p/417487200】
当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU高速缓存中,那么CPU进行计算时就可以从它的高速缓存读取数据和向其中写入数据,当运算结束后,再将高速缓存中的数据刷新到主存当中。
当线程执行这个语句时,会先从主存当中读取i的值,然后复制一份到高速缓存当中,然后CPU执行指令对i指令进行加1操作,然后将数据写入高速缓存,最后将高速缓存中i最新的值刷新到主存当中。
这个代码在单线程中运行时没有任何问题的,但是在多线程中运行就会有问题了。在多核CPU中,每条线程可能运行于不同的CPU中,因此每个线程运行时有自己的高速缓存(对单核CPU来说,其实也会出现这种问题,只不过是以线程调度的形式来分别执行的)。我们以多核CPU为例。
比如同时有两个线程执行这段代码,假如初始时i的值为0,那么我们希望两个线程执行完之后i的值变为2。但事实会是这样吗?
可能存在下面一种情况:初始时,两个线程分别读取i的值存入各自所在的CPU的高速缓存当中,然后线程1进行加1操作,然后把i的最新值1写入到内存。此时线程2的高速缓存当中i的值还是0,进行加1操作后,i的值为1,然后线程2把i的值写入内存。
最终结果i的值是1,而不是2。这就是著名的缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。
也就是说,如果一个变量在多个CPU中都存在缓存(一般在多线程编程时才会出现),那么就可能存在缓存不一致的问题。
现代处理器的并行代码或线程共享内存,需要保证数据一致性。从软件、硬件两个角度考虑解决cache一致性。现代处理器cache一般对程序员透明,ISA一般只提供cache flush命令。如果靠软件解决,对程序员负担太大。
缓存一致性:多核具有从任何核到内存地址的最后写入值的一致状态
- Program order preservation:程序的基本的顺序需要保持,处理器P写入地址,然后从同一地址读取,P得到写入的值。
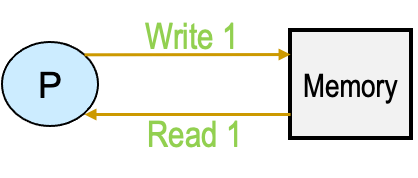
- Coherent memory
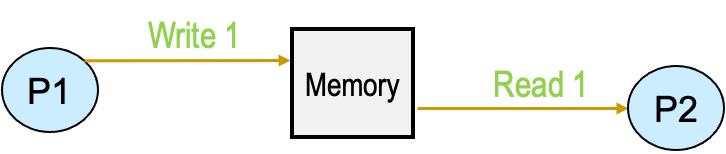
view:连贯的内存视图,当P1进行了操作
mem[X]=1在一段时间后,P2将可以mem[X]中读取出1
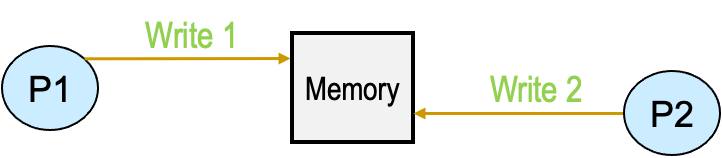
- Write serialization:写序列化,不同处理器对同一地址的写操作在所有处理器中都以相同的顺序显示。所有的处理器看到的顺序必须是一样的。
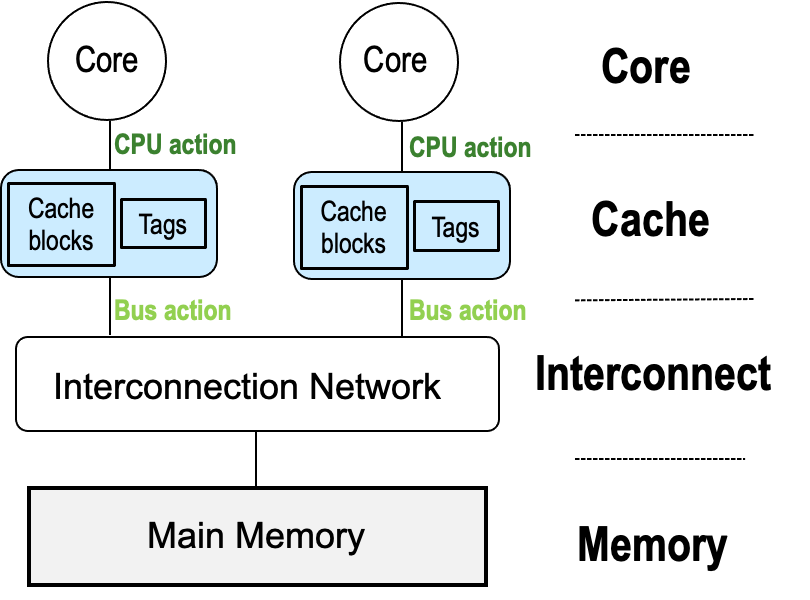
Hardware Architecture for Cache Coherence
从cores的角度,Cores、caches、interconnect、memory work一起实现cache coherence
- Interconnect:Snoop/Directory
- Cache updating:invl./update
- Cache Tags:MESI

Cache Coherence Protocols
- Snoop:
- 基于总线,每个总线动作在总线上广播,一次一个动作。
- Cache需要对共享总线进行侦测,如果侦测到总线上的操作与自己cache中的某个cache block相符合(tag一致),则采取某种动作(具体动作由cache一致性协议定义,比如MSI),这种系统需要支持广播功能的总线,此外这种方案比较适用于小规模的系统
- 所有的Memory Request都要单点序列化
- Directory
Updating Policy
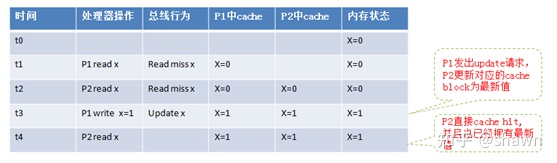
- Update Protocol
更新协议,只要有一个核中写了cache line,别的核对应一样tag的cache line也要更新,但是这样子开销大,比如别的核不读这个cache line只写,那么就会很浪费。
Write-update(或者叫write broadcast): 当一个处理器更新某个数据时,其不往总线上发送invalidate消息,而是往总线上发送一条update A消息,直接告知该变量的最新值,其它处理器上的cache侦听到这个操作后更新本地的变量为这个广播的最新值。其它处理器在下一次使用该变量时,直接cache 命中,可以直接使用最新数据,而不产生read miss操作。
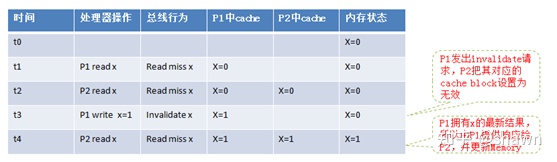
- Invalidate Protocol
无效协议,写的时候,我们把别的核的cache无效掉,别的核要写要读需要重新发起请求。
Write-invalidate: 一个处理器需要更新某个数据时,其先往总线上发送一条Invalidate请求,系统中其它处理器上的cache控制器监控到这条消息,把自己的状态设置为invalid。如果这些invalidated cache block在下一次需要访问该数据时,则会重新进行一个总线的read miss操作。
MSI协议【https://zhuanlan.zhihu.com/p/417949142】
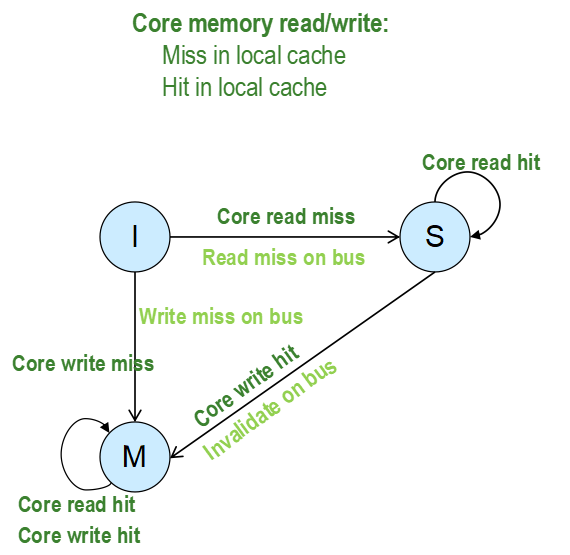
实现内存一致性的协议可以细分为很多种,但最基本的还是MSI协议,MSI代表了 cache block的三种不同状态 I,S,M,分别是invalid, Shared和Modified。任何时刻Cache block必处于这三种状态之中的一种状态。
- I(Invalid)状态:该cache block在当前cache中不存在或者被总线上的invalidate操作设置为无效,处于该状态的cache block需要从Memory或者其它cache中获取,在访问该cache block时,cache控制器需要往总线上产生一个read miss或者write miss操作。
- S(Shared)状态:该Cache Block的内容没有被修改并且处于只读状态,cache block存在于至少一处cache中和memory中,该状态下CPU能够直接读取该cache block数据而无需与其它cache进行通信,总线上没有操作。
- M(Modify)状态:该状态的Cache Block只能存在一处cache中,该状态下cache block,CPU能够直接读写而不需要知会其它CPU上的Cache。该状态的cache block负责为其它cache节点提供最新的数据,同时也负责把最新数据写回到memory中。
【从CPU的角度来看MSI协议】本CPU的命令
- I状态:CPU中cache
block的状态总是从I状态开始的,因为一开始的时候cache中并没有缓存某个内存地址的数据。
- 当CPU需要读取某个内存数据时,此时发生cache miss,于是cache控制器对总线发送一个read miss操作。Memory或者其它远端cache控制器(处于M状态)对该请求进行响应,本地cache拿到数据,进入shared状态
- 当CPU发起一个写操作时,Cache控制器往总线上发送一条write miss命令,然后进入Modified状态。(问题:CPU为什么可以对处于I状态的cache block 发起写操作?)
- S状态:
- CPU发起Read,由于Shared态可读,那么直接hit,仍为S态
- CPU发起Write,则cache控制器往共享总线上放置一个invalidate命令,该cache block切换到Modified状态
- M状态:
- 无论CPU发起读还是写操作,由于直接cache命中,状态都不发生改变;
【从总线的角度来看MSI协议】来自其他CPU的命令
- I状态:
- 表明本CPU对于该cache block数据不关心,所以也就不关心总线上的任何消息,也不会对总线上的任何消息产生动作。
- S状态:
- 如果侦测到总线上发生了invalidate命令或者write miss命令,则表明其它CPU需要对该cache block进行修改,所以把本地cache block设置为无效,进入I状态
- 如果侦测到总线上发生了read miss操作,表明其他CPU要读数据,则memory会提供有效响应,而本cache block由于不是写的,仅仅是可读,不是数据来源,不做动作,维持在S状态
- M状态:
- 如果侦测到总线上发生read miss操作,则本cache需要为请求方提供该cache block,同时会利用这个机会更新memory。此时该cache block进入共享状态S。
- 如果侦测到总线上发生write miss操作,则本cache需要先更新自己的最新数据给请求方提方,同时会利用这个机会更新memory。但此时该cache block进入无效状态I。
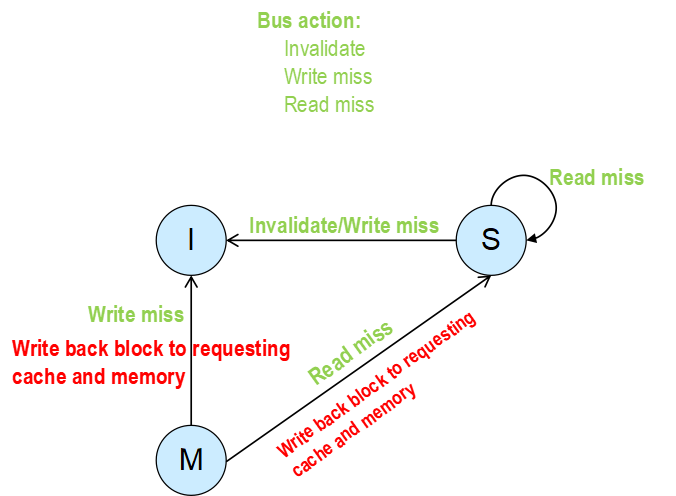
MESI协议
查看这个例子,这两里的A和B只有一份内存的拷贝,即只在一个Cache 中,这里的两次的Invalidate真的有必要吗?没有必要,因此我们增强了MSI协议
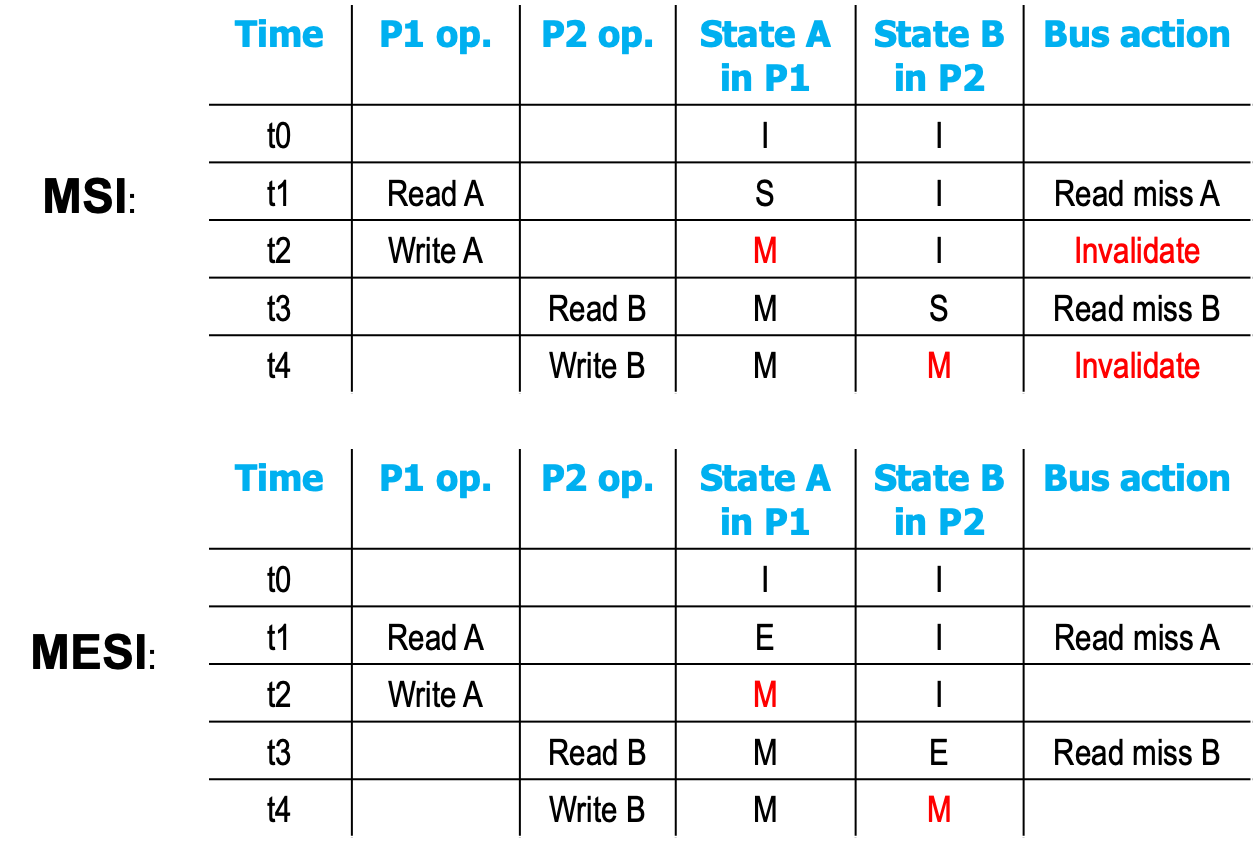

引入新状态E(Exclusive):处于独占状态(E)的cache block只出现在一个处理器节点上,并且是干净的(表示cache中的数据与memory的数据一致)。处于E状态的cache block, 修改时候不需要进行总线上的invalidate操作。
- Key Differences
- Local Core reads block in state E,state hold。读E状态的Cache block,状态不变
- Local Core writes block in state E,state M,without bus action
- 当总线上有Read Miss的指令,说明别的CPU有读这个Cache Block了,E状态要改成S状态
- 当总线上有Write Miss的指令,说明别的CPU有写这个Cache Block了,E状态要改成I状态
Cache Consistency
Ordering of Operations
如果说有ABCD四个操作,硬件执行的顺序是怎么样的?
Consistency:一个编程者和微架构之间的协议
- 保持“预期的”(更准确地说,“商定的”)顺序简化了程序员的工作易于调试
- 保持“预期”的顺序通常会使硬件设计师的生活变得困难
Single Processor的Memory Ordering
被冯诺依曼模型确定了,顺序的执行程序。
OoO执行不会改变语义,即OoO执行时指令 retire顺序是程序的顺序。
优点
- 架构状态在执行中是精确的
- 架构状态在程序的不同运行中是一致的→更容易调试程序
缺点
- 保持顺序会增加开销,降低性能,增加复杂性,降低可伸缩性
MIMD Processor的Memory Ordering
每个处理器的内存操作都是按照该处理器上运行的“线程”的顺序进行的(假设每个处理器都遵循冯·诺伊曼模型)。
- 多个处理器并发地执行内存操作内存
如何看到来自所有处理器的操作顺序?换句话说,不同处理器之间的操作顺序是什么?
Challenge
两个Processor不能看到相同的内存操作顺序。
多个内存更新之间的“发生在之前”关系在两个处理器的观点中是不一致的
4 Types of Memory Barrier
- Load-Load:Effectively prevents ordering of loads performed before the barrier with loads performed after the barrier
- Load-Store:Effectively prevents ordering of loads performed before the barrier with writes performed after the barrier
- Store-Store:Effectively prevents ordering of stores performed before the barrier with stores performed after the barrier
- Store-Load:Effectively prevents ordering of stores performed before the barrier with loads performed after the barrier
多处理器系统中的顺序一致性,如果
- 在单处理机中:每个单独处理机的操作按其程序指定的顺序出现在这个序列中和
- 在多处理器中:任何执行的结果都是相同的,就好像所有处理器的操作都按照某种顺序执行,就好像它们在操作单个共享内存一样
Sequential Consistency
顺序一致性:内存是一个开关,每次服务于来自任何处理器的一个加载或存储
- 所有处理器同时看到当前服务的load或store
- 每个处理器的操作都按程序顺序进行
问题是性能极低,都是顺序执行的
Total Store Order
Total Store Order == SC + Store Buffer
- 提交存储指令意味着数据存储在存储缓冲区中,而不是缓存层次结构中。
- 存储指令写入本地存储缓冲区,然后立即执行下一条指令(例如,加载)。
- 当准备好时,缓存将从存储缓冲区中取出写操作。
- 不保留存储加载顺序。
存储缓冲的思想:将内存访问与其他访问和计算重叠。隐藏内核中较长的写延迟,重新排序先读后存储。
Lecture 11 深度学习处理器
为什么需要AI加速器
深度学习应用广泛,市场大
- AI for X:图像识别、语音处理、自然语言处理
- 平台:渗透到了云服务器和智能手机
通用CPU/GPU处理人工神经网络效率低下(费电)
处理器&性能指标
- CPU:Central Processing Unit(一个大学生)
- GPU:Graphics Processing Unit(100个小学生)
- DL Accelerator:Deep Learning Accelerator(偏科生)
指标
- 延时:输入数据到输出的时间
- 通用性:适合运行的应用程序范围
- 能效:单位计算量所消耗的能量
- 可迭代性:AI模型变化时的硬件适应能力
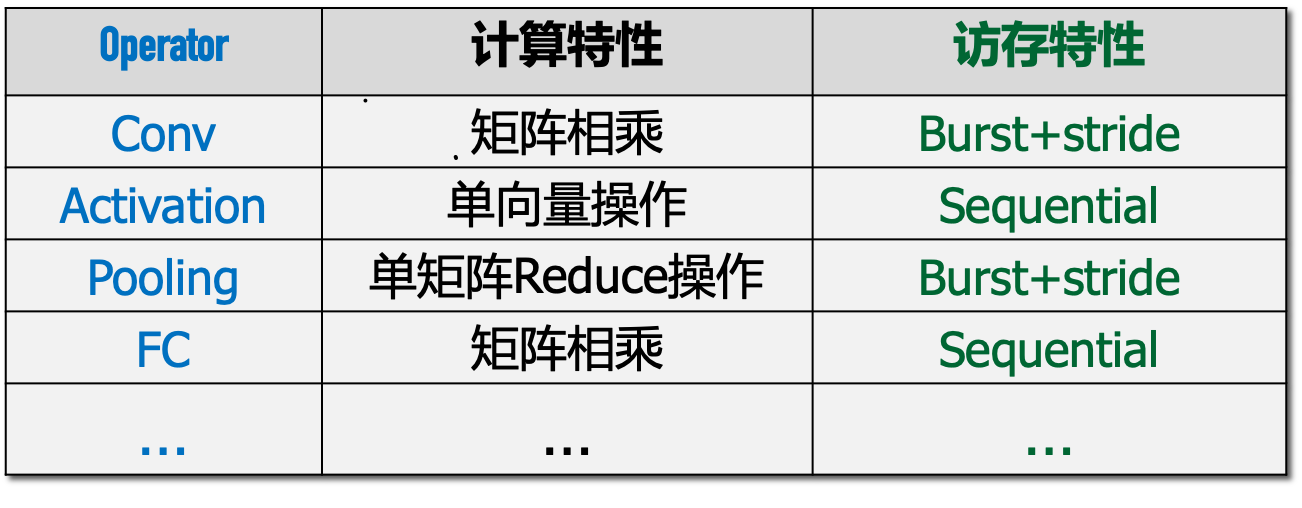
卷积层计算和访存特性
计算他性:矩阵乘向量
计算特性:矩阵乘矩阵
访存特性:时空局部性、一维局部性
激活函数计算和访存特性
计算特性:向量运算
访存特性:向量顺序访问
全连接层计算和访存特性
计算特性:矩阵相乘
访存特性:顺序访问
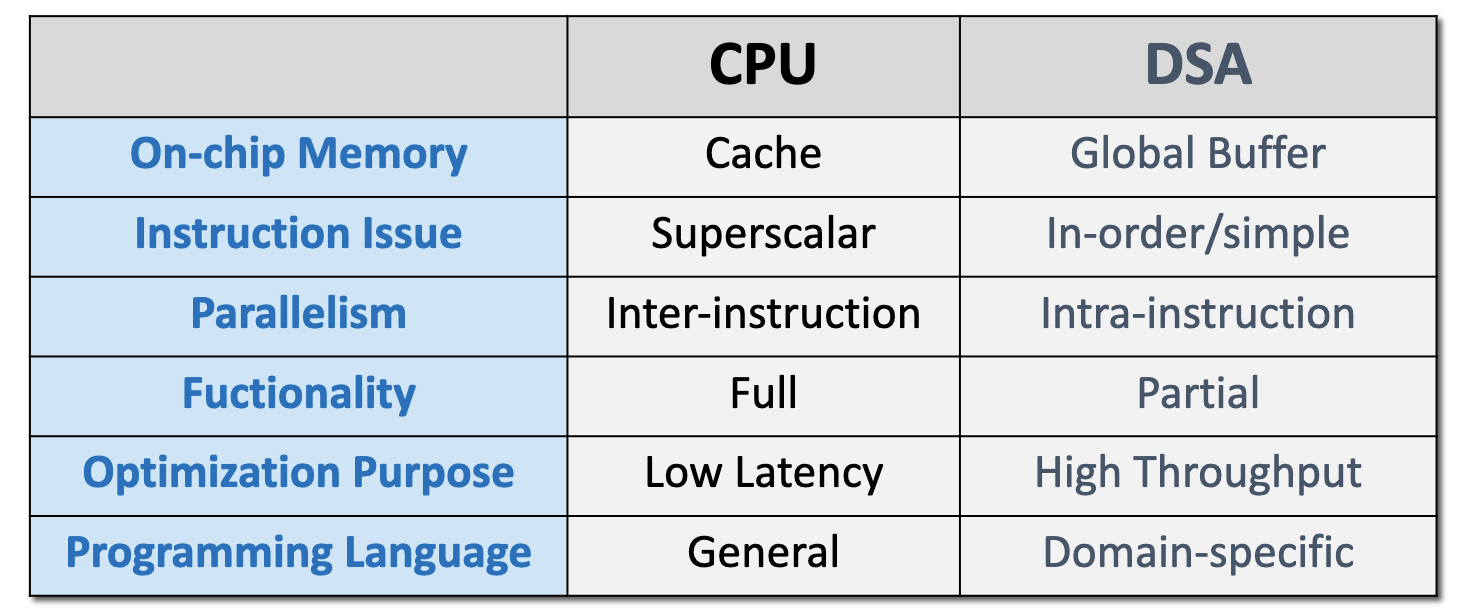
深度学习加速器设计思路
怎么设计深度学习加速器
矩阵乘法计算量的占比高于90%
- 支持矩阵、向量乘法
- 固定的内存访问模式
设计思路
- 并行计算模块:使用能够符合特定领域加速需求最简单的并行形式,例如,对于矩阵运算的加速,单条指令直接支持小矩阵运算
- Global Buffer:使用专有的存储器来减少数据搬运的距离和开销,将复杂的cache设计替换成scratchpad memory
- 简化控制模块:将缩减的高级微架构特性而节省出的面积,用于增加更多的运算单元或者片上的存储
- 量化:减少数据尺寸与类型来符合特定领域性能需求,例如,深度学习中,推理采用int8的量化方式
- 专用编程语言:使用DSA专用编程语言
与CPU的设计相反,CPU花了很多的资源在辅助功能上。CPU的五级流水线只有EXE在计算。
Global Buffer
复杂的Cache,strided内存访问容易竞争同一个cache set
使用专有的存储器来减少数据搬运的距离和开销,将复杂的cache设计替换成scratchpad memory
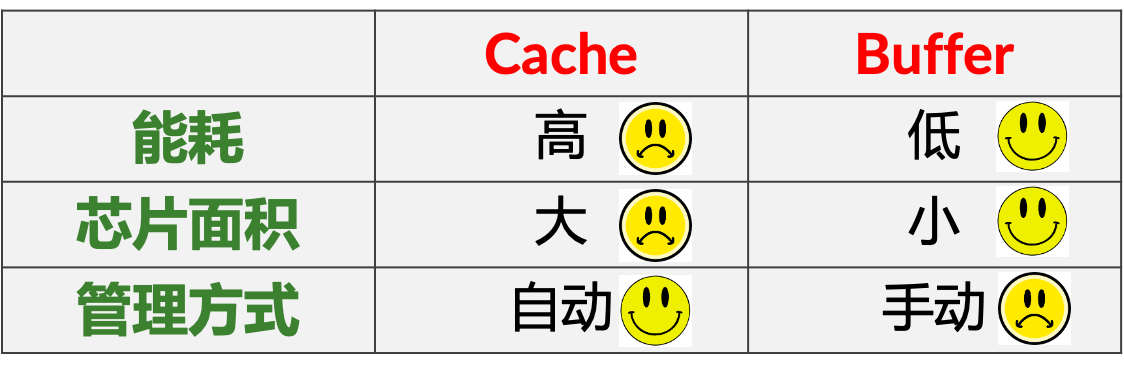
Cache:能耗高,芯片面积大,管理自动
Buffer:能耗低,芯片面积小,手动管理
简化控制模块
将缩减的高级微架构特性而节省出的面积,用于增加更多的运算单元或者片上的存储。减少复杂的控制逻辑。与CPU相反,只需要简单的控制模块即可。
量化
Why Low Precision Works for ML
- 低精度很多时候不会影响准确性
- 不同的任务可能需要不同的精度
并行计算模块
使用能够符合特定领域加速需求最简单的并行形式,例如,对于矩阵运算的加速,单条指令直接支持小矩阵运算。指令内部的并行,指令之间并行少(因为控制模块简化),指令内部并行多。
专用编程语言
用DSA专用语言进行编程
Lecture 12 AI processors
深度学习加速器设计目标
计算:很多的矩阵、向量的计算
访存:很对的外存访问,访问DRAM的能耗很大
目前的主要挑战:不足的算力,访存代价太大
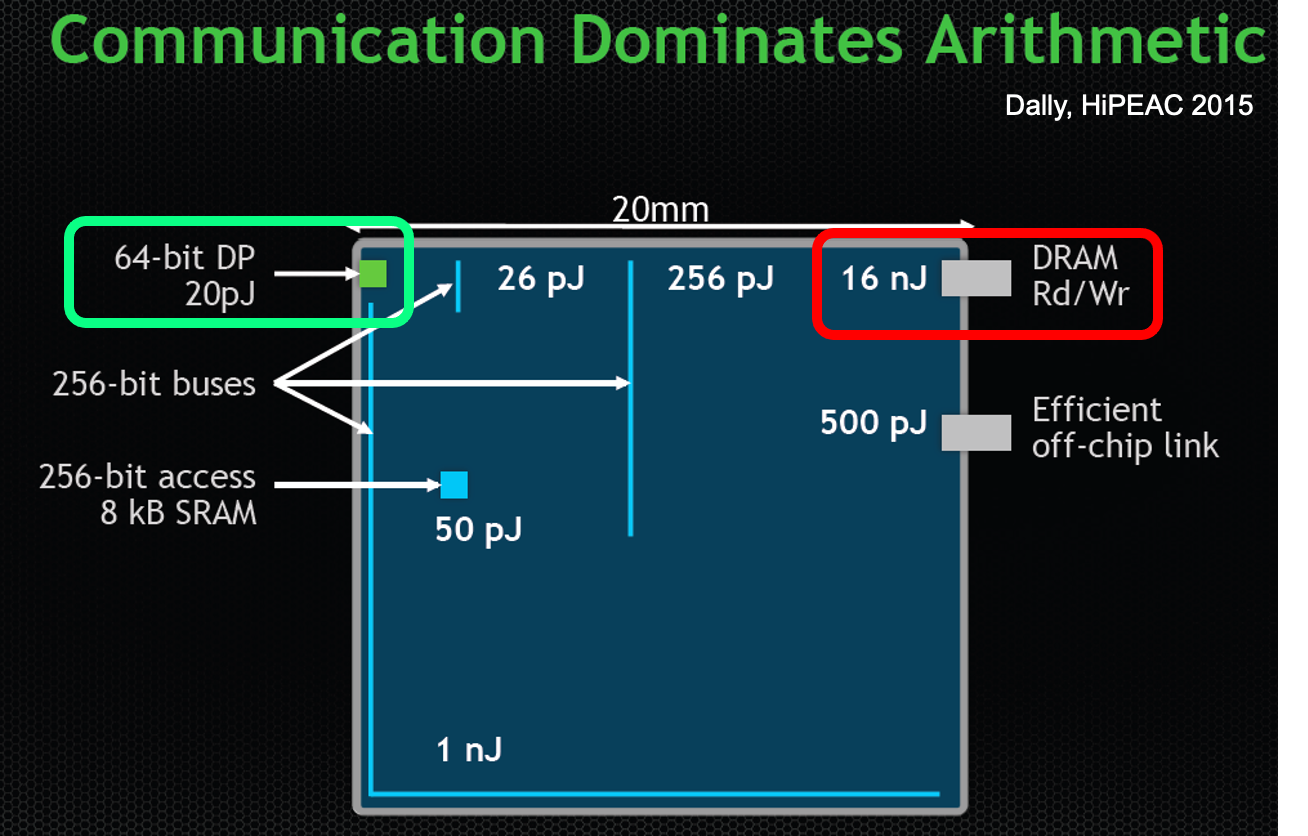
挑战
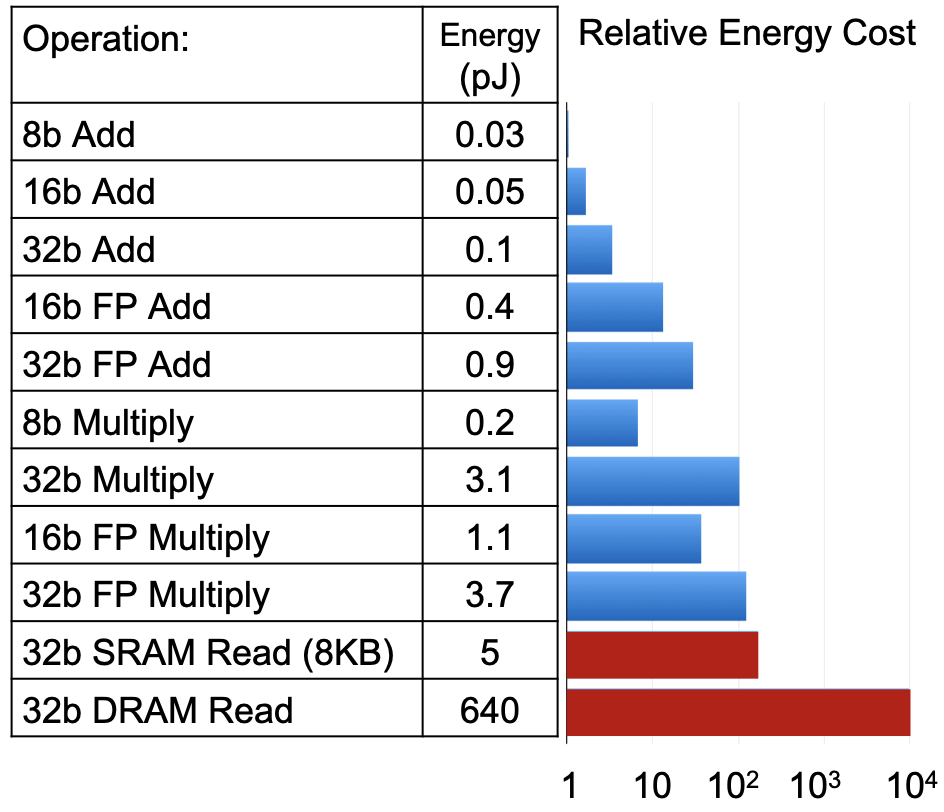
能耗分析:32bit的DRAM读比32bit的浮点乘法能耗高出两个数量级
目标任务:减少能耗高的操作,DRAM/SRAM Read、32bit Multiply
减少内存访问
为什么需要On-chip Buffer
使用片上内存,将一些数据存在片上,减少外部内存访问。
假设我们直接访问外部内存,计算能耗不多,在内存的存取上使用了很多的能耗。
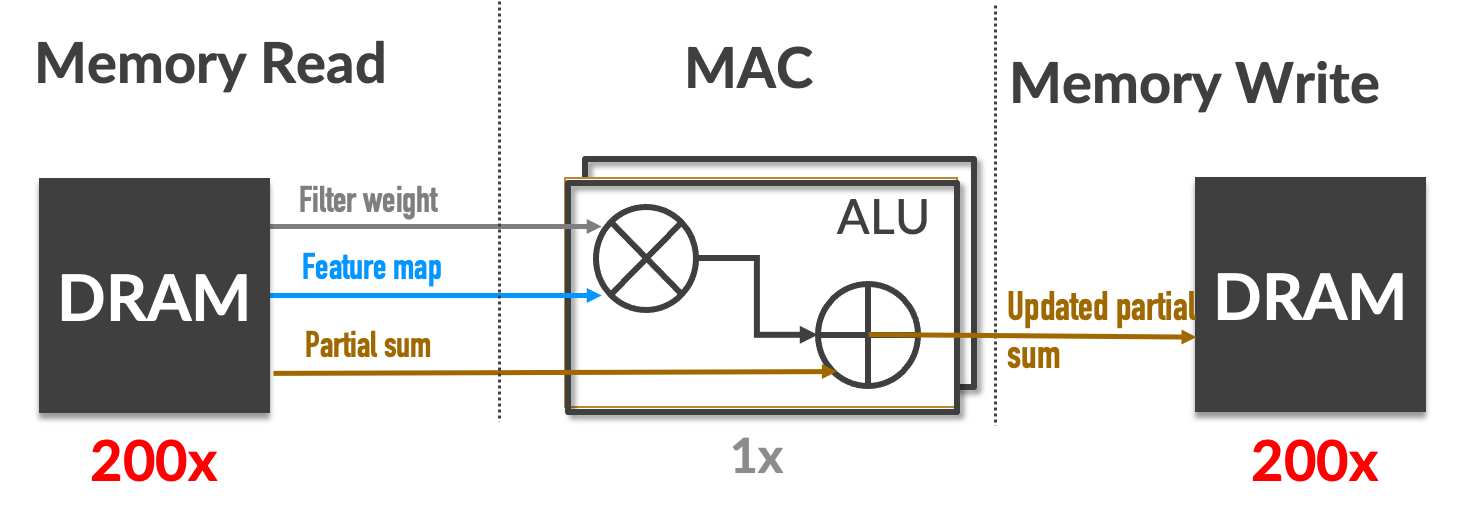
最差的情况是所有的内存读写都是访问外部内存
- AlexNet:需要724M的MAC操作和2896M次外部内存访问
Cache or Buffer
AI加速器的主要目标:提高算力、降低功耗
隐含的意思:可以牺牲可编程性
Buffer的能耗低,芯片面积小,因为无需额外的控制逻辑,但是管理方式是手动的。
Cache的能耗高,芯片面积大,需要有tag、比较等管理逻辑,但是管理方式是自动的。
Programming Model:Cache vs Buffer
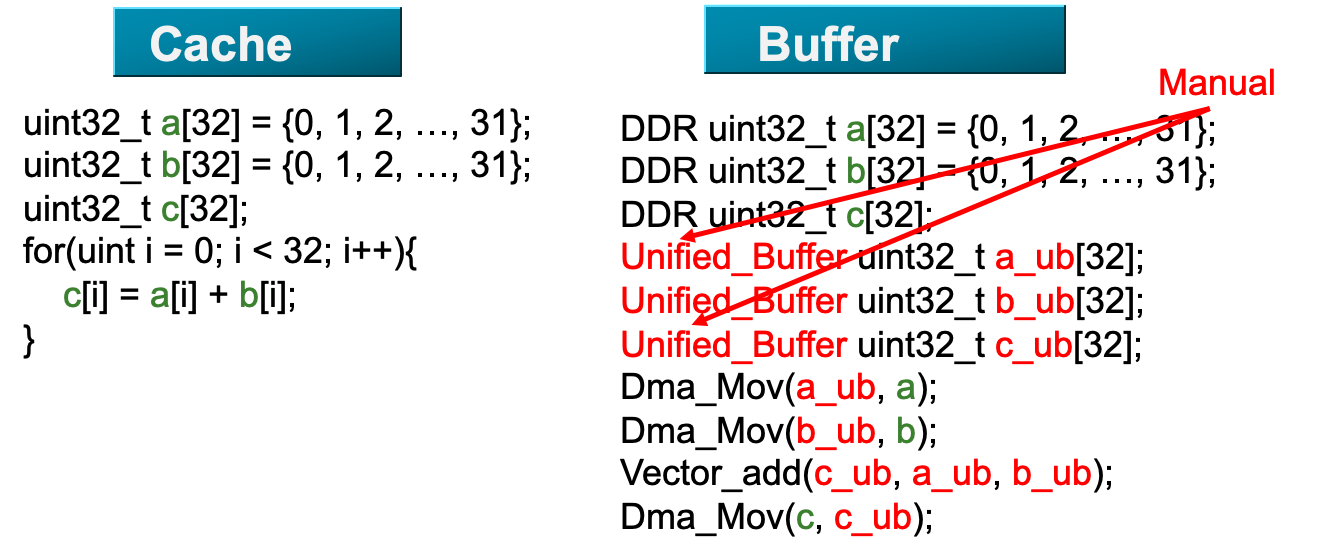
Cache编程简单,自动管理;Buffer编程需要人工管理buffer。
How to use buffer
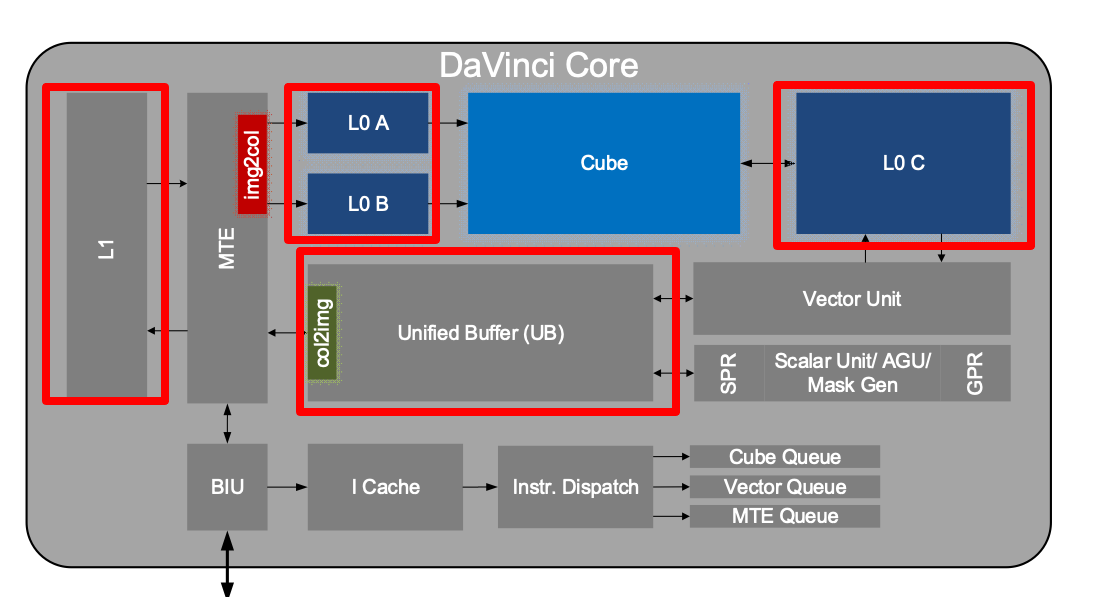
有三种buffer:
- L1:for MTE module,转运数据
- UB:for Vector module,向量
- L0 A/B:for Cube module,矩阵乘法
层级越低,能耗越小
编程时需要注意数据到底在哪个Buffer中
减少Global Buffer访问
recall:FF vs SRAM vs DRAM vs Flash

Problem:Global Buffer access is expensive
Solution:增加寄存器文件利用
AI芯片里面用的Buffer是SRAM
Weight Stationary
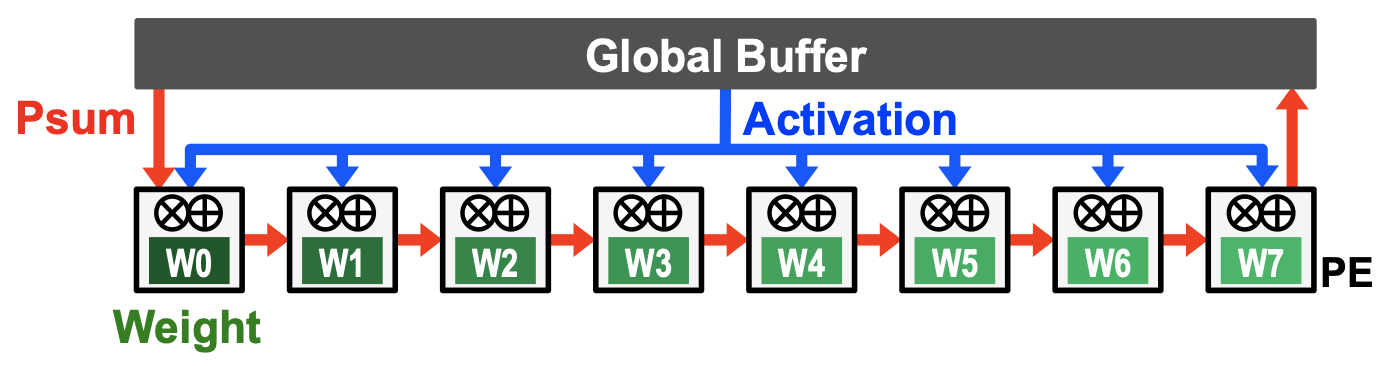
- Key idea
- 最大程度减少从Global Buffer读取weight,将weight放进寄存器中
- 广播Activations和沿着PE方向上累加Psum
Output Stationary
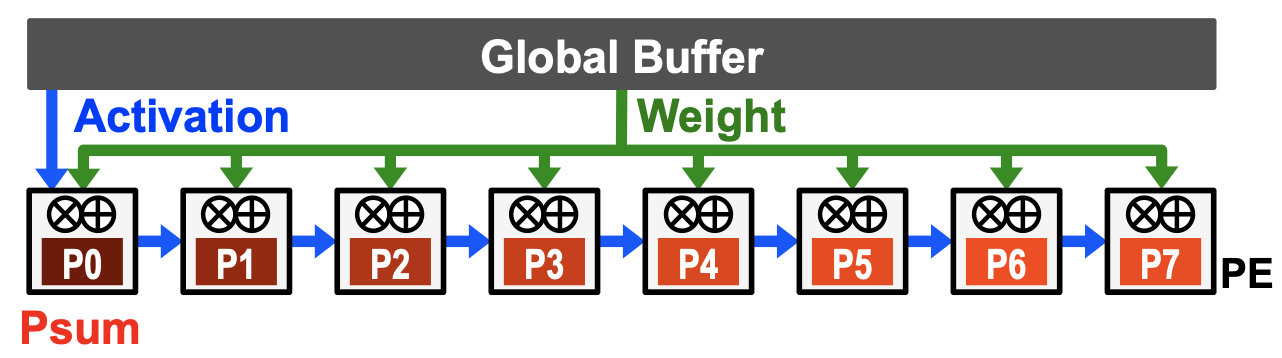
- Key idea
- 最大程度减少从GB中读取和存储Psum,尽量把Psum留在PE内部
- 广播weight和沿着PE方向上复用Activation
Input Stationary
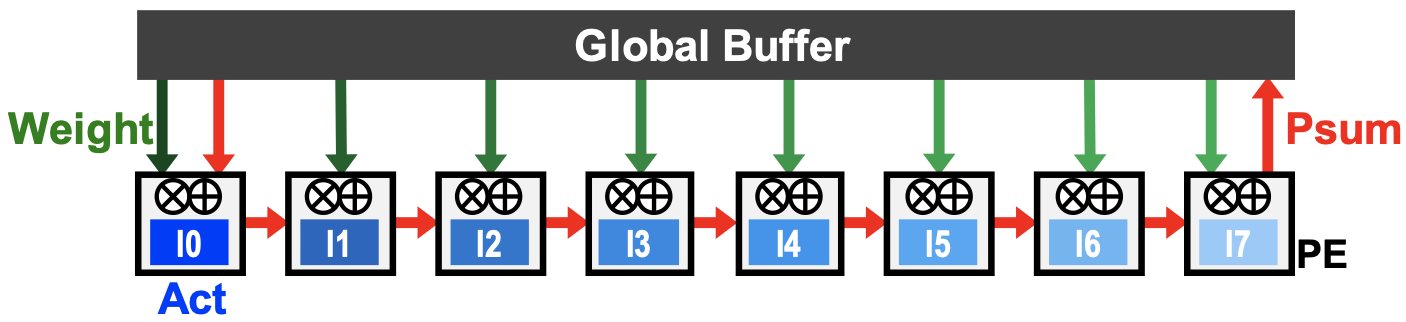
- Key idea
- 最大程度减少从GB中读取Activation,尽量把Activation留在PE内部
- 并行读取weight和沿着PE方向上累加Activation
Row Stationary
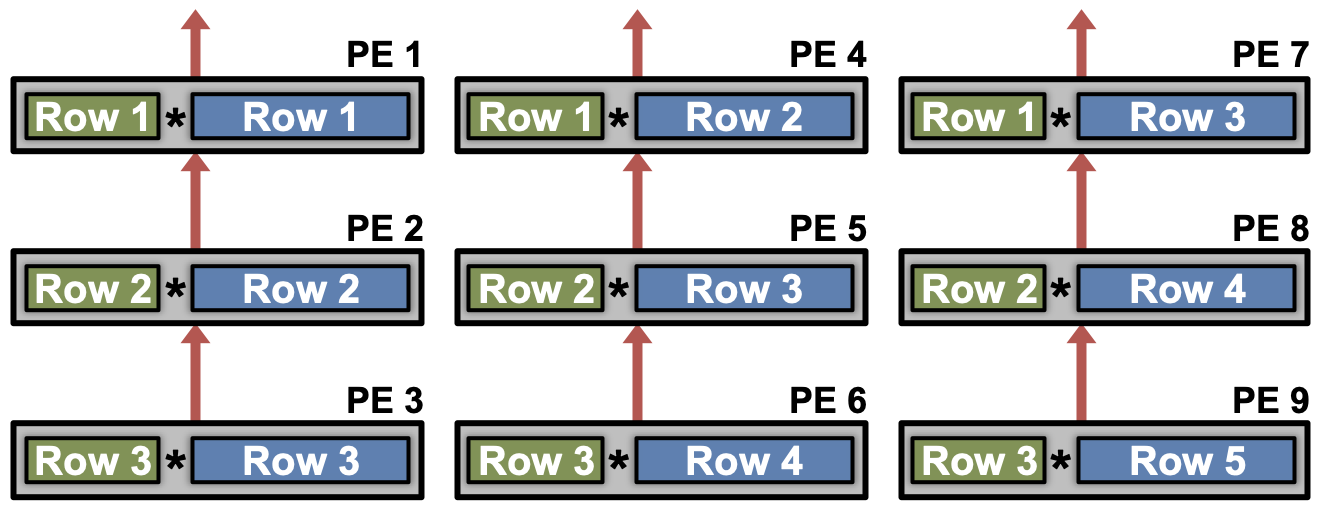
- Key idea
- 从GB读出Filter中的一行和Activation的一个滑窗,留在PE内部
- 尽量减少从GB的整体读出量,而不是一个维度的
增加计算
AI相关计算量里,矩阵乘法计算量的占比高于90%。尽可能使用定制计算单元,提升计算密度。
矩阵乘法单元

- Scalar:标量实现
- 周期数:161616
- 每周期内存访问量:2 rd,1/16 wr
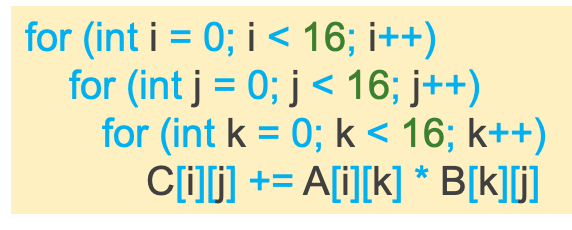
- Vector:向量操作
- 周期数:16*16
- 每周期内存访问量:2*16 rd,1 wr

- Matrix:矩阵操作
- 周期数:1
- 每周期内存访问量:21616 rd,16*16 wr
算力密度逐渐变高,但是灵活度逐渐变低
计算模块
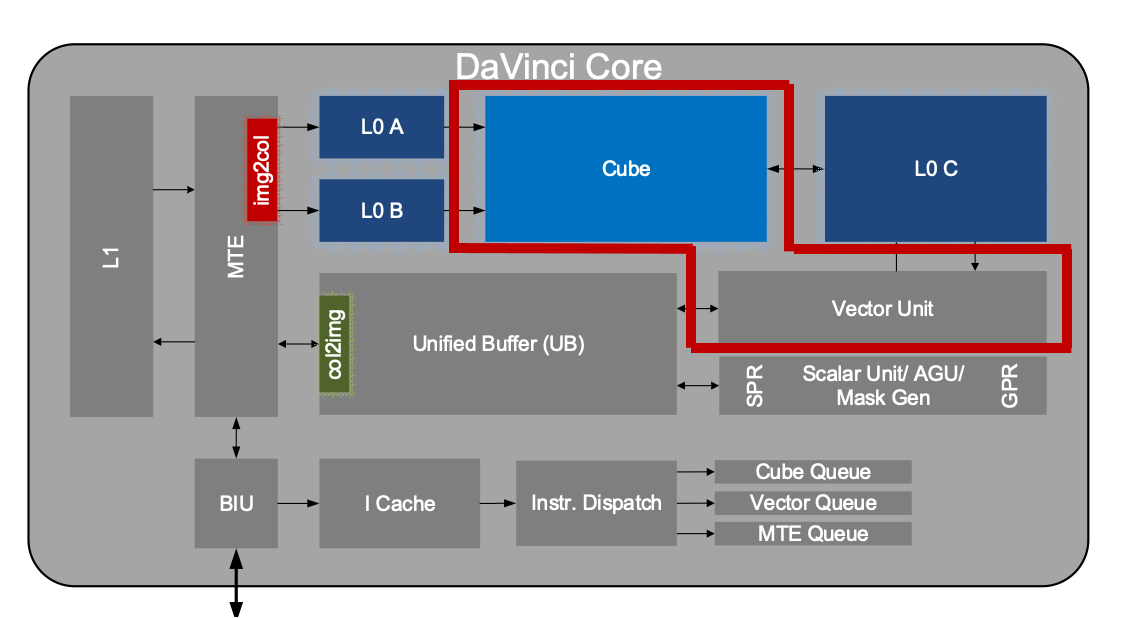
- Cube模块(算力核心)
- 单指令处理小矩阵乘法
- Vector模块(算力核心)
- 单指令处理向量操作,如activation激活
常见AI加速器分析比较
华为Ascend
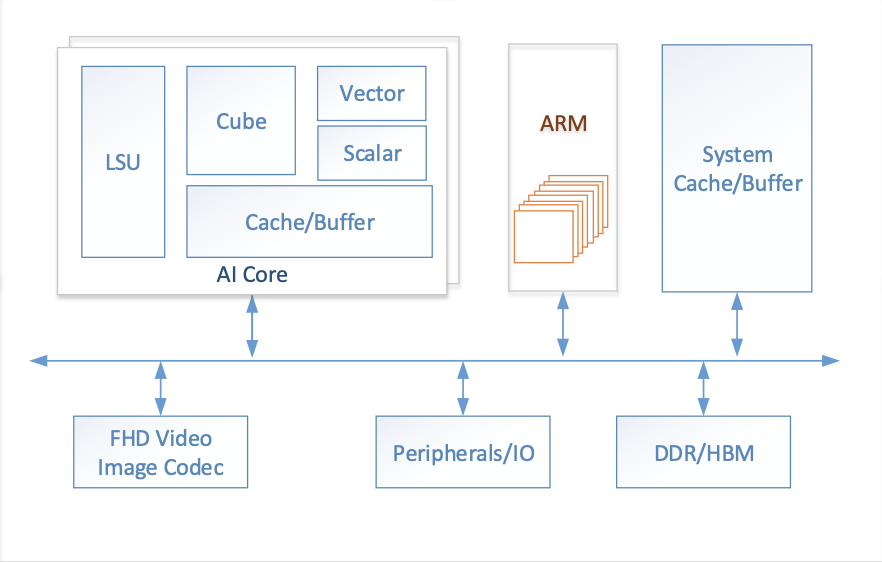
AI Core内部的结构
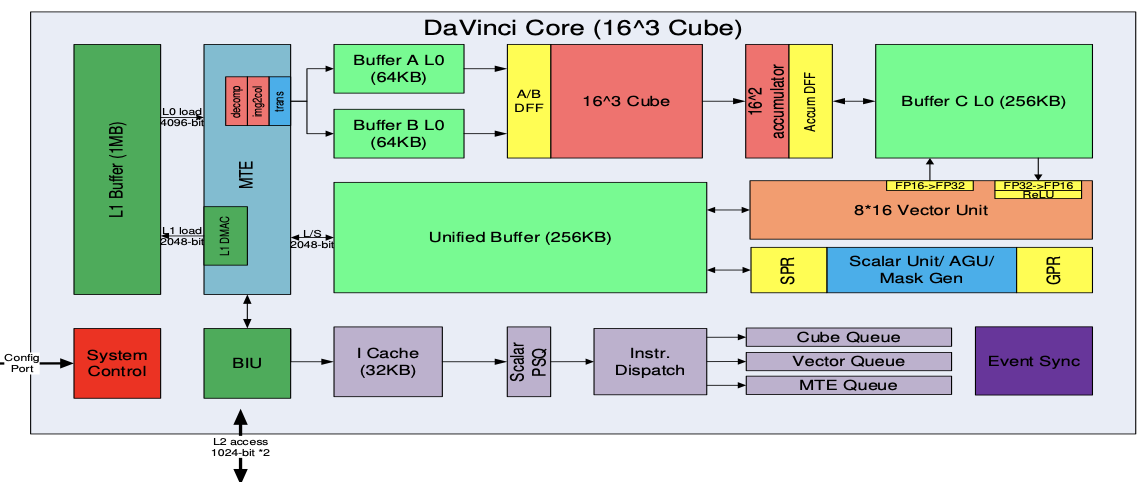
Cube模块(矩阵运算,算力担当)
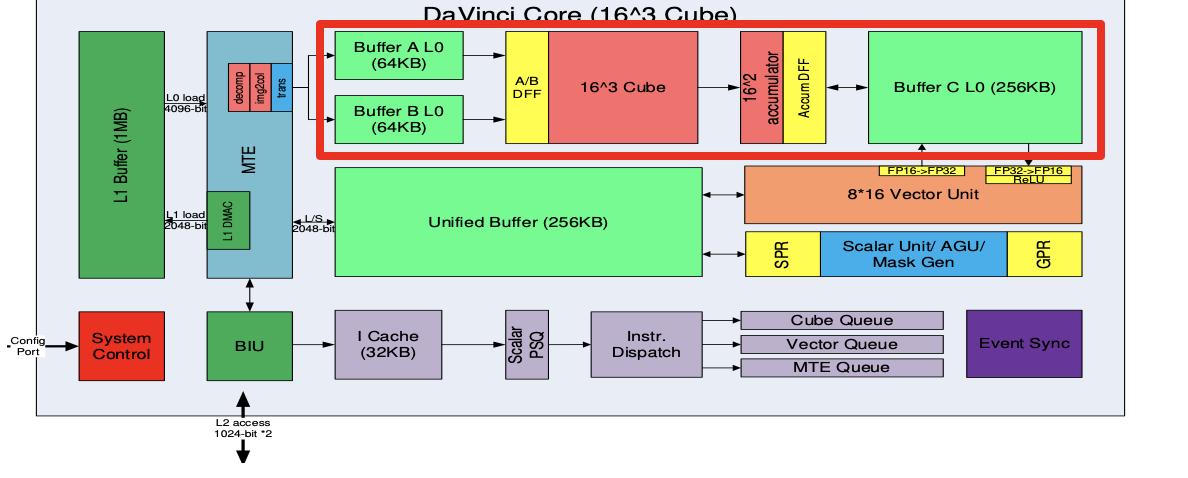
- 矩阵乘运算单元Cube:一拍完成一个fp的2个1616矩阵相乘。C=AB,如果是int8输入,则一拍可以完成1632与3216的矩阵运算
- 累加器Accumulator:把当前矩阵乘结果和前次计算的中间结果相加(C=A*B+C),可以用于完成卷集中的加bias的操作
- L0A/L0B/L0C Buffer:L0A存储矩阵乘的左矩阵数据,L0B存储矩阵乘的右矩阵数据,L0C存储矩阵乘的结果和中间结果
- A/B DFF:数据寄存器,缓存当前计算的16*16的左/右矩阵
- Accum DF F:数据寄存器,缓存当前计算的16*16结果矩阵
Vector模块(向量运算,多面手)
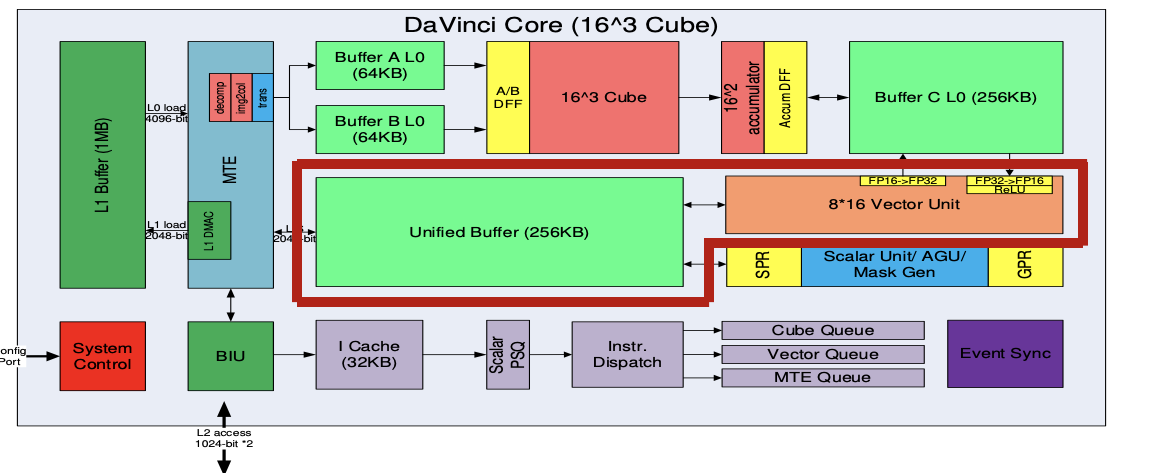
- 向量运算单元Vector Unit:覆盖各种基本的计算类型和许多定制的计算类型,主要包括FP16/FP32/int32/int8等数据类型的计算,支持连续或者固定间隔寻址;或者VA寄存器寻址(不规则向量运算)
- SIMD长度:一条Vector指令可以完成两个128长度fp16类型的向量相加/乘, 或者64个fp32/int32类型的向量相加/乘
- Unified Buffer(UB): 保存Vector运算的源操作数和目的操作数; 一般要求32Byte对齐
- 数据从L0C->UB,需要以Vector Unit作为中转,并可以随数据搬运完成一些RELU/数据格式转换等操作
Scalar模块(标量运算,司令部)
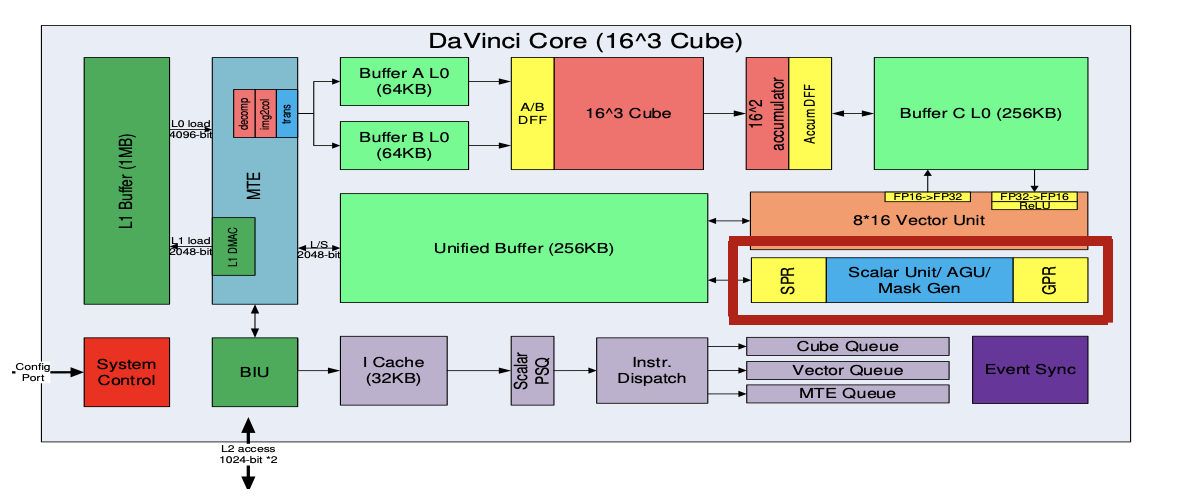
- Scalar Unit: 负责完成AICore中的标量运算,功能上可以看做一个小CPU;完成整个程序的循环控制、分支判断、CUBE/Vector等指令的地址和参数计算以及基本的算术运算等‘
- Unified Buffer or Scalar Buffer: 晟腾310/910 Scalar Unit不能直接访问外面的DDR/HBM, 需要预留UB的一部分(310)或者使用专门的Scalar Buffer(910)用作Scalar Unit的堆栈空间
- GPR:通用寄存器,目前包含32个通用寄存器
- SPR: 专用寄存器,为了支持指令集一些指令的特殊需要,Davinci设计了许多专用寄存器,比如CoreID, BLOCKID, VA, STATUS, CTRL等寄存器
MTE/BIU和片上高速存储Buffer
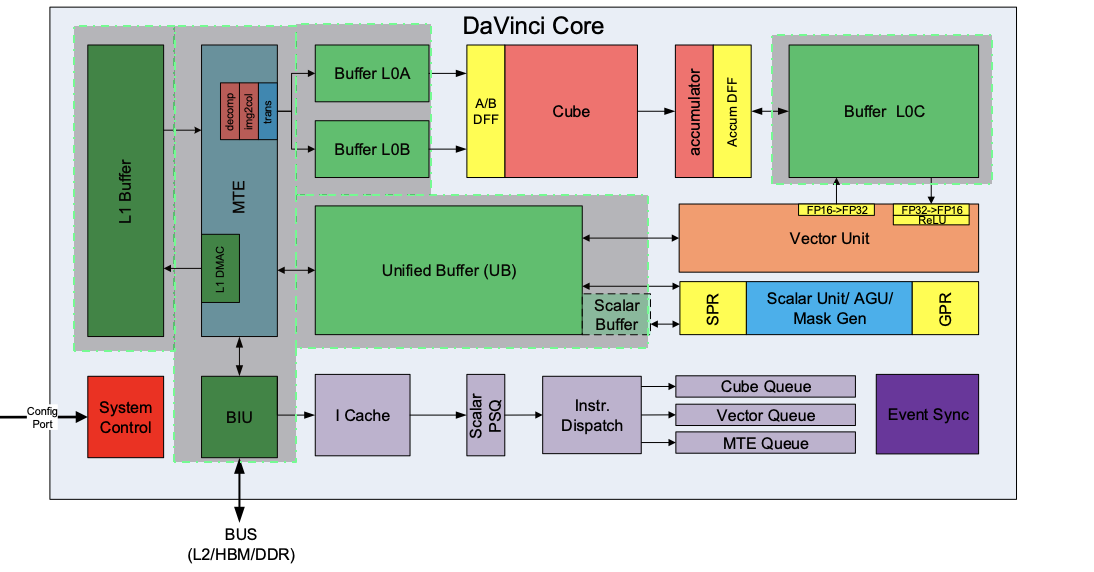
- BIU (Bus Interface Unit): AICore 的“大门”,与总线交互的接口。AICore从外部(L2/DDR/HBM)读取、写入数据的出入口。负责把AICore的读写请求转换为总线上的请求并完成协议交互等工作。
- MTE (Memory Transfer Unit): 也被称作 LSU (Load Store Unit), 负责AICore内部数据在不同Buffer之间的读写管理,以及完成一些格式转换的操作,比如padding, 转置, Img2Col, 解压等
- L1 Buffer: AICore内最大的一块数据中转区(1MB),可以用来暂存AICore需要反复使用的一些数据从而减少从总线读写; Img2col操作等MTE的数据格式转换功能需源数据必须位于L1 Buffer
- L0A/L0B/L0C/UB/Scalar Buffer: 前面已介绍
指令和控制系统
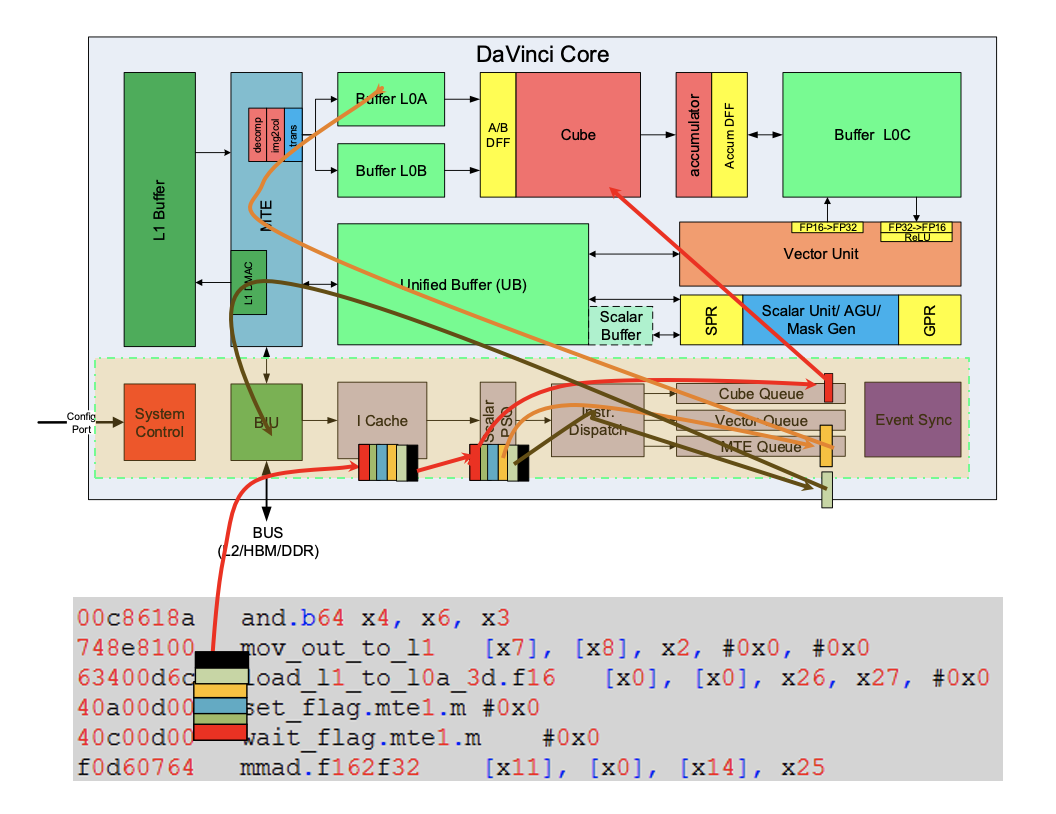
指令从BIU进来,到I cache中再进入指令处理队列进行分布,针对不同指令的计算属性,分发到不同的对应的Queue中
- I Cache: AICore内部的指令Cache, 具有指令预取功能
- Scalar PSQ: Scalar 指令处理队列
- Instr Dispatch: 指令分发模块, CUBE/Vector/MTE 指令经过Scalar PSQ处理之后,地址、参数等要素都已经配置好,之后Instr Dispatch单元根据指令的类型,将CUBE/Vector/MTE指令分别分发到对应的指令队列等待相应的执行单元调度执行
- Cube/Vector/MTE1/MTE2/MTE3 Queue: Cube/Vector/MTE1/MTE2/MTE3指令队列;同一个队列里的指令顺序执行;不同队列之间,可以并行执行

Google TPU
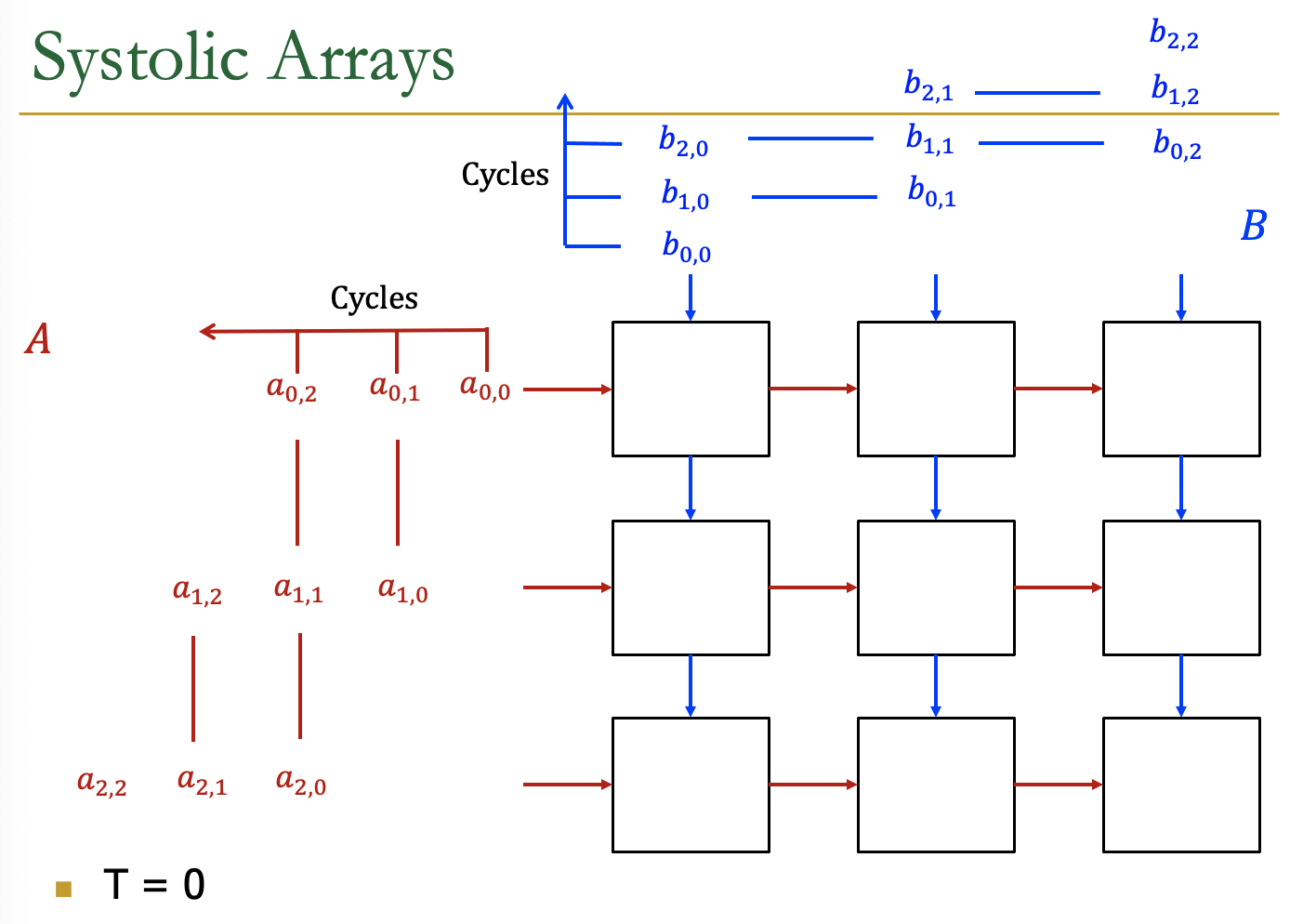
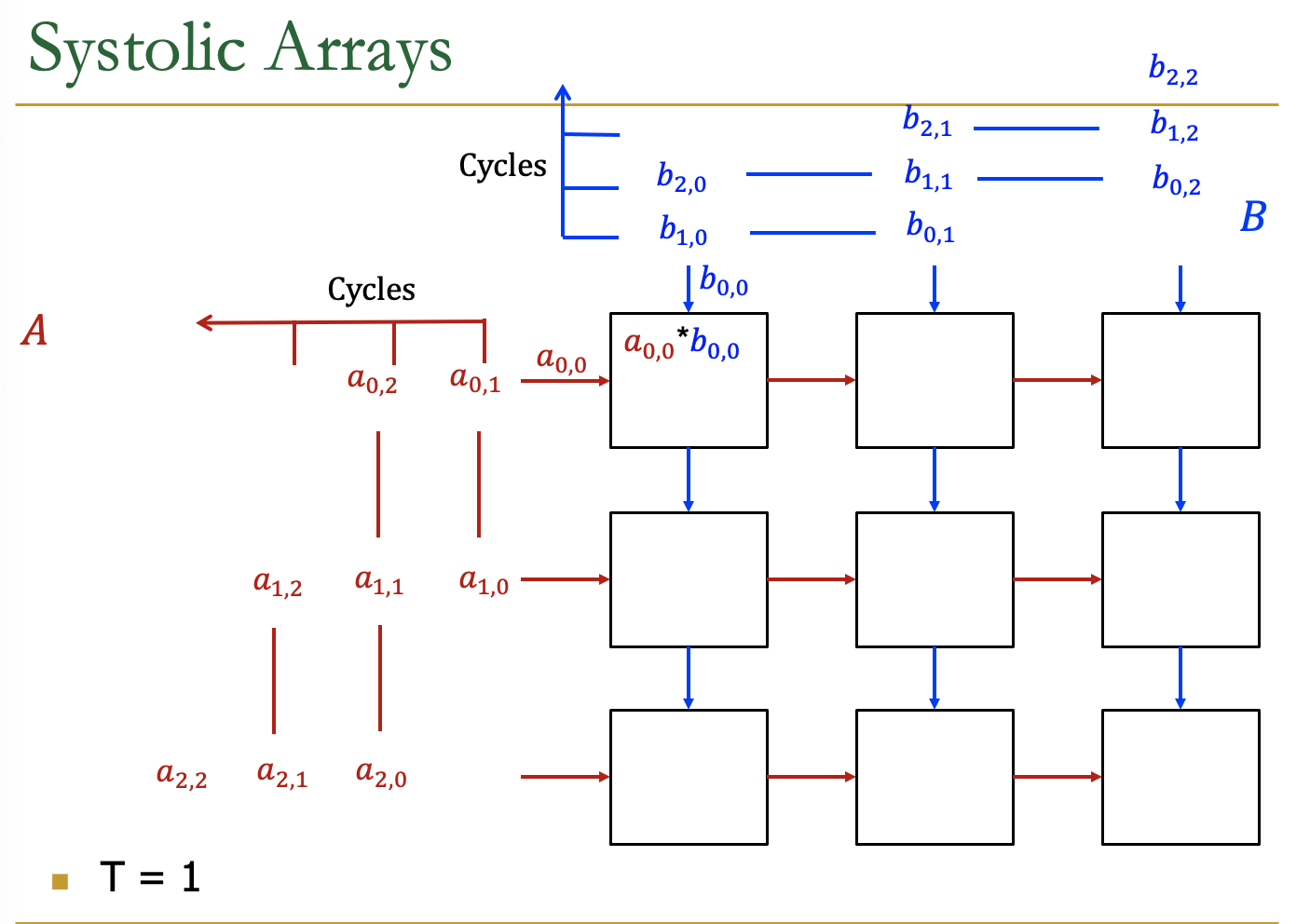
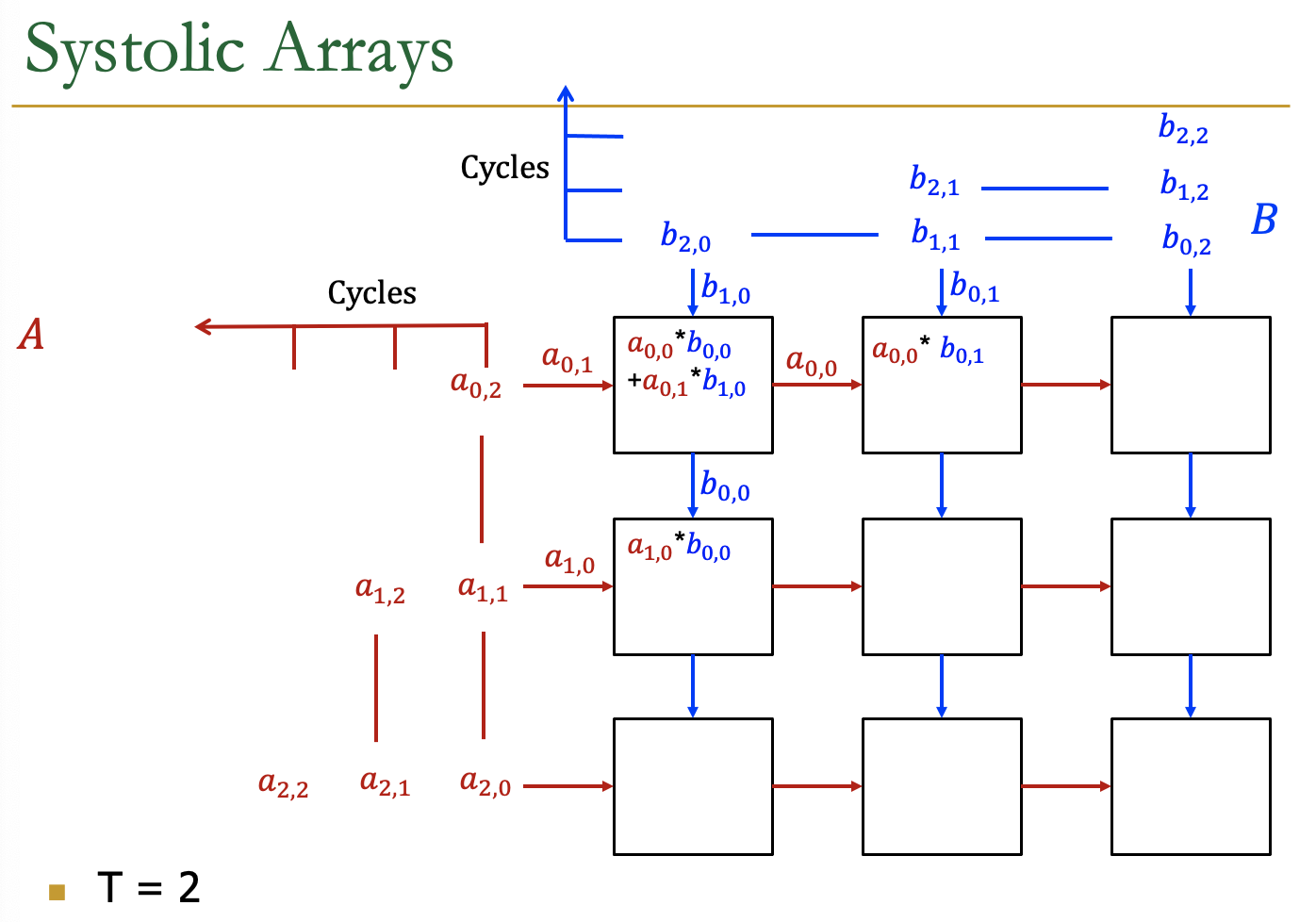
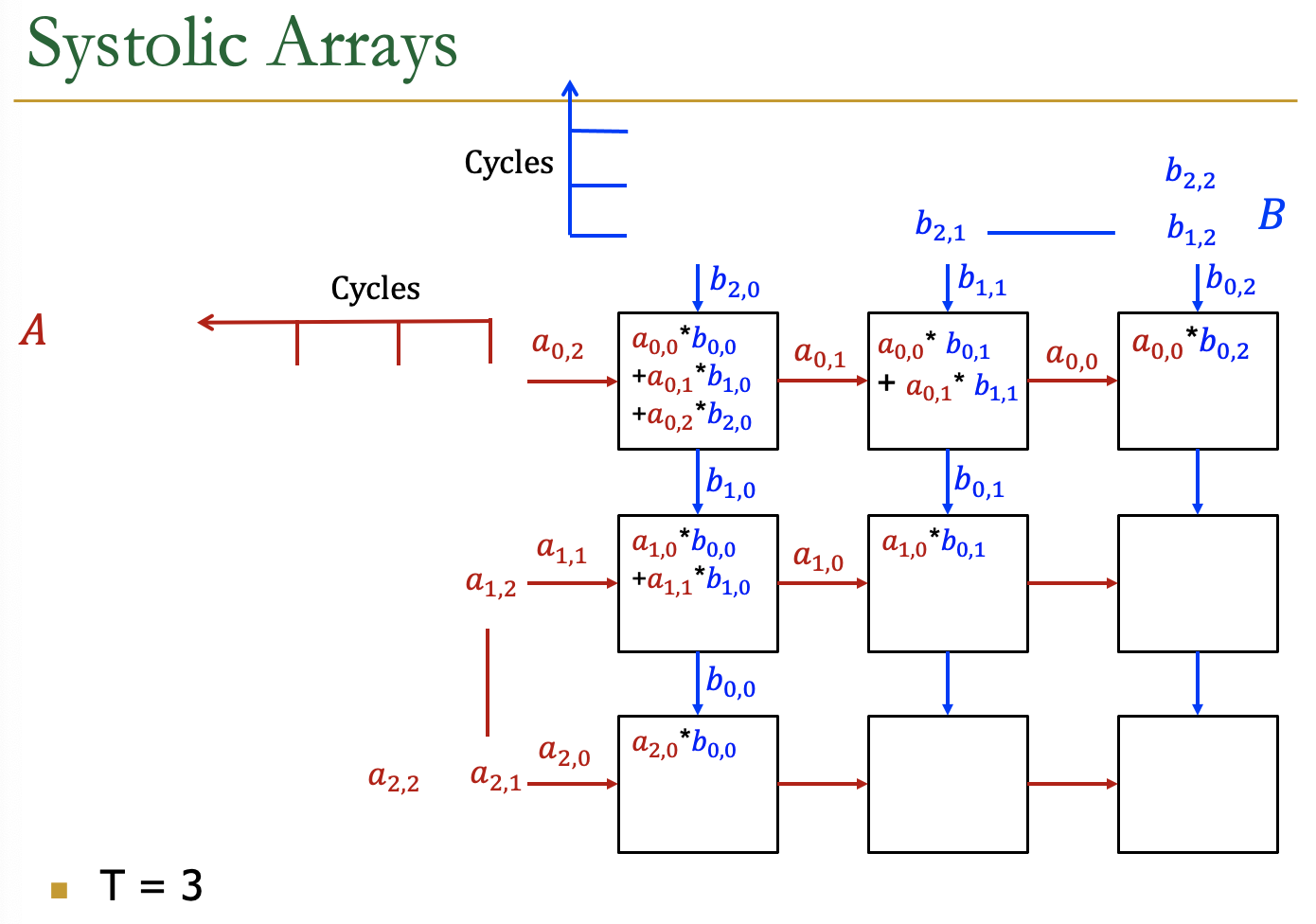
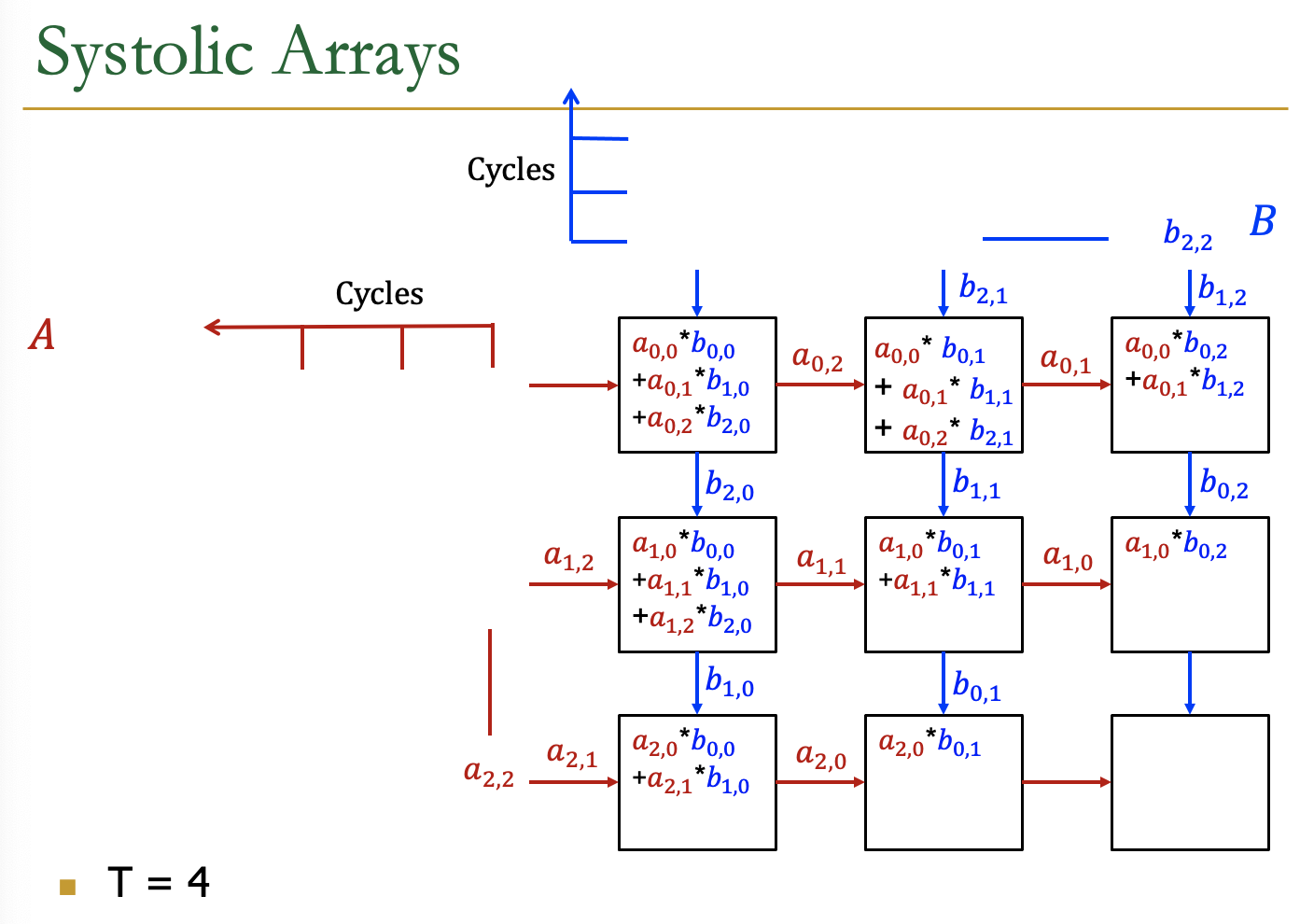
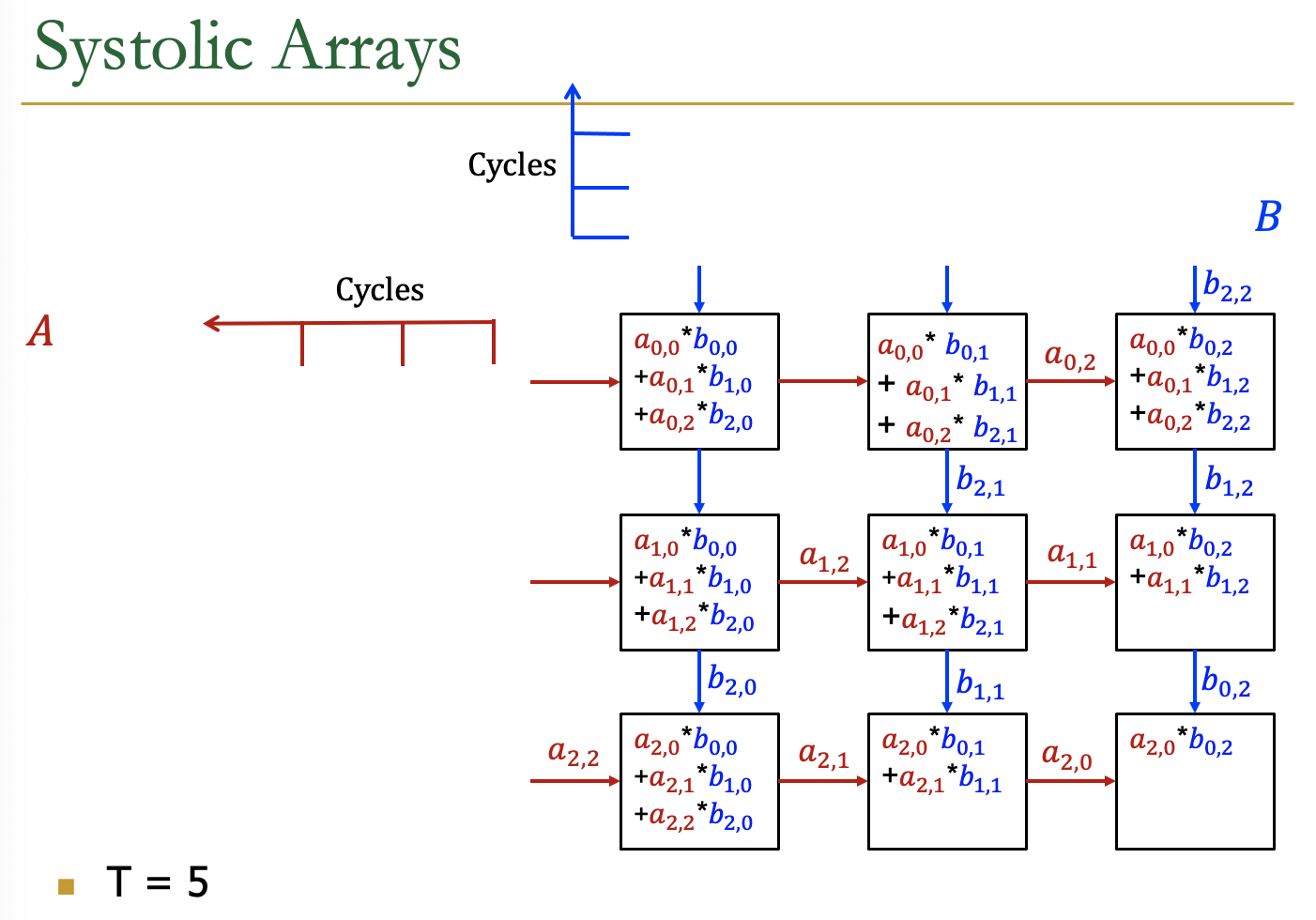
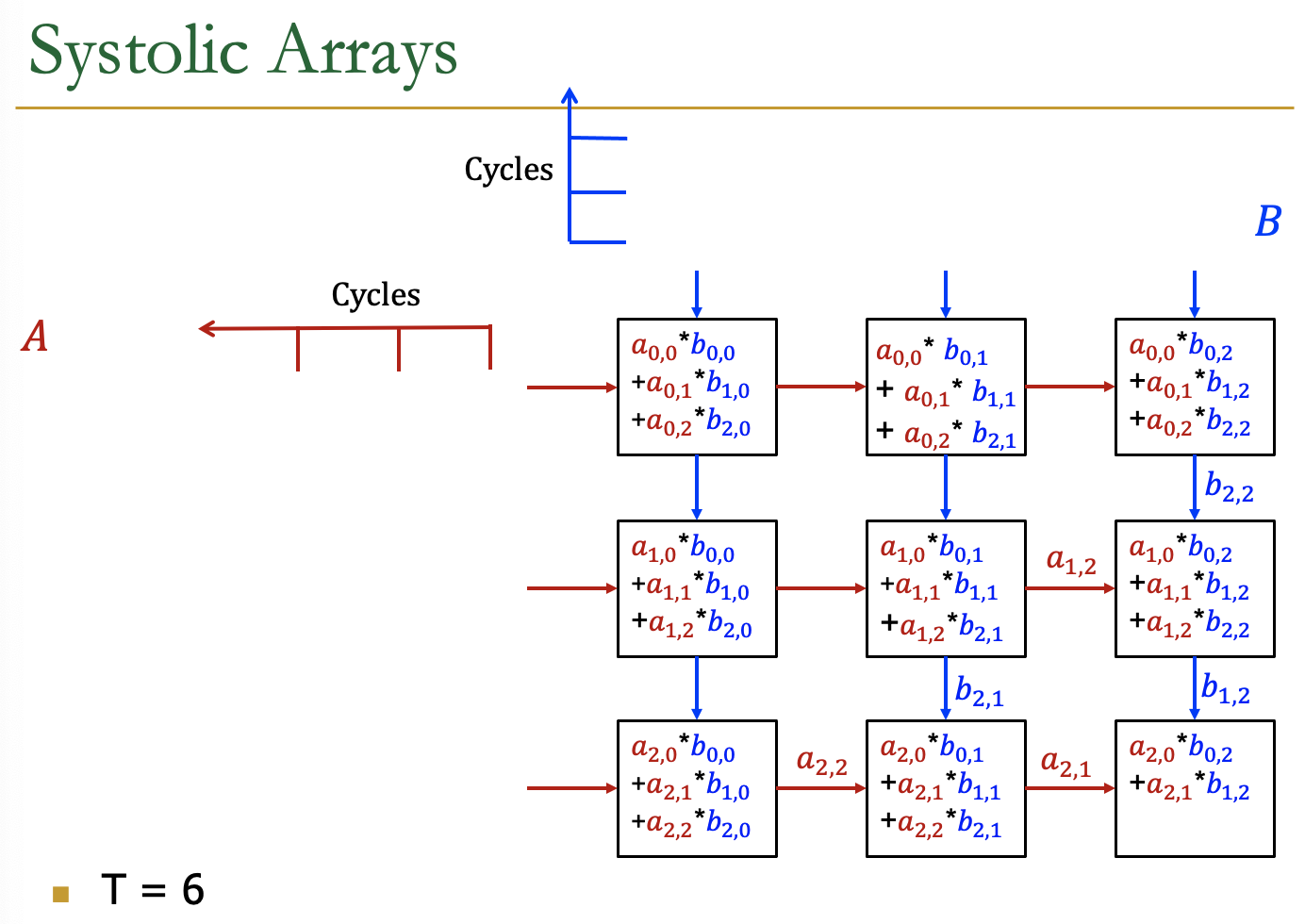
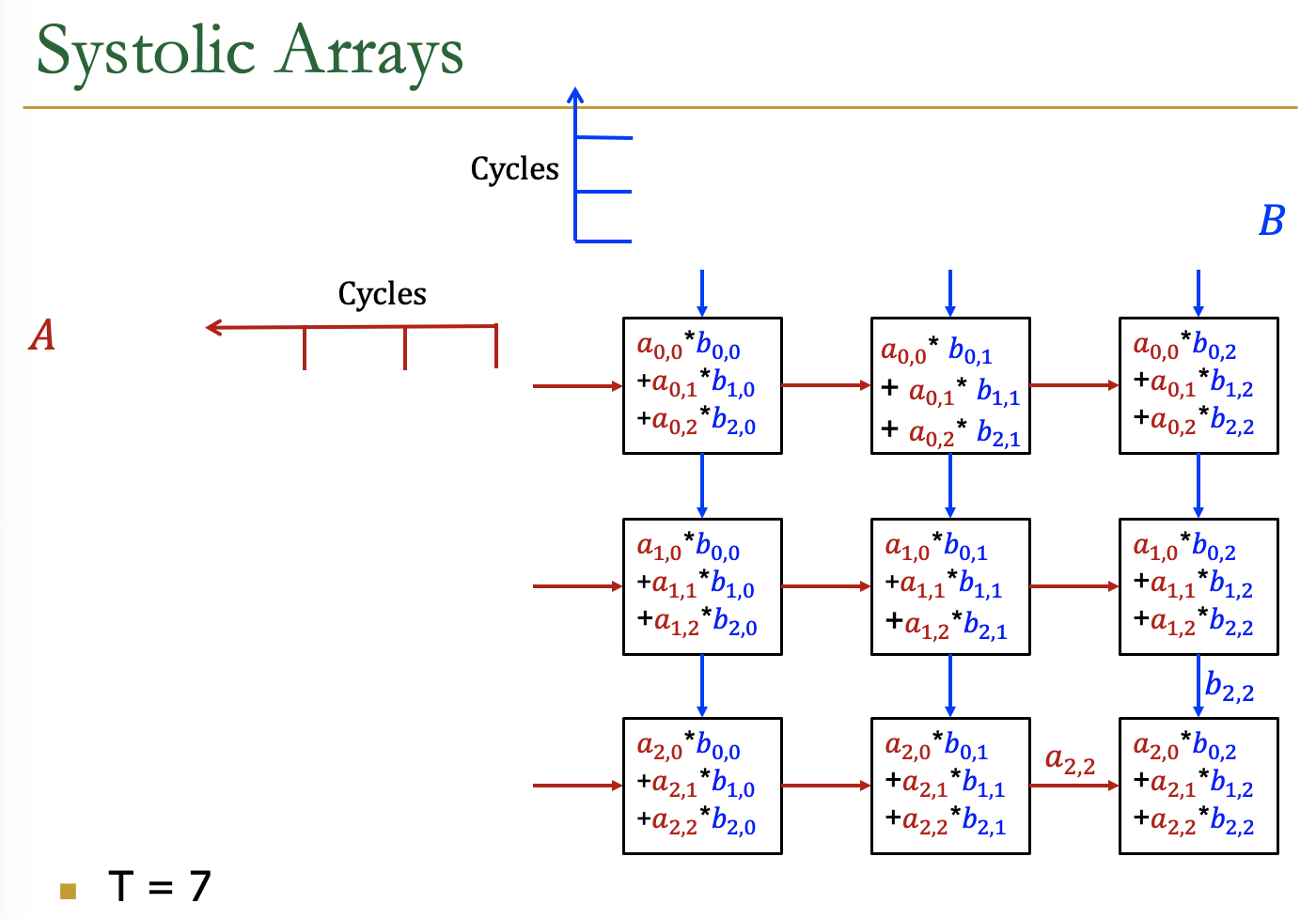
Systolic Arrays

- Goal:设计一个加速器
- 简单,规则的设计(保持#独特的部分小而规则)
- 高并发→高性能
- 均衡的计算和I/O(内存)带宽
- Idea:用一个Processing Element PE的regular
Array替换PE,并仔细编排PEs之间的数据流
- 这样,它们在将输入数据输出到存储器之前共同对其进行转换
- Benefit:最大限度地提高从内存中取出的单个数据元素的计算量
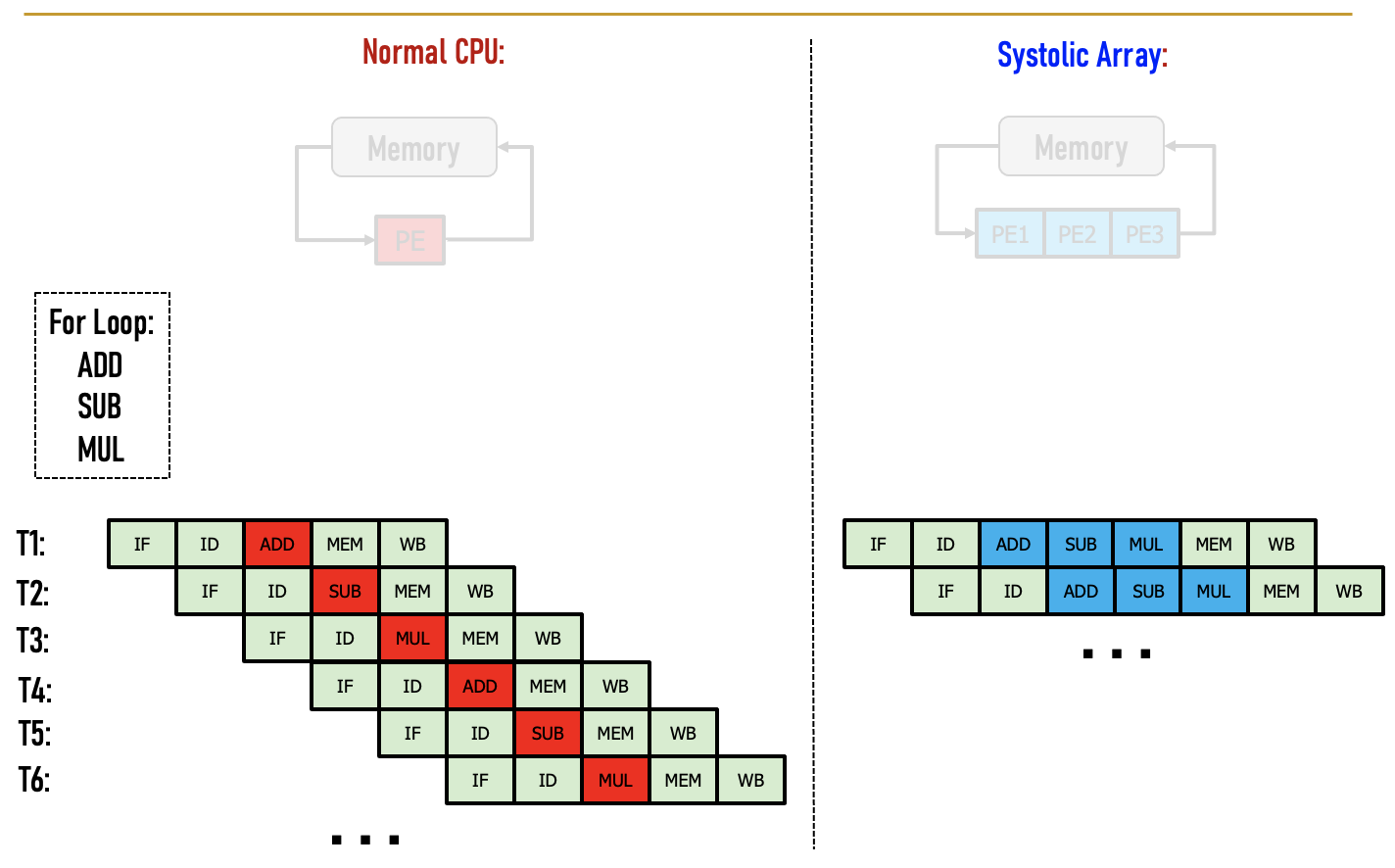
AI加速器中的Systolic Arrays。
二维的Systolic array
每一个PE是一个cell,接受来自左方和上方的输入,右方和下方传递左方和上方的值
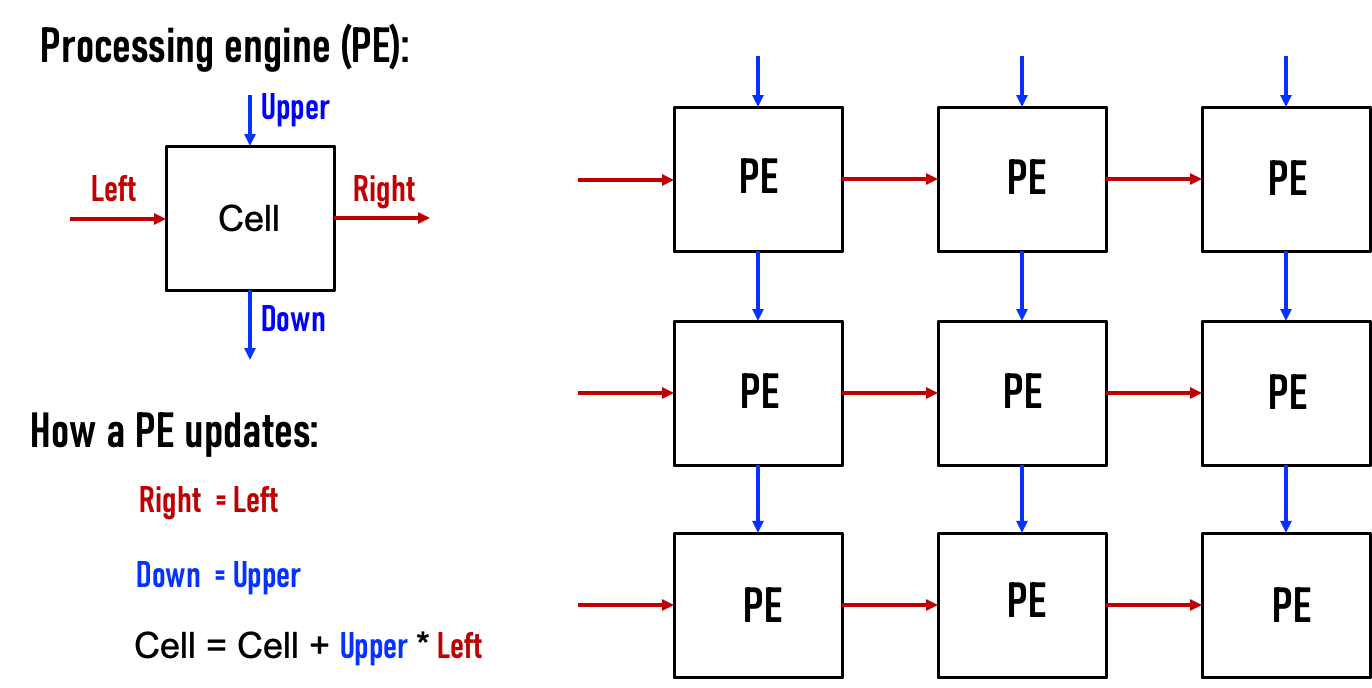
矩阵的数据传输时,是有时间顺序的,类似于一个平行四边形的方式传入
Example
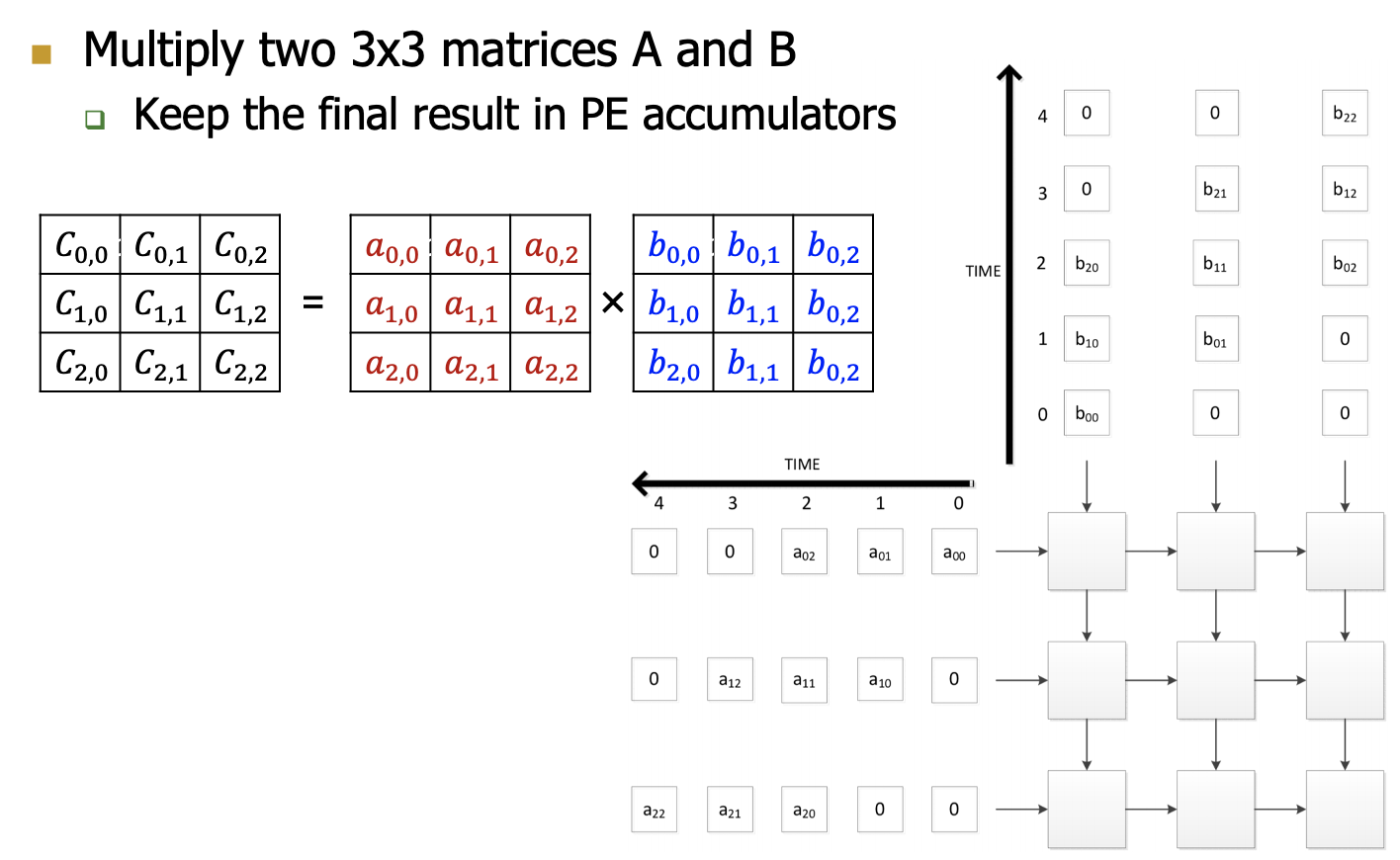
各个周期的计算情况
Cambricon寒武纪
- Cambricon尝试解决两个问题
- How to increase performance/power ratio?如何提升性能/功耗比例
- How to increase programmability?如何提升可编程性
- 目标:
- 设计一个高性能比,高可编程性的深度学习加速器
- DLP-S AI加速器
Overall Architecture of DLP-S
- Control Module
- IFU:Instruction Fetch Unit
- IDU:Instruction Decode Unit
- Compute Unit
- VFU:Vector Function Unit
- MFU:Matrix Function Unit
- SRAM Unit
- WRAM:Weight RAM
- NRAM:Neuron RAM
- DMA:Direct Memory Access
控制模块
- 一些比较简单的控制流
- IF、ID、Issue模块
- IFU
- 地址生成模块,生成PC
- 指令Cache,Hit了直接把指令放队列
- refill buffer,cache miss了要用这个从DRAM中读取指令
- 指令Queue
- IDU
- Decoder,解码指令,并且根据指令内容
- ALU
- Issue Queue
- Control Inst
- Compute Inst
- Memory Access Inst
- Instruction Issue Queue
- 执行顺序:
- 控制指令队列
- 运算指令队列
- 访存指令队列
- Between Queue:是乱序的,inserting SYNC instruction between instruction queues
- In Queue:是顺序执行的
- 执行顺序:
计算模块
- Matrix Inst
- Vector Inst
SRAM模块
- 权重SRAM
- 激活SRAM
- 分开管理更加高效
- SRAM都是用DMA操作
数据流
推理的过程:
- 神经元流
- DRAM-NRAM-VPU-(MFU-VFU-)NRAM-DRAM
- 权重tensor数据流
- Execution Flow
- Step1:IFU通过DMA从DRAM中
DLP ISA
- 控制指令:跳转、条件分支
- 数据转移指令:矩阵、向量、标量
- 计算指令:矩阵、向量、标量
- 逻辑运算指令:向量、标量
Lecture 13 Parallel Training
overview of Architecture of DLP-S 寒武纪芯片的架构
- 控制单元
- IF、ID单元
- 计算单元
- 向量、矩阵计算单元
- SRAM单元
- 权重SRAM
- Neuron RAM
- DMA,都是Direct Memory Access
- 控制单元
AI Architecture
- Parallel Training
- AI Framework
- mindspore、pytorch、tensorflow
- AI Runtime
- 计算加速库CANN
- AI Chip
AI+科学计算
科学计算的核心问题是微分方程求解,算力消耗巨大,大规模求解器垄断
Parallel Training
- 模型训练的例子
- 比如说我们训练一个三层的全连接网络
- 随机初始化权重
- mini-batch的迭代训练
- 前向
- 反向
- 权重更新
- minibatch为1
- 每一层输入:向量
- 输出:向量
- 权重参数:矩阵
- 操作:向量乘以矩阵再进行激活如ReLU
- minibatch不为1
- 每一层输入:矩阵
- 输出:矩阵
- 权重参数:矩阵
- 操作:矩阵乘以矩阵再进行激活如ReLU
- Loss function
- 计算误差,我们的目标是减小误差
- 误差反向传播,计算权重梯度和激活函数的梯度
- 权重更新
- SGD
- W=W-lr*dW
- Momentum
- v=μv-lr*dW
- W=W+v
- AdamW
- SGD
Parallelism Taxonomy
- Parallel Training
- Data Parallel
- Model Parallel
- Intra Layer
- Inter-layer
Data Parallel Training
有很多的worker(GPU),每一个worker都是一个神经网络的一个copy
数据部分则是worker平分数据
比如有4个worker的情况:
- stronge scaling:minibatch不变的,原来一个X是416的,现在每个worker只用算116的矩阵
- weak scaling:minibatch原来是8的,现在每个worker的minibatch是2
- 反向传播时需要聚合每个worker的dW
- 梯度更新:
- N个worker加和梯度:算术平均
- 每一个worker更新权重
AllReduce Implementation Choices
[https://zhuanlan.zhihu.com/p/69797852]
同步更新模式下,所有GPU在同一时间点与参数服务器交换、融合梯度;
异步更新模式下,所有GPU各自独立与参数服务器通信,交换、融合梯度。
- 异步更新通信效率高速度快,但往往收敛不佳,因为一些速度慢的节点总会提供过时、错误的梯度方向。可通过上一篇介绍的Stale Synchronous Parallel Parameter Server方法缓解该问题。
- 同步更新通信效率低,通常训练慢,但训练收敛稳定,因为同步更新基本等同于单卡调大 的batch size 训练。
但是传统的同步更新方法(各个gpu卡算好梯度,求和算平均的方式),在融合梯度时,会产生巨大的通信数据量,这种通信压力往往在模型参数量很大时,显得很明显。因此我们需要找到一种方法,来解决同步更新的网络瓶颈问题。其中最具代表性的一种方法就是:ring all-reduce。
Ring AllReduce
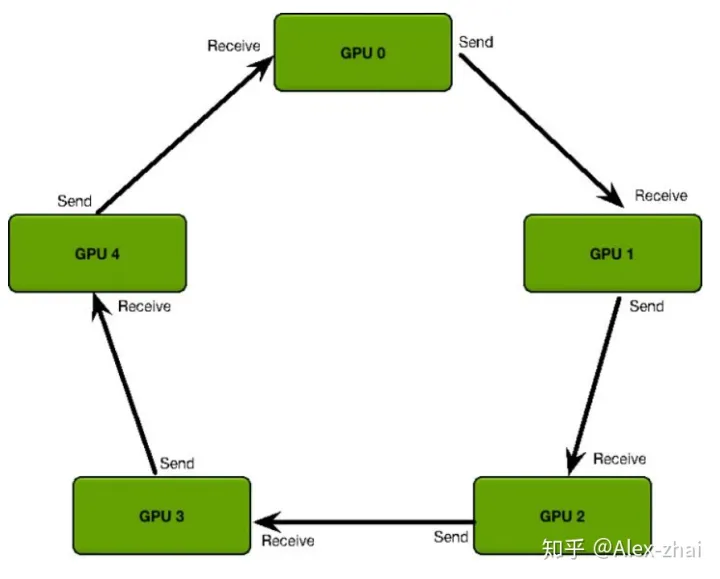
- 每个 GPU 只从左邻居接受数据、并发送数据给右邻居。
算法主要分两步:
scatter-reduce:会逐步交换彼此的梯度并融合,最后每个 GPU 都会包含完整融合梯度的一部分。即每一个GPU都会向下一个GPU发送梯度信息,下一个GPU会进行融合,再发给一下个,形成一个环。
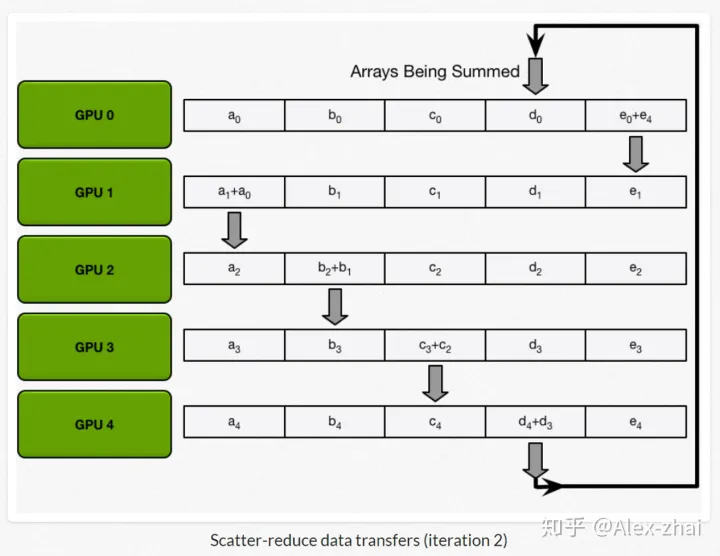
allgather:GPU会逐步交换彼此不完整的融合梯度,最后所有 GPU 都会得到完整的融合梯度。GPU传递已经融合梯度信息。
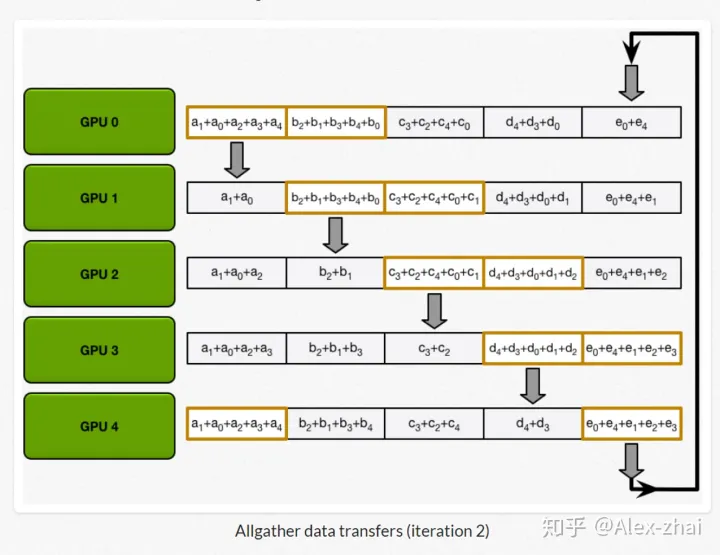
- 通信代价分析:每个 GPU 在Scatter Reduce 阶段,接收 N-1 次数据,N 是
GPU 数量;每个 GPU 在allgather 阶段,接收 N-1 次 数据;每个 GPU 每次发送
K/N 大小数据块,K 是总数据大小;所以,Data Transferred=2(N−1)*K/N ,随着
GPU 数量 N 增加,总传输量恒定。也就是理论上,随着gpu数量的增加,ring
all-reduce有线性加速能力。
- 每个2(N-1)步,每一步都要一次同步syncs
Model Parallel Training
- Intra Layer
- 每一个worker训练几个层
- Inter Layer
- 每一个worker训练层的一部分
Pipeline Parallel Training
Inter Layer Parallel
- 按行划分
- 按列划分
- 交替使用行列划分,可以减少通信次数
Summary
- Data Parallel
- Allreduce of weights
- Can be overlapped with computation
- Pipeline Parallel
- Point-wise communication of activations and activation gradients
- Hard to overlap with computation
- Hard to load-balance
- Intra-Layer Parallel
- Allgather,reduce scatter of activations and activation gradients
Others
- Memory Size for a Huge Model
- GPT3-175B
- Optimizer优化器:3259GB
- Activation激活,没有checkpoint:360GB
- Activation激活,有checkpoint:3.75GB
- GPT3-175B
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !